

【 使用环境 】测试环境
【 OB or 其他组件 】ocp
【 使用版本 】4.2.1
【问题描述】ocp_monitor库,cpu、内存被打满,想知道怎么去查为什么会被打满
我查了,sql诊断,没有sql在执行
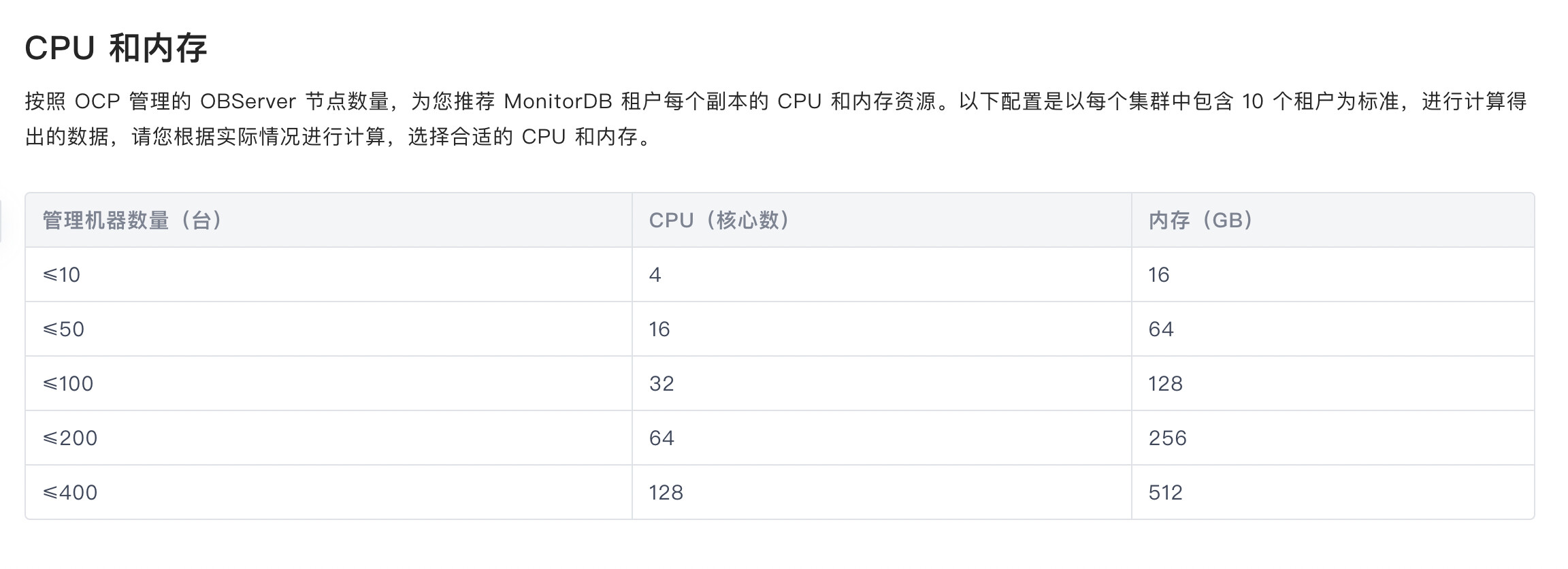
Monitor库本身是采集管理目标的各种性能数据的,我按照官方文档给了16c64g的资源
默认情况下ocp_agent是不会采集ocp_monitor的sql的,所以ocp_monitor库被打爆不能从SQL诊断中查ocp_monitor库的,大概率是业务租户流量高了,采集的业务租户的sql多,打爆了ocp_monitor数据库的cpu
租户现在都是新建的,还没有使用,我应该怎么去查什么原因呢,去看observer的日志吗
架构、机器配置、租户资源分配情况得发出来,还有相关的使用情况
推荐使用obdiag v 1.6.0 捞一下monitordb集群的信息,方便我们进一步定位。
https://www.oceanbase.com/docs/common-obdiag-cn-1000000000564055
# cpu高场景
obdiag gather scene run --scene=observer.cpu_high
# 未能明确问题的场景
obdiag gather scene run --scene=observer.unknown
11个集群,每个集群最多11个租户,资源是给够了的
会不会和,现在有租户是偶数个副本有关
11个集群,每个集群有多少节点
5节点
monitor租户现在是2个zone,会不会和这个有关
和是否是偶数副本没关系,还是得看ocp上托管的业务集群、机器数量,另外刚也提到过,业务流量大的话也会导致ocp monitordb的资源消耗过大,应为会采集业务集群的sql执行的数据
我看你上面提到有11个集群,是每个集群都是5节点,总计55个节点?
对,打算扩一下monitor看看有没有改善,现在ocp创建租户变的很慢,一个任务要执行很久
现在应该没有业务流量啊,租户刚新建的
55个节点,再加上这么多租户,这个ocp monitordb的资源有点吃紧。业务集群有没有在搞迁移的
另外有个排查思路:查询monitordb的sql采集数据,确定是否业务有数据激增,以及那张表的数据量比较大
select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_stat_0 partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_audit_sample partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_sqltext partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_sqltext partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_sqltext partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_stat_0 partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_stat_0 partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_stat_0 partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_explain partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_explain partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan_explain partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_plan_cache_plan partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_plan_monitor partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_plan_monitor partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_sql_plan_monitor partition(P20240207) group by cluster_name;
select cluster_name,count(1) from ob_hist_trans_stat partition(P20240205) group by cluster_name;
select cluster_name,count(1) from ob_hist_trans_stat partition(P20240206) group by cluster_name;
select cluster_name,count(1) from ob_hist_trans_stat partition(P20240207) group by cluster_name;
先别着急扩资源,先查查原因。