

【 使用环境 】生产环境
【 OB or 其他组件 】OB,三台服务器集群
【 使用版本 】4.2.0
【问题描述】我们加工抽取表。一个主表3000w,带索引,一个关联表第主键和主表做关联。关联表1.7亿条(4个字符字段),加工抽取到一个带月份分区的表24个分区,抽取时间8个小时。这个时间有些长。三节点ob部署,物理机。48核,256G内存。
【复现路径】采取手段:按照在线的修改了并行参数,IO参数,内存比例等参数。
【附件及日志】内网环境,日志怎么查看
- 先通过 OceanBase.gv$sql_audit 定位到这条抽数 SQL,发一下记录内容,这样大家能看到很多具体的性能指标值。
- 大表抽取想要快,就充分使用并行技术。 SQL 里可以用并行 是一种方法。客户端自己并发多个线程分段抽取也是一个办法。可以看看 DataX 这个产品 或者 obdumper 的使用实践。
- 并行抽取后,观察租户、集群节点的 CPU、IO 利用率,没有到达瓶颈的话,说明并行还有提升空间。
2 个赞
2、并行技术有哪些参数能调整的?我们有个平台抽取时,至少100个线程在跑。不用平台,直接在obclient>状态下,和用平台一样的时间。从时间结果上,3000W记录关联需要多久?我们应用场景是是加工抽数。DataX能做ETL吗?
3、CPU和IO利用率一直不高。
