gv$ob_sql_audit 中几个指标不是很明白
1、几个等待时间的疑问?
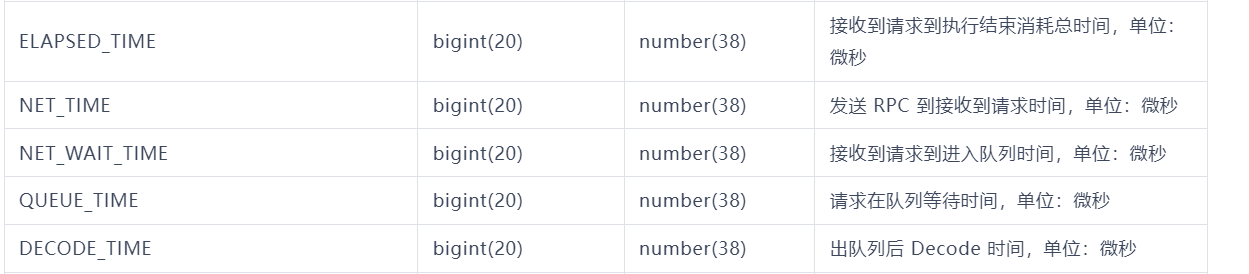
(1) NET_TIME:这个指的是当前实例上SQL在另外实例上远程计划时的时间吗? 从本实例发出RPC后到对端ob server对rpc请求返回的一个回应间的时间(此时远端还未进入租户队列)?
(2) NET_WAIT_TIME: 本实例作为远程计划的执行实例时从接收到RPC请求后到进入租户队列间的等待时间?这部分时间长主要原因是什么?
(3) DECODE_TIME: decode是个什么动作?
2、 关于等待事件时间的描述
这里的当前等待事件、所有等待指的是什么? 例如 一个SQL执行请求记录到sql_audit后物理他是何种类型的执行计划在初始的Observer是否是只会记录一条记录? 如果只有一条记录,他在执行过程中会经历很多个等待,是每次等待时都会把sql_audit中当前等待事件和 wait_time_micro都update 然后将总时间累加到total_wait_time_micro??
3、行锁的queue也是使用租户的请求队列吗?不通过lock表判断如何区分是行锁排队?
靖顺
#4
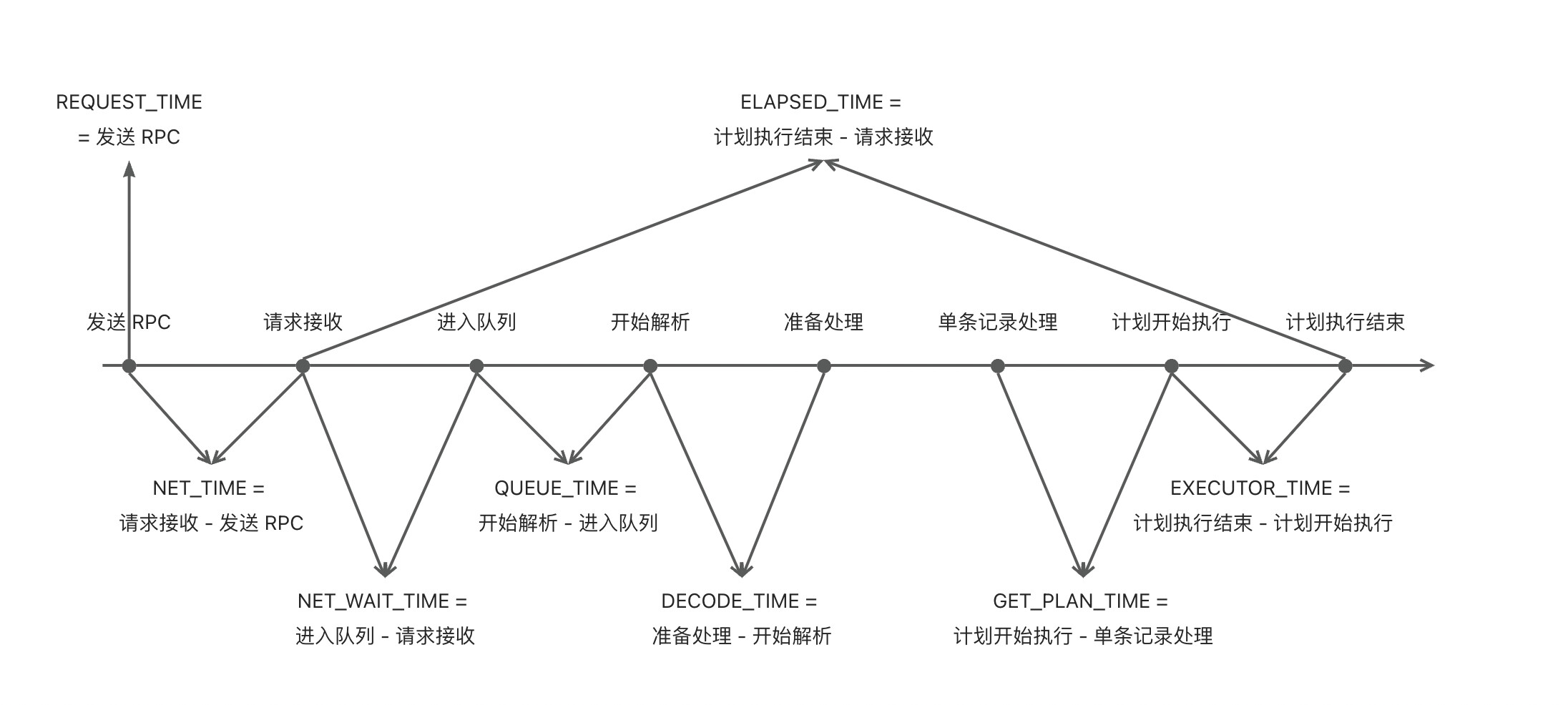
sql_audit中几个时间维度的可以看下这张图:
1 个赞
靖顺
#5
依次回复一下你的问题:
1(1) net_time是请求接收 - RPC发送的时间,此时还没到进入队列的阶段;
(2)net_time_wait是进入队列 - 请求接收这一段时间;
(3)decode是SQL的解析过程;
- 这里的当前等待事件对应的是和下面这几个字段对应的
所有等待指的是在执行过程中所有的等待的一个sum值;一个SQL执行请求记录到sql_audit是不止一条记录的, 以下情况会单独记录一个sql audit记录:
1. 接收用户请求的处理线程;
2.用户SQL触发的内部SQL执行(is_inner_sql = true)
3.远程执行(is_executor_rpc= true)
4.每个PX工作线程执行(is_executor = true)
