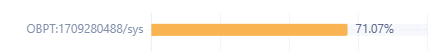
OCP的sys租户资源很吃紧呢 怎么处理呢
OCP的sys租户资源很吃紧呢 怎么处理呢
这是什么资源
可以先说明一下 OCP 元数据库集群和租户资源信息。
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free
, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024,2) mem_free_gb
, round(disk_total/1024/1024/1024) disk_total_gb, round((disk_total-disk_assigned)/1024/1024/1024) disk_free_gb
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port)
order by a.zone, a.svr_ip
;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu
, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb
, round(t2.max_disk_size/1024/1024/1024) max_disk_size , t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id
;
然后截图的时候建议截大图。
原先老架构的云平台sys都没红过,现在这个就一直爆红。
老架构我还一直跑的单机都没红
这一块资源我们都发了的在你同事那
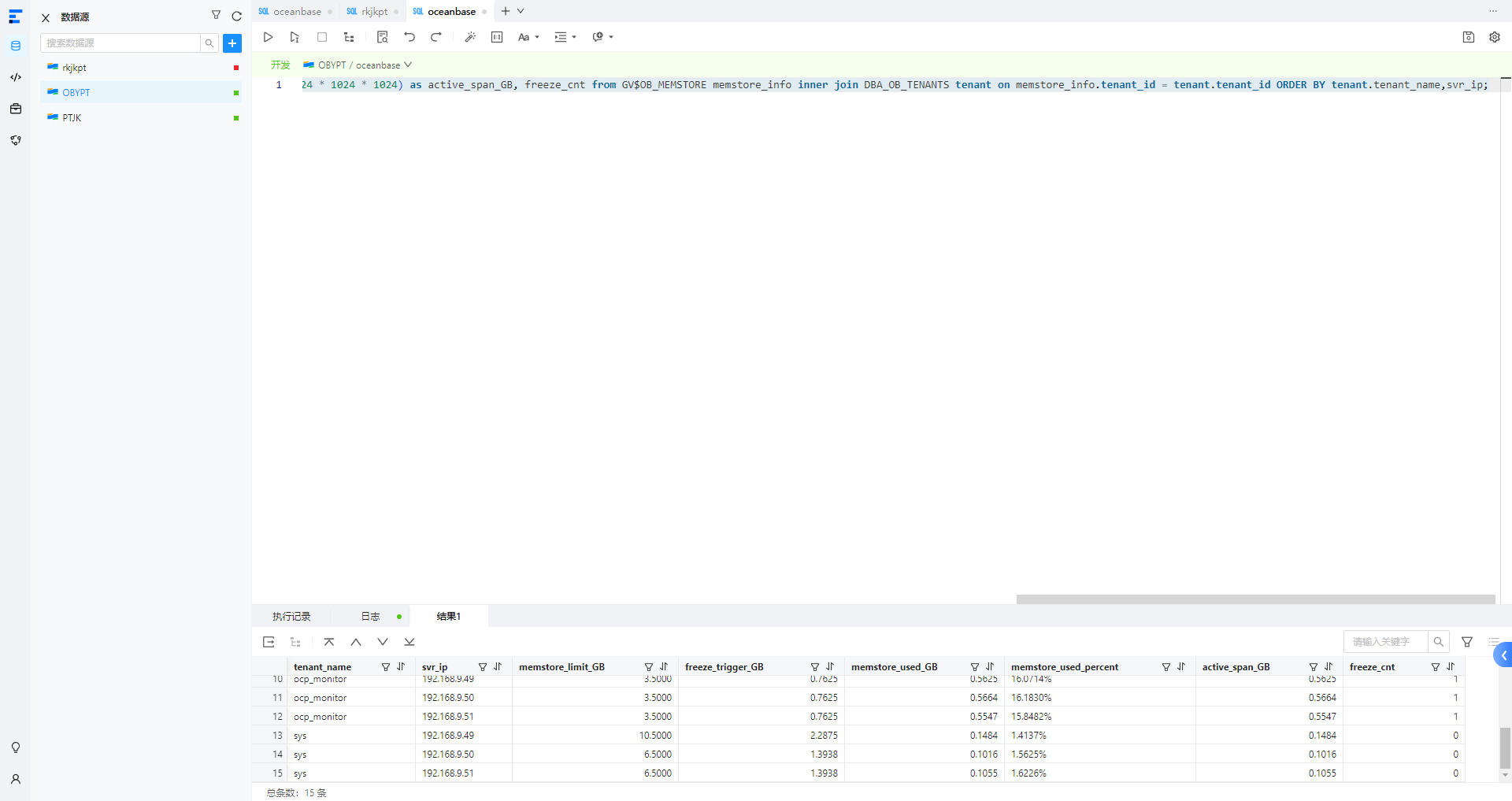
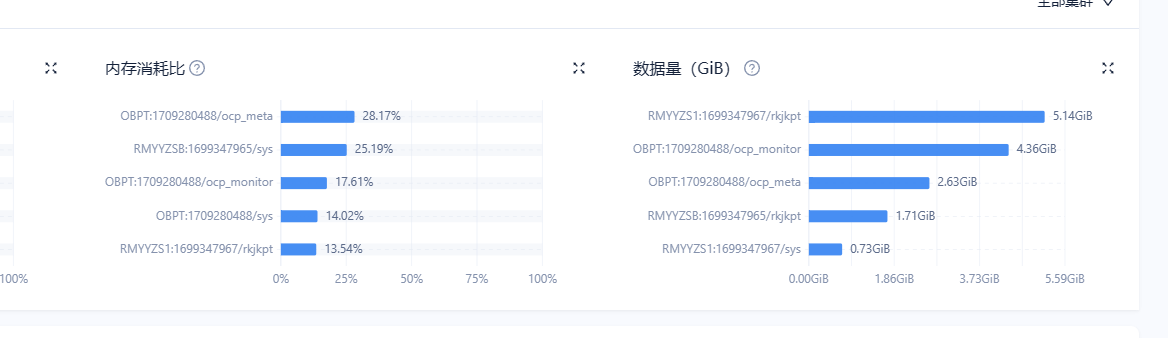
从图中视图看是 OB 4.x 集群,排除了企业版OCP 元数据库(OBV2.2)。推测是社区版 4.x 以后的 OCP express或 OCP。
从问题截图和描述推测你截图的是OCP 的【内存消耗比】(如果猜的不对还需要你截大图)
根据 OCP 图上对【内存消耗比】描述“已使用的内存占已分配内存大小的百分比” ,查找租户内存视图,推测这个逻辑是下面这个 SQL。可以发一下这个 SQL 结果。
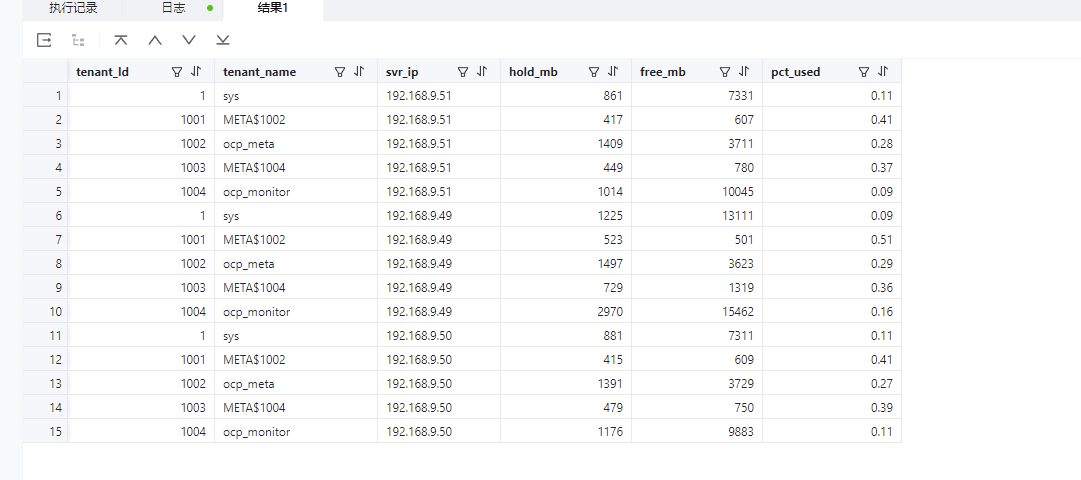
SELECT m.tenant_Id, t.tenant_name, m.svr_ip, round(HOLD/1024/1024) hold_mb, round(FREE/1024/1024) free_mb, round(HOLD/(HOLD+free),2) pct_used
FROM `GV$OB_TENANT_MEMORY` m JOIN DBA_OB_TENANTS t ON (m.tenant_id=t.tenant_Id)
