

【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】oceanbase 4.2.1 社区版
【问题描述】清晰明确描述问题
oceanbase 测试环境两套集群,所有节点所在的linux 服务器总是会不定时重启,检查服务器并未发现报错问题,所以想请问下会不会是oceanbase 导致的 服务器频繁重启
有监控吗,看看有没有OOM。
也可以通过系统日志看看在/var/log/messages
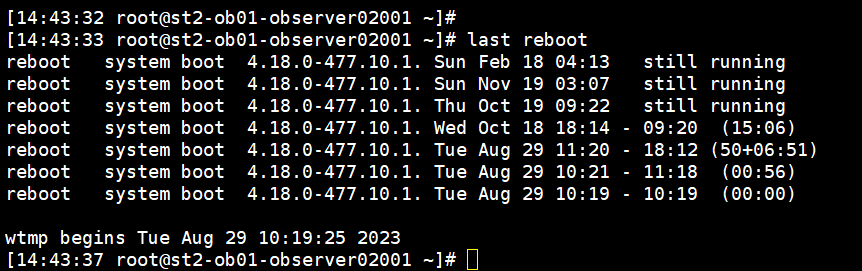
也有可能是由于某些指标异常导致管控平台重启了server,可以通过sudo last命令看看有没有reboot记录
我这好像也有一样的问题,想知道是什么情况
有监控,没有OOM,并且重启时各资源使用情况无明显波动,和平常一致,/var/log/messages 这个日志看过了,也从带外管理口看过了,没有报错信息,
sudo last reboot 这个命令也看过,是有reboot记录的,所以才怀疑是不是数据库因为某个原因重启了linux服务器
提供一下主机的/var/log/messages,以及使用命令“last reboot”查看系统重启日志,查找系统重启的时间和原因。
推荐使用obdiag来收集信息,OceanBase分布式数据库-海量数据 笔笔算数
obdiag gather sysstat 可以一键帮你收集对应集群所有节点的主机维度的信息,包括/var/log/messages, cpu,内存等
使用什么方式部署的ob集群,OBD还是ocp?按说observer是用户侧的东西,使用的时候不至于导致linux服务器重启。
这里提供一个排查observer日志的手段:
找到最近一次机器重启的时间点,用obdiag analyze log 去分析日志,如果有错误日志的分析结果,把分析结果发出来。OceanBase分布式数据库-海量数据 笔笔算数
比如发生挂掉的时间点是2024年2月18日 14:00,(安装好obdiag并配置好后) 执行如下命令来分析那个时间点的日志:
obdiag analyze log --from 2024-02-18 13:30:00 --to 2024-02-18 14:00:00
好的,我试试,我们是手工黑屏部署的,没有使用ODB,ocp等自动部署工具
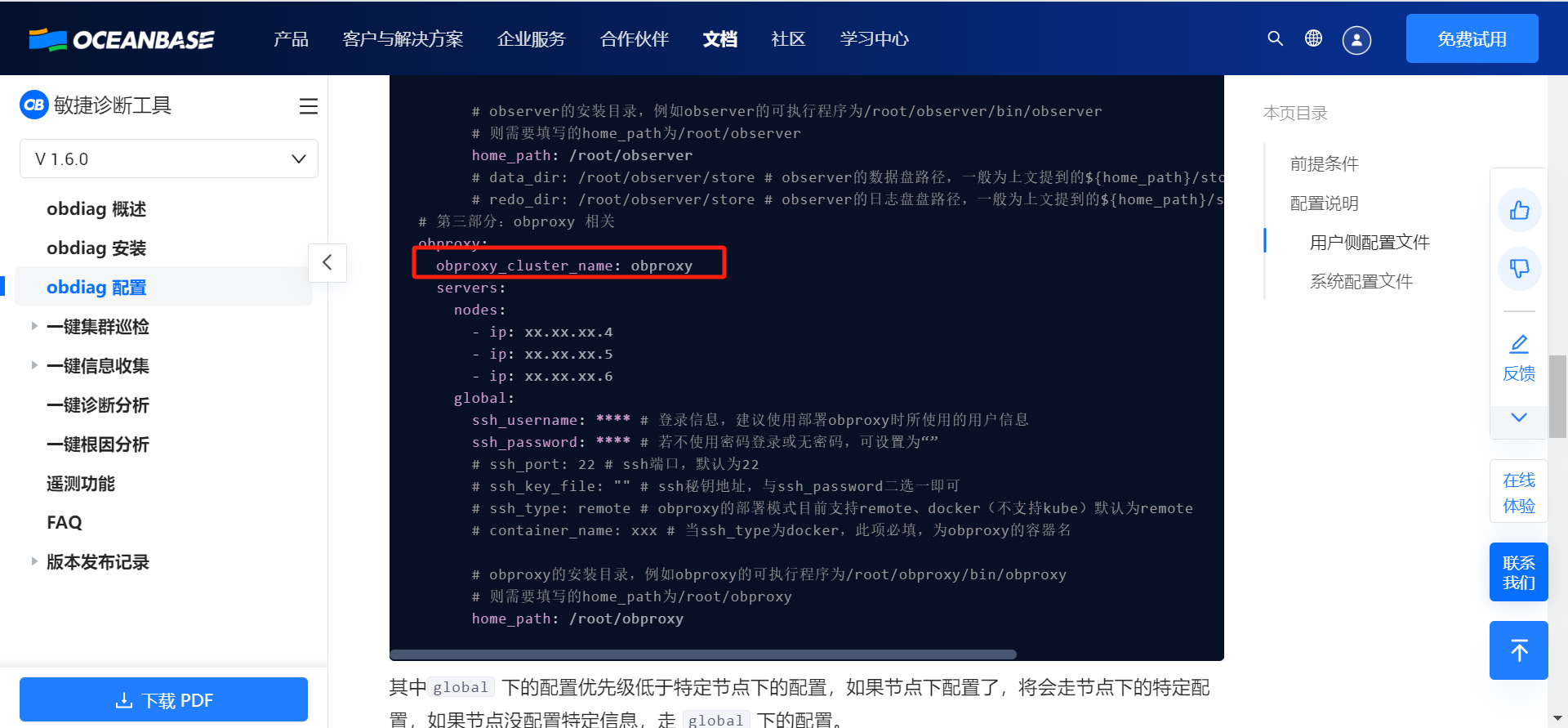
参考文档:OceanBase分布式数据库-海量数据 笔笔算数 obproxy这个不是必须要的,可以通过obdiag config -h <db_host> -u <sys_user> [-p password] [-P port] 来生成配置文件
看了下代码,没有看到直接调用reboot。observer应该不会主动触发reboot。
在你提供的系统日志中有看到每分钟都有定时任务执行,但在4点11分到4点13分之间没有定时任务的执行记录,或许可以这里面的定时任务。
如果所有的server的外部条件和内部配置都一样,但只有部署了ob的server会不定期重启的化,可能是磁盘在高负载的情况下出现了故障导致的重启,可以重这个方向查查看
另外我再日志有看到ocp agent的启动日志,这视乎是一套被ocp管理的集群,可以在看看ocp记录,是否有ocp层面发起的重启
好的谢谢
不客气,有更多的信息可以在同步到这个帖子。我们也会帮忙分析
好的
日志有多大呢
用obdiag 收集的,压缩后有180M,
试下压缩切分下呢?