cms
好的,了解了,感谢解答!最后再确认下如果大事务导致的话相当于并不是数据同步真正有延迟,而是因为位点提交有延时所以导致从管理端看到是有延迟的假象?


可以在writer的配置source中添加
useSchemaCache=true
useBetaListener=true
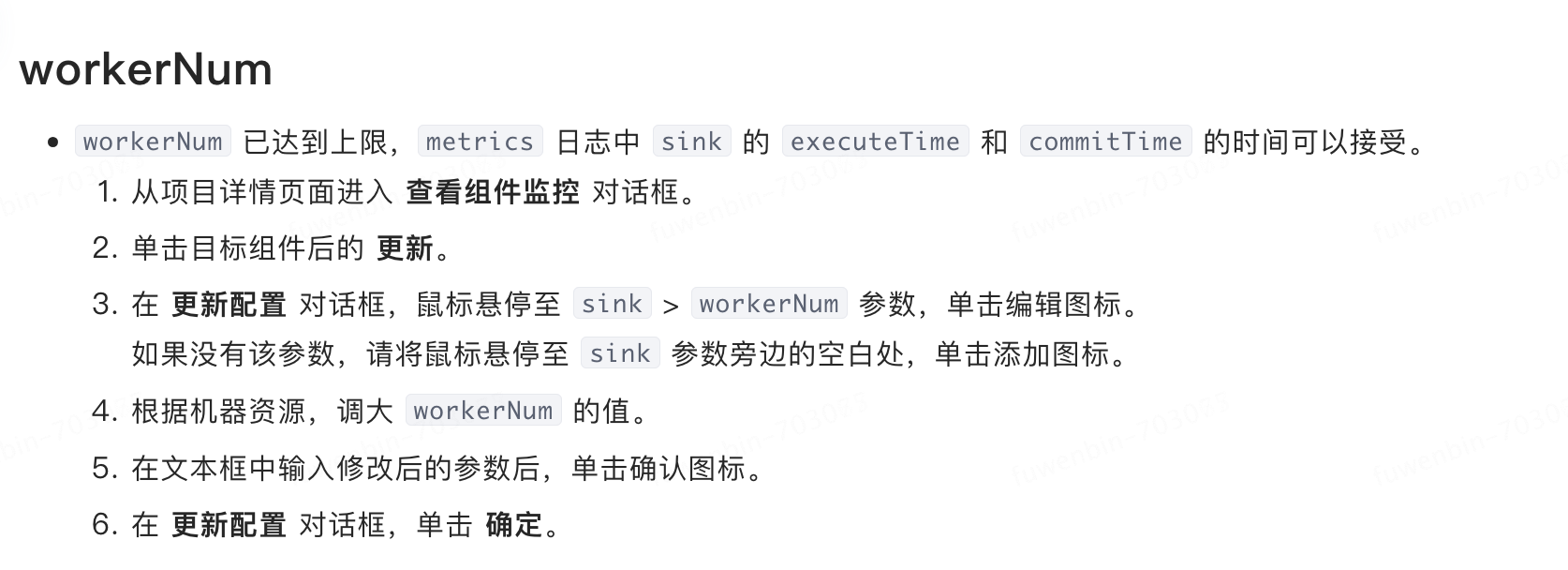
ready_execute_batch_size为0,应该是瓶颈不在wokernum上,瓶颈一般是在读取

- SINK_THREAD:当前活跃 sinkThread / 最大 sinkThread。如果 sinkThread 较少证明 sink 端较为空闲,未达到瓶颈。
请问这个 最大 sinkThread的值能调大吗?活跃的数量已经达到最大,应该怎么调呢?是不是这个就是workerNum?
