【 使用环境 】测试环境
【 OB or 其他组件 】OB三节点集群方式
【 使用版本 】4.2.1
【问题描述】在官方文档中看到可以非分区表执行并行查询:OceanBase分布式数据库-海量数据 笔笔算数
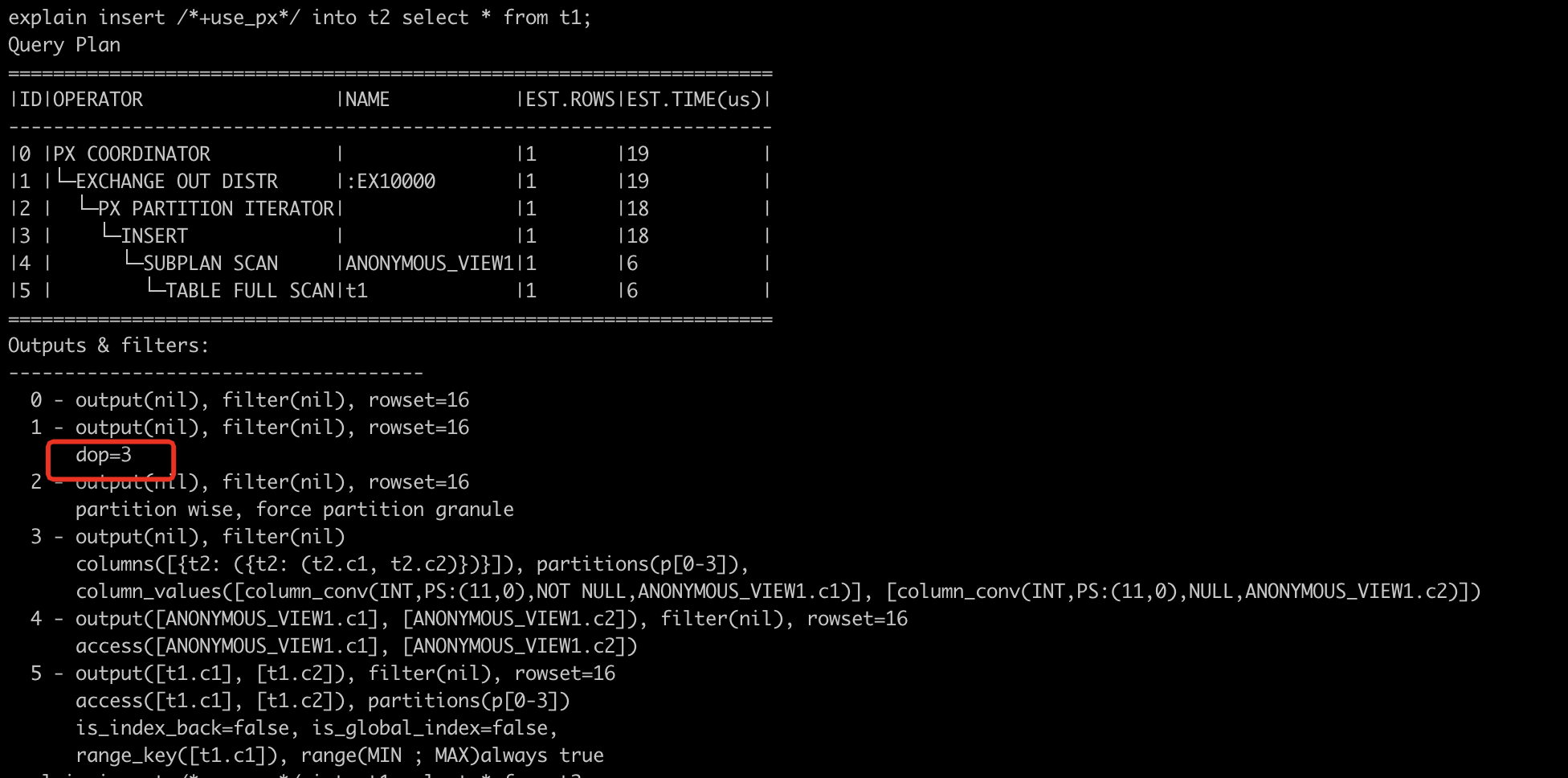
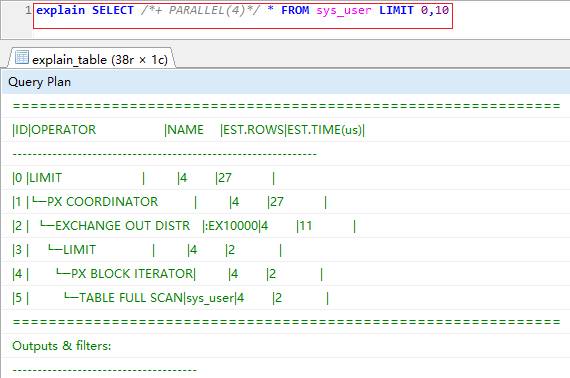
并且在测试环境执行explain,确实是可以并行查询,图片如下

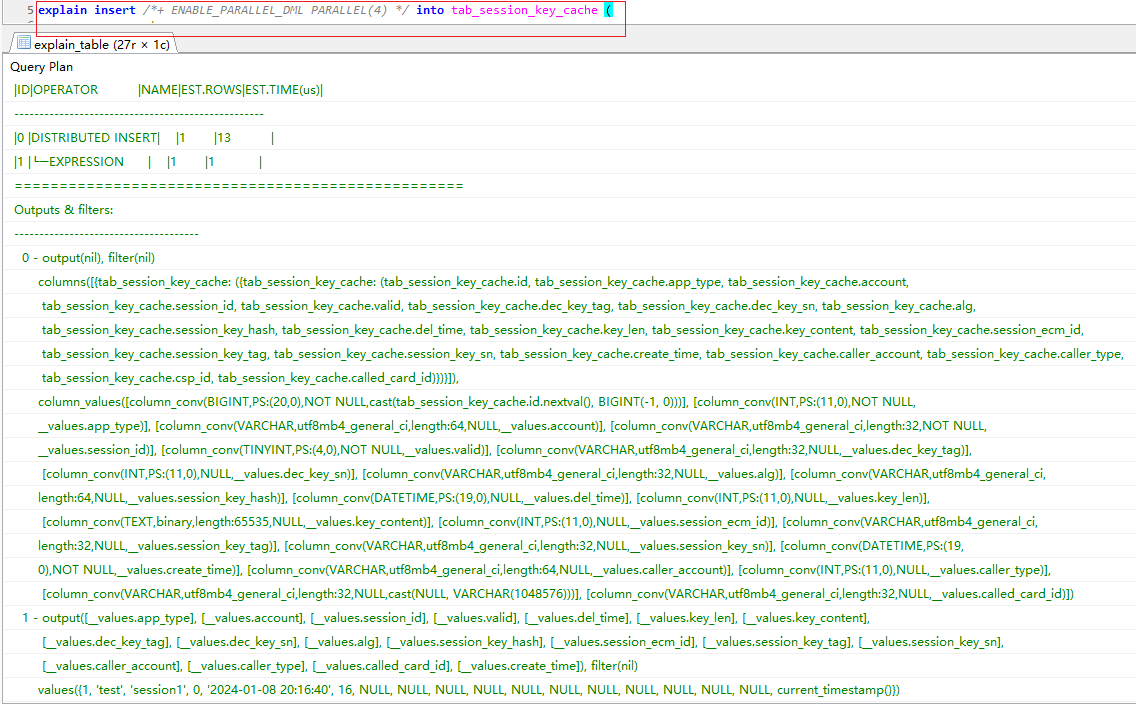
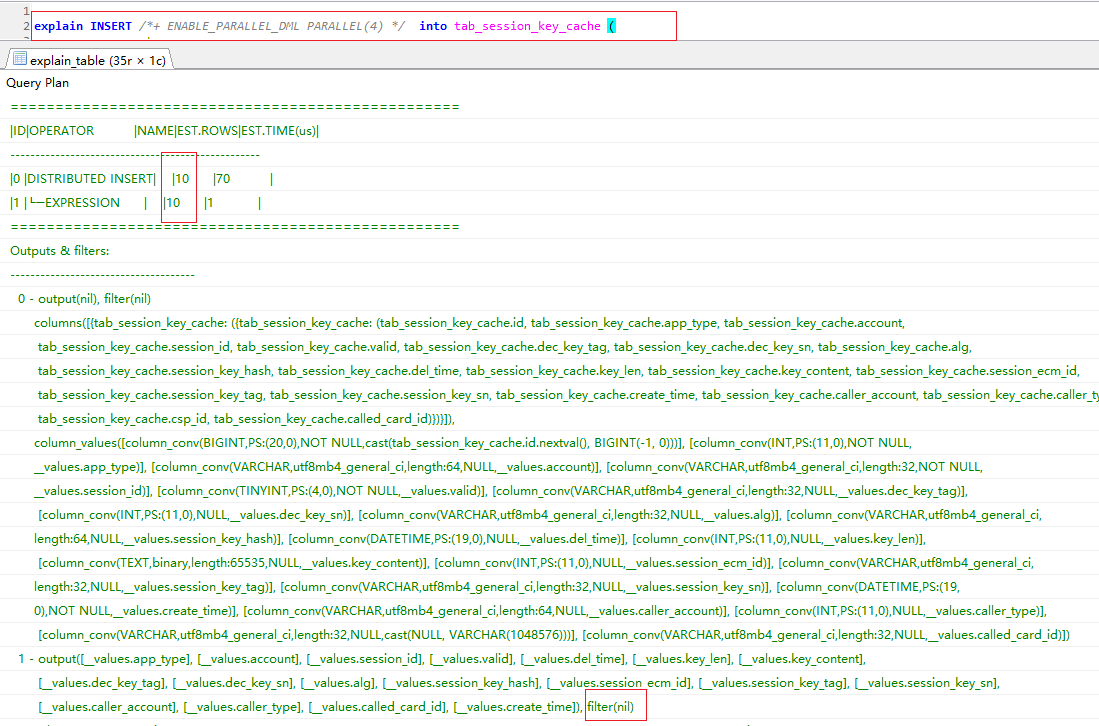
但是现在想执行非分区表的并行DML(新增、更新、查询),以新增为例:
OceanBase分布式数据库-海量数据 笔笔算数
但是执行explain,发现并行没有生效,请问这是什么情况呢?
【 使用环境 】测试环境
【 OB or 其他组件 】OB三节点集群方式
【 使用版本 】4.2.1
【问题描述】在官方文档中看到可以非分区表执行并行查询:OceanBase分布式数据库-海量数据 笔笔算数
