

【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】V4.2.1 社区版
【问题描述】集群出现了如下第一张图所示的告警
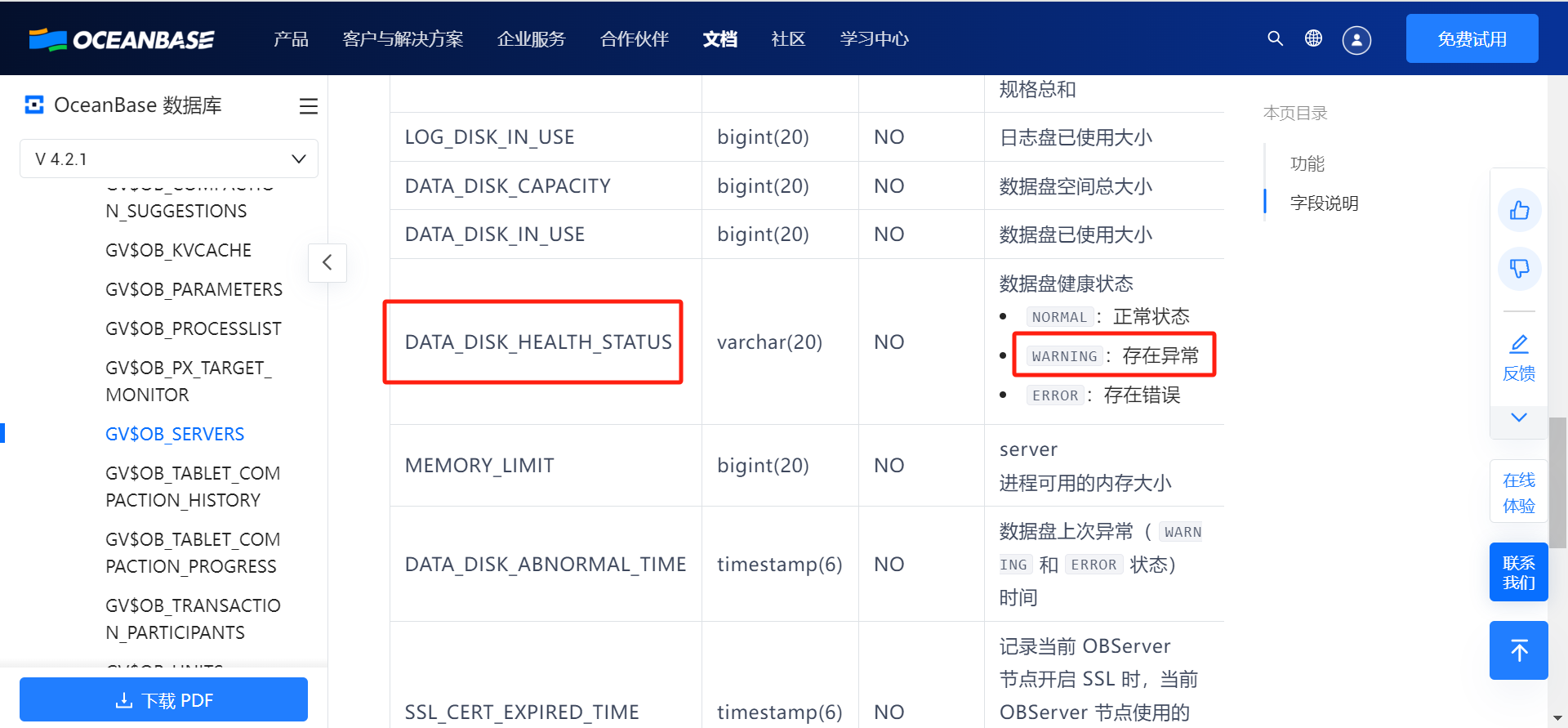
查看日志没有找到相关信息,
但是发现告警时的磁盘io和之前正常时相比确实有异常,有两段波峰
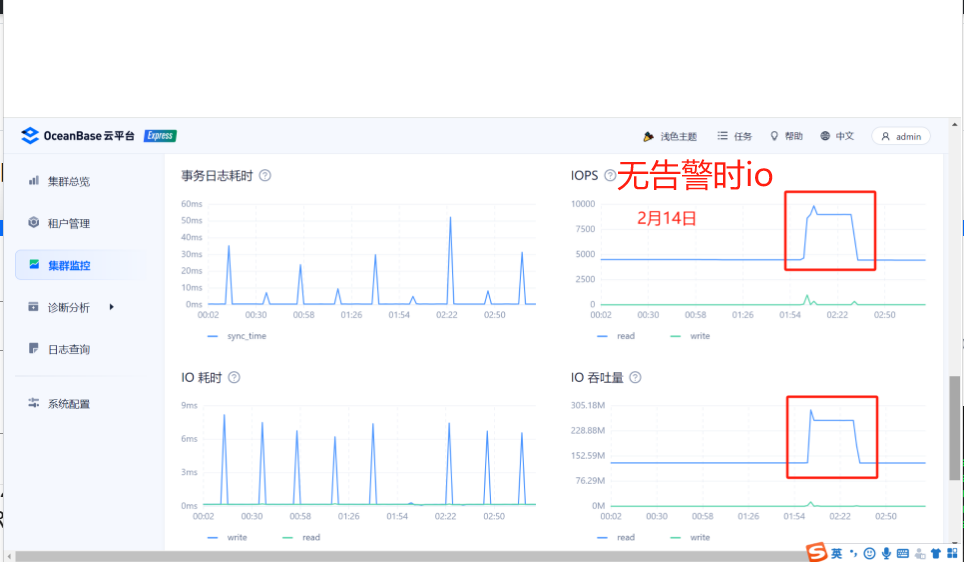
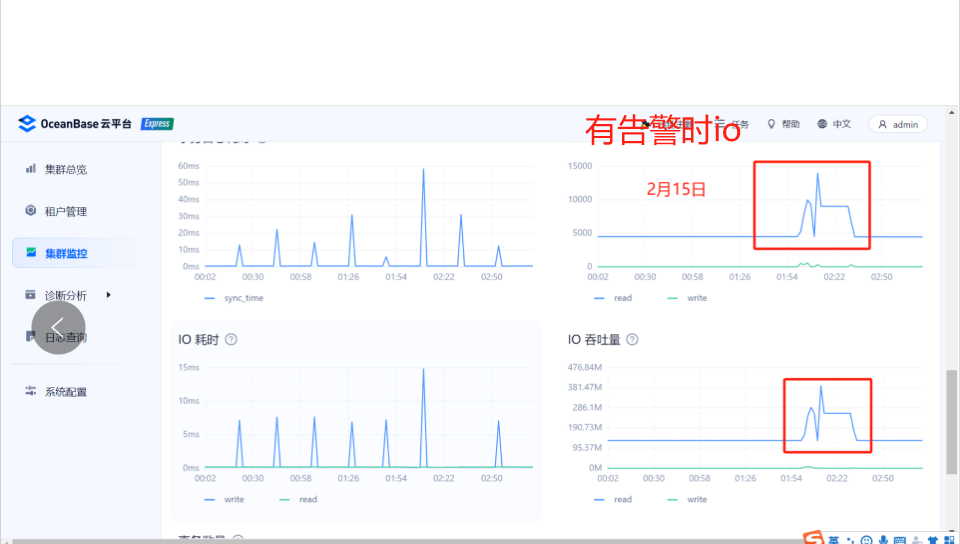
请问这个warning 状态是什么样的情况会出现warning告警,有没有关于这个更详细的介绍
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】V4.2.1 社区版
【问题描述】集群出现了如下第一张图所示的告警
查看日志没有找到相关信息,
但是发现告警时的磁盘io和之前正常时相比确实有异常,有两段波峰
请问这个warning 状态是什么样的情况会出现warning告警,有没有关于这个更详细的介绍
关于这个warning 状态,OceanBase官网目前没有更详细的介绍。但是你可以看看prometheus的node_exporter中关于磁盘的监控信息
是的,官网没有介绍,所以想问问咱们这边有没有办法能查到相关介绍,这个地方介绍的太模糊了,不知道因为啥导致warning
为保证 RTO < 8s,observer 内部会周期性读数据盘来判断数据盘是否正常。当数据盘超过 data_storage_warning_tolerance_time (默认 5s)读取失败时,数据盘会被设置成 WARNING 状态,当前 observer 上的 leader 会切走。当数据盘超过 data_storage_error_tolerance_time (默认 300s)读取失败,数据盘会被设置成 ERROR 状态,此时应该运维介入维修或者替换数据盘。故障排除后执行 alter system set disk valid server [=] ‘ip:port’; 清理故障状态。
谢谢,有没有别的情况会引起呢,我看有normal,warning,error三种状态,有没有详细的介绍哪些情况会是warning,哪些情况会是error呢
data_storage_error_tolerance_time
data_storage_warning_tolerance_time
配置项的介绍里有介绍,但没有视图状态到配置项的链接,后续文档同学会加一下。warning一般都是磁盘读写压力过大导致的抖动
好的,谢谢