【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】V4.2.1
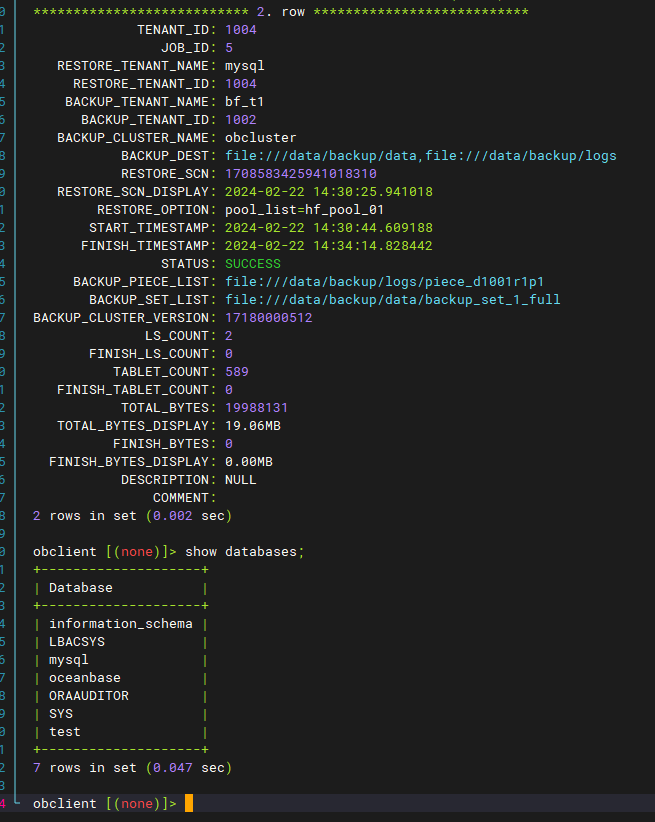
【问题描述】执行恢复数据操作时报未知异常
【复现路径】问题出现前后相关操作
【附件及日志】

id.log (6.2 KB)
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】V4.2.1
【问题描述】执行恢复数据操作时报未知异常
【复现路径】问题出现前后相关操作
【附件及日志】
id.log (6.2 KB)
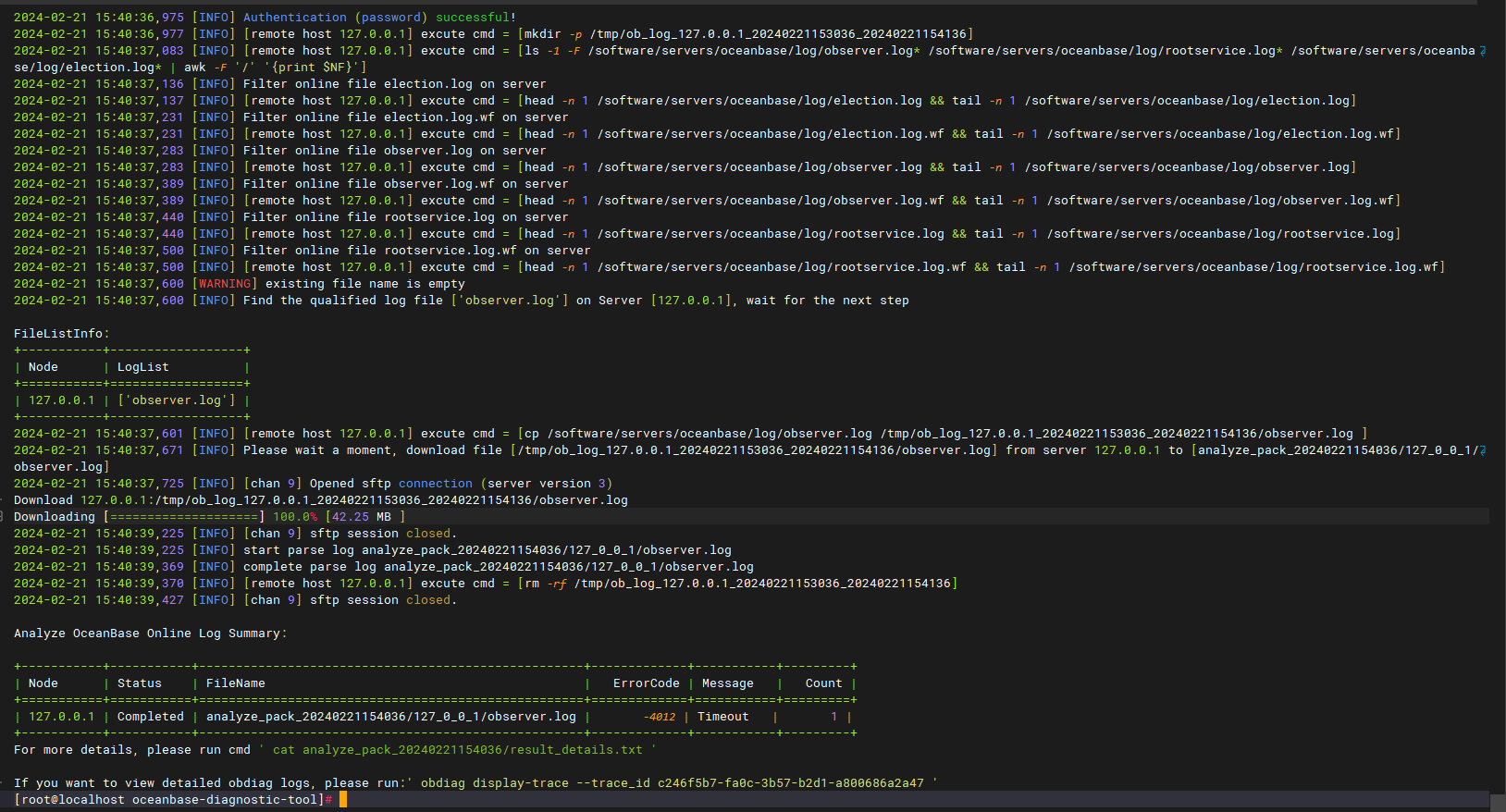
执行上述sql后,推荐用obdiag来分析一下日志,参考链接:OceanBase分布式数据库-海量数据 笔笔算数
obdiag analyze log --since 10m (分析最近10分钟的日志,找出可能的错误原因)
看上面日志分析的结果,只发现了其中有一个超时的日志。看起来不够定位问题。在执行一次sql语句,然后用obdiag 执行来收集一把恢复情况场景下的信息采集吧,然后将采集的问价夹打包发到这里来
obdiag gather scene run --scene=observer.recovery
两个疑问:
最开始的问题应该是资源不够 调整了资源
新问题是参考了https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000218383 这个文档操作的