- 行锁的queue和租户的请求队列并不是一回事,不过队列等待时间这个指标上是包括了行锁的等待时间的。不通过lock表的话还可以结合sql_audit中的event字段来判断,不过建议是通过lock表去判断会更直接一点
1、 还有有疑问,sql_audit记录的用户申请了无非2种 is_executor_rpc=0 或1 ,假如一个SQL执行需要本地扫描一个分区、远端扫描一个分区,对于远端的扫描发送rpc后 是不是就处于等待远端返回的状态,按途中的表示 位置1 是本地的执行,位置2 及以后是远端的执行,那么远端执行的相应时间会累积到本地的sql audit记录里吗? 如果是远端解释到rpc后完成2及之后的动作给本地发送rpc,如果是这样的话这个图的顺序看起来又不太对?
2、 关于当前等待事件,假如一个sql语句只在本地执行,他可能经历了多个latch事件、IO事件,在sqlaudit钟只有一条记录,是不是每次等待事件发生变化时更新audit记录的event相关字段?
靖顺
#8
一、有两点需要说明一下:1. 一条请求并不是只有一条sql_audit记录,远程执行的请求在远程机器上也会生成sql_audit记录,他们之间通过trace_id进行关联;2. sql_audit的记录是只有执行完(成功或者失败)才会记录,执行过程中是不记录的;
所以这张图并不是你所说的1是本地,2以后是远程。这张图是相对于一条sql_audit来说的,从发起请求到结束请求完整的时间记录。
二、event字段是记录最长等待事件,所以我上面的回复中说到可以结合sql_audit中的event字段来判断行锁等待,不过建议是通过lock表去判断会更直接一点,就是因为event并不是全部都会记录,是记录最长的等待事件。
如果是个本地执行计划,就读了一条数据,那这个发送RPC是谁发起的?
也就是说 sql_audit里执行完后这一条记录就不会变化了 ,那这个字段应该叫 最长等待事件 合适,而不是当前等待事件。
靖顺
#10
你的疑惑是对的,我这张图应该纠正一下,request_time 并不等于rpc发起的时刻,准确的说是发生了远程执行的这两者是相等的,如果单纯的本地执行的话是没有RPC发起的。