;
| tenant_Id | tenant_name | svr_ip | hold_mb | free_mb | pct_used |
|---|---|---|---|---|---|
| 1 | sys | 10.0.0.63 | 2,123 | 4,021 | 0.35 |
| 1,001 | META$1002 | 10.0.0.63 | 889 | 135 | 0.87 |
| 1,002 | obmysql | 10.0.0.63 | 660 | 364 | 0.64 |
| 1,003 | META$1004 | 10.0.0.63 | 893 | 131 | 0.87 |
| 1,004 | oboracle | 10.0.0.63 | 927 | 97 | 0.9 |
这个是租户使用的内存包括 memstore 内存和另外一部分可伸缩的内存 kvcache。memstore内存可以转储反复使用,kvcache自己可以动态调整(只要没有sql报内存不足错误就没事)。
从截图看 租户内存每个unit 规格内存有6GB ,这个不少了够用.49上 sys租户的unit 内存扩容到 10GB 这个没有必要。
如果要对OCP 元数据库所在的 OB 集群“减负“,可以考虑下面操作:
enable_sql_audit, enable_perf_event
syslog_level
看下面这个图,可能是sys租户的内存不一致。50 51的memstore_limit 只有6.5G,可以先看下sys租户的资源配置。
好奇葩的问题 我把obd版本升了 显示爆红的那个问题直接好了
OCP那个带的obd版本还是2.4.1 我直接升2.6.2了 目前好像没红了
obd版本和ocp没有直接关系的。可以帮看下sys租户的内存几个节点是否一致。
那可能是已修复的版本缺陷,后续可以继续观察下。
你提供的这三个操作生产环境可以搞么? 关闭sql_audit 如何查询一些慢sql,日志设置为error,原厂都说可以设置,但ob出问题时日志打印的不全无法定位问题他们不负责,这你能改? ocp log_level参数修改这个 暂时没有遇到过。估计跟我说的第二个相似,真正出现问题的时候日志不全无法定位问题就惨了
生产环境 OCP 部署服务器要求内存在 256G 以上,什么都不用改也不要动,就什么事都没有。我的建议是针对问题里节点内存8G不到的环境。
另外,上面建议改的是OCP的元数据库。 OCP Express 部署的 OB 集群既存放自己的元数据库也存放业务数据,这个只是体验用的。
生产环境 OCP 的元数据库OB集群跟业务OB集群是分开部署的。OCP的元数据库跑的是 OCP 应用自身,相比业务应用而言,OCP的质量更高更稳定风险也更低。所以OCP的元数据库的一些日志没必要打那么多,关闭也是可以的。 退一步说,OCP元数据库如果死掉了,重新部署 OCP, 再把 业务OB集群接管回去即可。