(1)SUBPLAN SCAN 与SUBPLAN FILTER 算子分别会在什么情况下生成?
当读视图中的内容时,执行计划中会分配 subplan scan 算子;类似地,读实体表就会分配 table scan 算子。
SQL 在优化器里首先会被改写,如果改写之后还是一个子查询,那么就会生成 SUBPLAN FILTER 算子,用于驱动子查询的计算;如果非相关子查询被改写成了等价的 JOIN,就不会生成 SUBPLAN FILTER 算子了。
(2)SUBPLAN SCAN 与SUBPLAN FILTER 算子的区别是什么?
SUBPLAN FILTER 的算子功能是驱动表达式中的子查询执行,以 nested-loop 算法执行去 subplan filter 算子。如果是相关子查询,执行时每从左边取一行数据,然后就会执行一遍右边的子计划;如果是非相关子查询,还是从左边逐行取数据,不过右边的子计划实际只会算一次。
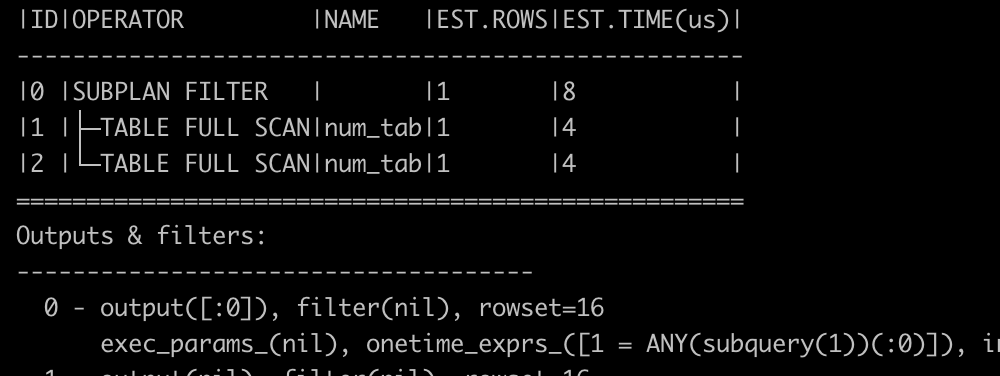
以你给出的 SQL 为例,如果不让优化器进行改写,就是个非相关子查询,1 in(select c1 from num_tab) 只需要执行一次,计划里可以通过 onetime_exprs_ 看到。
explain select /*+ NO_REWRITE*/ * from num_tab where 1 in(select c1 from num_tab);
+------------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |SUBPLAN FILTER | |2 |8 | |
| |1 |├─TABLE FULL SCAN|num_tab|2 |4 | |
| |2 |└─TABLE FULL SCAN|num_tab|2 |4 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([num_tab.c1]), filter(nil), rowset=16 |
| exec_params_(nil), onetime_exprs_([1 = ANY(subquery(1))(:0)]), init_plan_idxs_(nil), use_batch=false |
| 1 - output([num_tab.c1]), filter(nil), startup_filter([:0]), rowset=16 |
| access([num_tab.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([num_tab.__pk_increment]), range(MIN ; MAX)always true |
| 2 - output([num_tab.c1]), filter(nil), rowset=16 |
| access([num_tab.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([num_tab.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------------------------------+
19 rows in set (0.008 sec)
subplan scan 算子类似于 table scan 算子, 但不从基表读取数据,而是读取孩子节点的输出数据。
继续以你给出的计划为例,这时候不加 NO_REWRITE 的 hint,优化器就会把这条 SQL 改写成等价的其他 SQL,执行时非关联子查询就变成了等价的 nest loop join,join 的左支是 num_tab.c1,右支是一个视图 VIEW1,视图结果被物化了下来。
根据 4 号算子来看,这个视图的定义应该是 create view VIEW1 as select 1 from num_tab where num_tab.c1 = 1。因为右支要从视图读数据,所以就会生成 SUBPLAN SCAN 算子。
explain select * from num_tab where 1 in(select c1 from num_tab);
+-----------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------+
| ============================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | |1 |8 | |
| |1 |├─TABLE FULL SCAN |num_tab|1 |4 | |
| |2 |└─MATERIAL | |1 |4 | |
| |3 | └─SUBPLAN SCAN |VIEW1 |1 |4 | |
| |4 | └─TABLE FULL SCAN |num_tab|1 |4 | |
| ============================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([num_tab.c1]), filter(nil), rowset=16 |
| conds(nil), nl_params_(nil), use_batch=false |
| 1 - output([num_tab.c1]), filter(nil), rowset=16 |
| access([num_tab.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([num_tab.__pk_increment]), range(MIN ; MAX)always true |
| 2 - output(nil), filter(nil), rowset=16 |
| 3 - output(nil), filter(nil), rowset=16 |
| access(nil) |
| 4 - output([1]), filter([num_tab.c1 = 1]), rowset=16 |
| access([num_tab.c1]), partitions(p0) |
| limit(1), offset(nil), is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([num_tab.__pk_increment]), range(MIN ; MAX)always true |
+-----------------------------------------------------------------------------------------------------------+
24 rows in set (0.095 sec)
推荐直接在官网上查下这两个关键字:
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000220931
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000220942