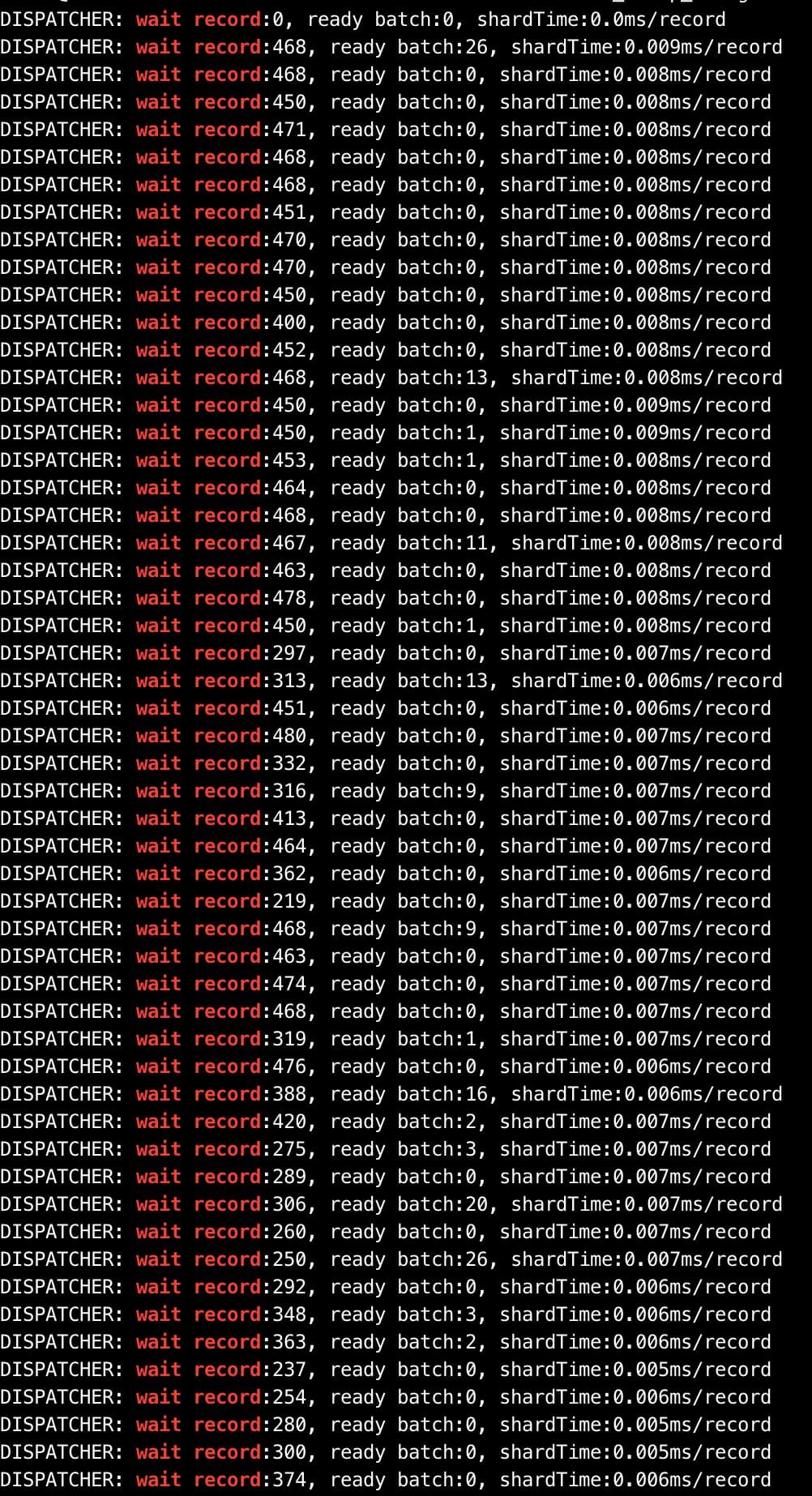
还有个问题:文档上说如果 wait record 数量较多,证明消息数量较大,可能受到 GC 影响。延迟较高的时候,wait record都在400多,但是后面的ParNew(count:3155,cost:18969),ConcurrentMarkSweep(count:0, cost:0)这个应该是只有yong gc,没有full gc,这个yong gc次数这么高对性能有没有影响?
