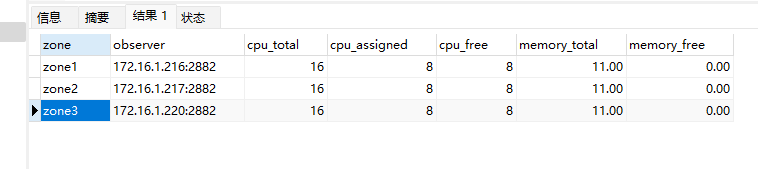
我们的业务场景下有一个日最大流水400w行的日志表,目前运行在CK上,总记录数大概在5亿左右,由于对中国厂商自研数据库的使用要求,我们正在考虑切换一个hatp的数据库。我前段时间通过白屏部署了一个三节点的oceanbanse,单节点规格8C 16G 一开始采用的最小模式。然后我进行了如下的DDL建表:
CREATE TABLE IF NOT EXISTS `sys_oper_log` (
`oper_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '日志主键',
`title` varchar(50) DEFAULT '' COMMENT '模块标题',
`business_type` int(2) DEFAULT '0' COMMENT '业务类型(0其它 1新增 2修改 3删除)',
`method` varchar(100) DEFAULT '' COMMENT '方法名称',
`request_method` varchar(10) DEFAULT '' COMMENT '请求方式',
`operator_type` int(1) DEFAULT '0' COMMENT '操作类别(0其它 1后台用户 2手机端用户)',
`oper_name` varchar(50) DEFAULT '' COMMENT '操作人员',
`dept_name` varchar(50) DEFAULT '' COMMENT '部门名称',
`oper_url` varchar(255) DEFAULT '' COMMENT '请求URL',
`oper_ip` varchar(50) DEFAULT '' COMMENT '主机地址',
`oper_location` varchar(255) DEFAULT '' COMMENT '操作地点',
`oper_param` varchar(2000) DEFAULT '' COMMENT '请求参数',
`json_result` varchar(2000) DEFAULT '' COMMENT '返回参数',
`status` int(1) DEFAULT '0' COMMENT '操作状态(0正常 1异常)',
`error_msg` varchar(2000) DEFAULT '' COMMENT '错误消息',
`oper_time` datetime DEFAULT NULL COMMENT '操作时间',
PRIMARY KEY (`oper_id`)
) partition by key(oper_id) partitions 9 ;
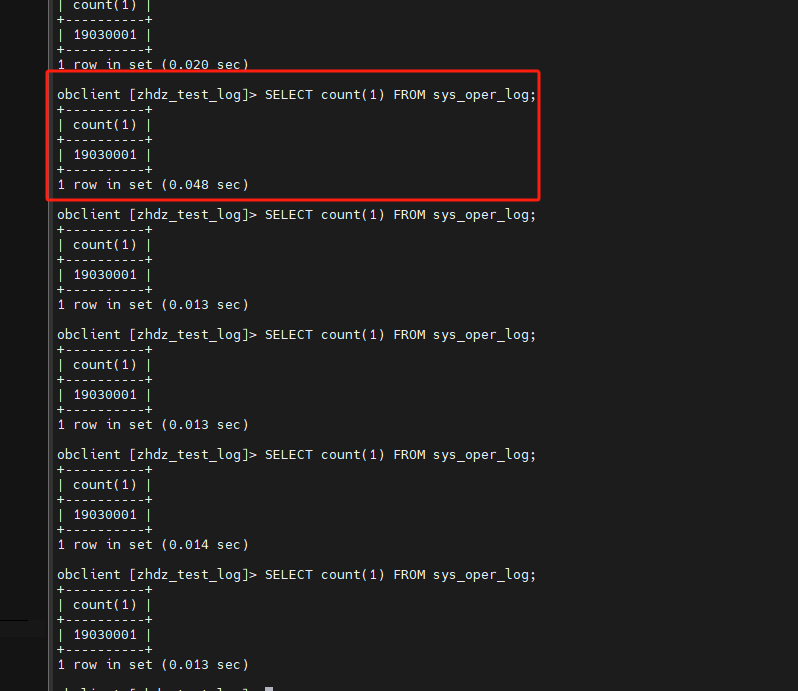
通过Navicat随机插入了约600w的测试数据,然后执行count计数
SELECT count(1) FROM sys_oper_log;
结果并不是那么让人满意,我同样尝试过不设置分区或者调整并行度,或者放开租户的资源限制
ALTER TABLE sys_oper_log PARALLEL 8;
但是最好的结果600w的计数仍然需要3-4秒以上的时间。而同样的数据在CK中我可以得到一个毫秒级的响应,因此我不确定是否是我的步骤哪里出现了问题。希望得到解答。
补充:距离我上次批量的数据模拟插入(600w数据10分钟批量插入,每次插入1000)过去了约20分钟,现在我执行计数可以得到一个毫秒级的响应了,在这过程中我三台机器的内存开销都比较高,似乎是后台正在执行合并的任务。我不知道自己的判断是否正确。如果是,那么有没有更多有关这个合并任务的描述,我想要知道如何能够查询到他何时开始,何时结束。