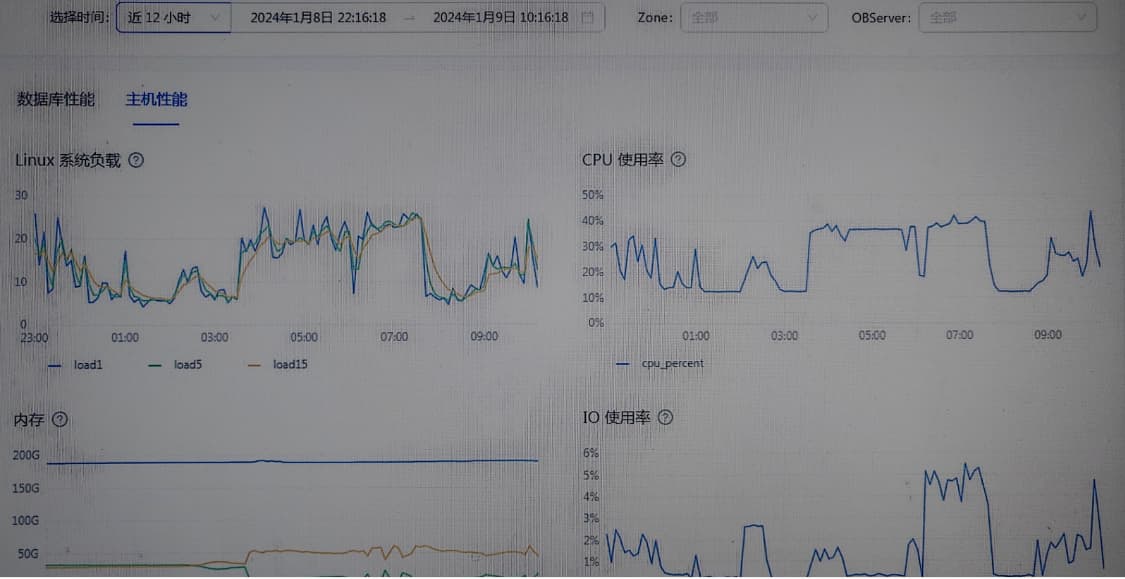
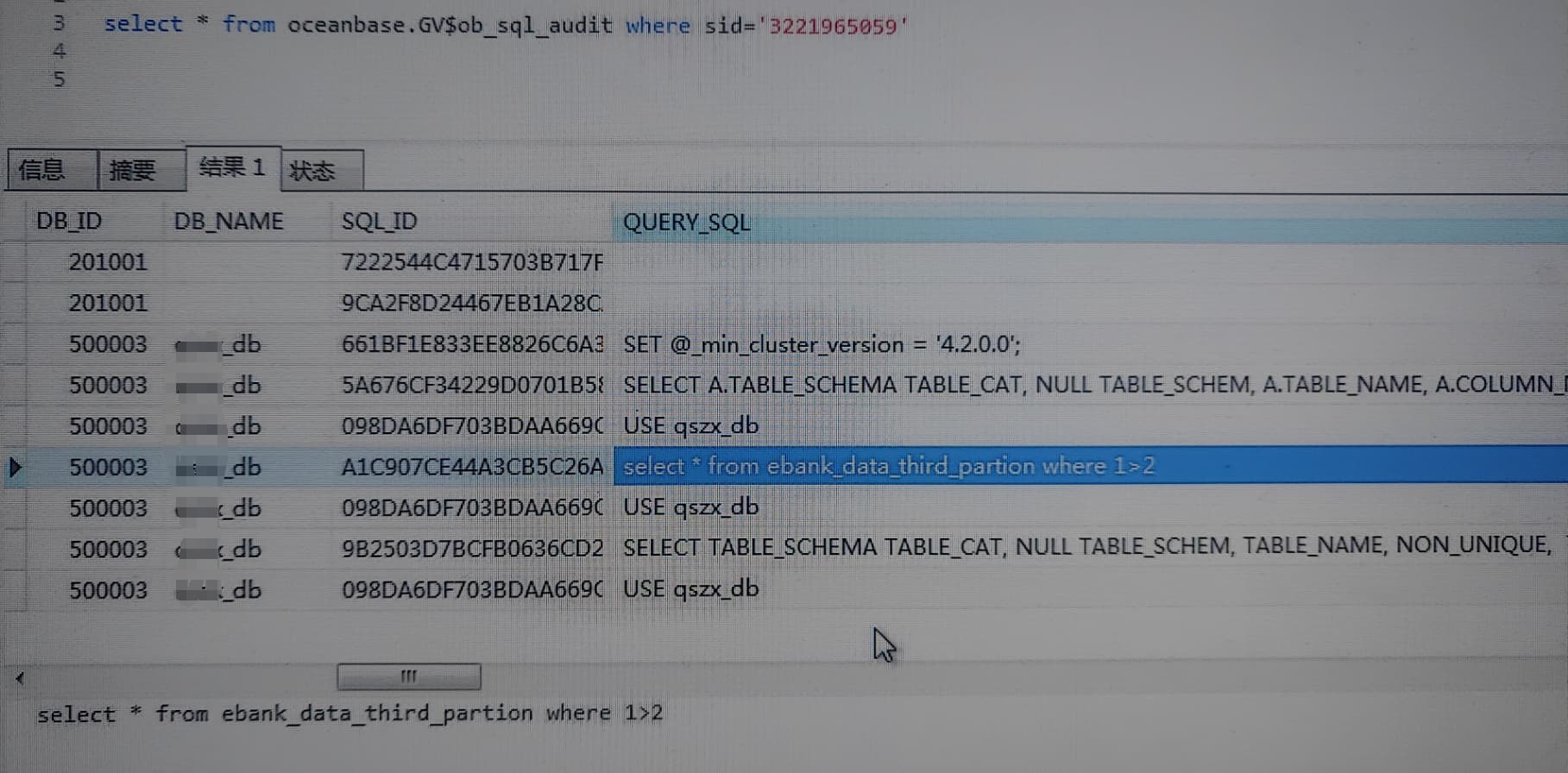
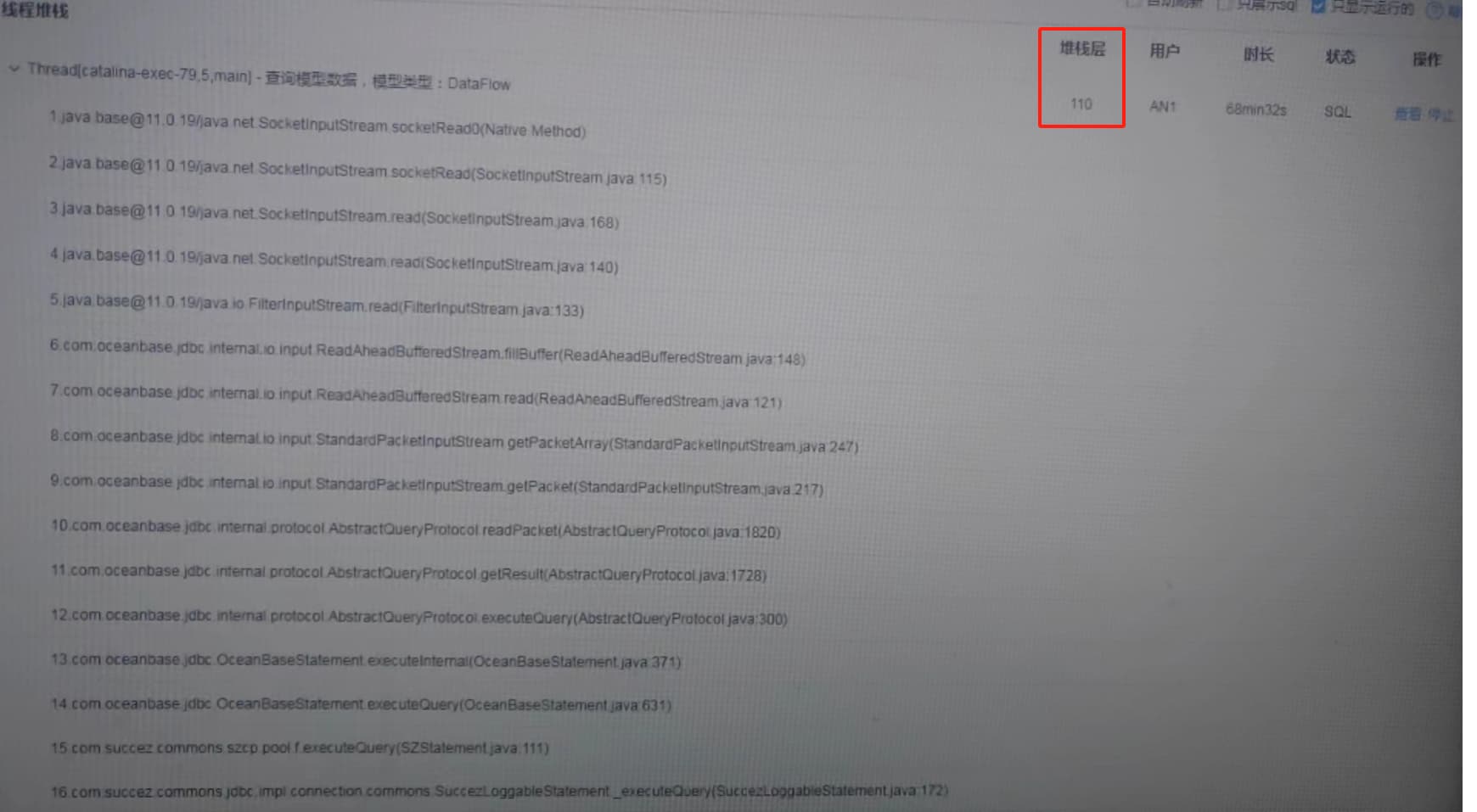
4.2.1有没有并行参数的优化调整建议?
这些参数都要调整吗?有没有根据哪些实际值,建议改为参考值?
我这里没有安装OMS,怎么用?这个优化是思路是必须要安装OMS吗?
我这边回复的是OMS的优化方法,如果没有使用OMS则不用看,使用其他工具建议到工具的官网上寻求帮助
没有使用OMS,请问oms可以实现部分关联表处理吗?我们可以安装
OMS不支持这种场景
收到,那么怎么优化呢?其他的思路呢?