并且在测试环境执行explain,确实是可以并行查询,图片如下
个人的直观感受是,如果通过 dml 处理一批数据,例如通过 update 更新十万行数据,可能还用的到多线程并行处理,每个线程处理一批数据。
但是您这个是通过 insert 插入 1 行数据,只处理 1 行数据的话,就无法利用到 4 个线程了。即使强行派 4 个线程过去干活儿,也一定会有 3 个线程在偷懒,所以它就直接派这 1 个线程来处理这仅有的 1 行数据了。
如果想充分利用线程资源。可以尝试通过一条 insert 插入更多行的数据,或者直接 insert into select 插入一批数据。
好的,我用大量数据试下。
还有个问题想请教下,你说的“并行处理带来的性能提升还没调度这么多线程带来的性能回退大”,意思采用并行方式不如单线程性能高是吗?如果是的话,那么采用分布式数据库增删改查操作(通过并行方式实现)的多节点集群方式的性能不如采用单节点集群方式(不使用并行方式),您看我这种说法是不是对的呀
不是对的。
我说的是“部分场景”采用并行方式可能还不如单线程的性能高,比如你这个数据量极小的场景。详见这篇博客:OceanBase 社区
还有就是并行执行和单机、分布式不是强关联的,单机也可以有并行执行,所以你后面说的单节点集群性能比多节点集群的性能好的结论也是不成立的~
好的,非常感谢,这个问题经过您的指点已经很清晰了。
还有一个关于性能的问题想请教下,我分别建立了单节点集群和多节点集群用于测试mysql和ob的性能(并发约50,循环200次,共计10000个样本,使用jmeter压力测试工具):
(1)单节点集群时:单表的插入、新增、查询mysql均优于ob
(2)多节点集群时:同(1),并且多节点时的ob性能不及单节点ob
总的看起来ob不及mysql,并且单节点ob比多节点ob性能更好,若加入并行,ob性能会变差,您看还有没有其他的方式可以优化ob,使得ob性能变好呢,甚至超越mysql
多节点的你要测大数据量,高并发,才能测出来性能,并发低数据量小,多节点协调消耗的时间可能都比单节点高
OB 在高并发场景下的压测性能会更好,并行执行在数据量较大的场景下压测性能会更好。
压测问题详见官网文档:OceanBase分布式数据库-海量数据 笔笔算数
这里推荐试用一个叫 obdiag 的工具进行压测前的巡检,详见:OceanBase 社区