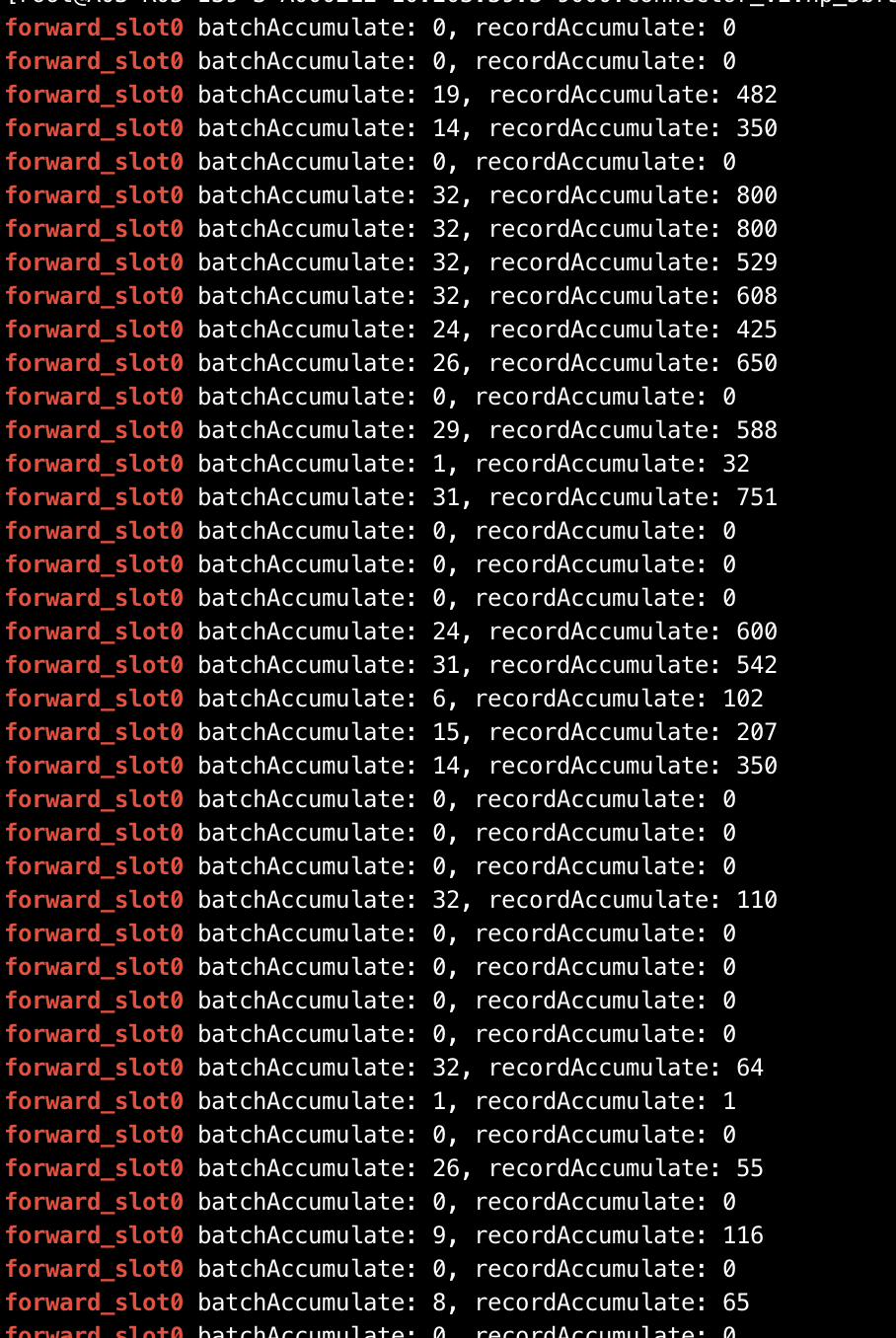
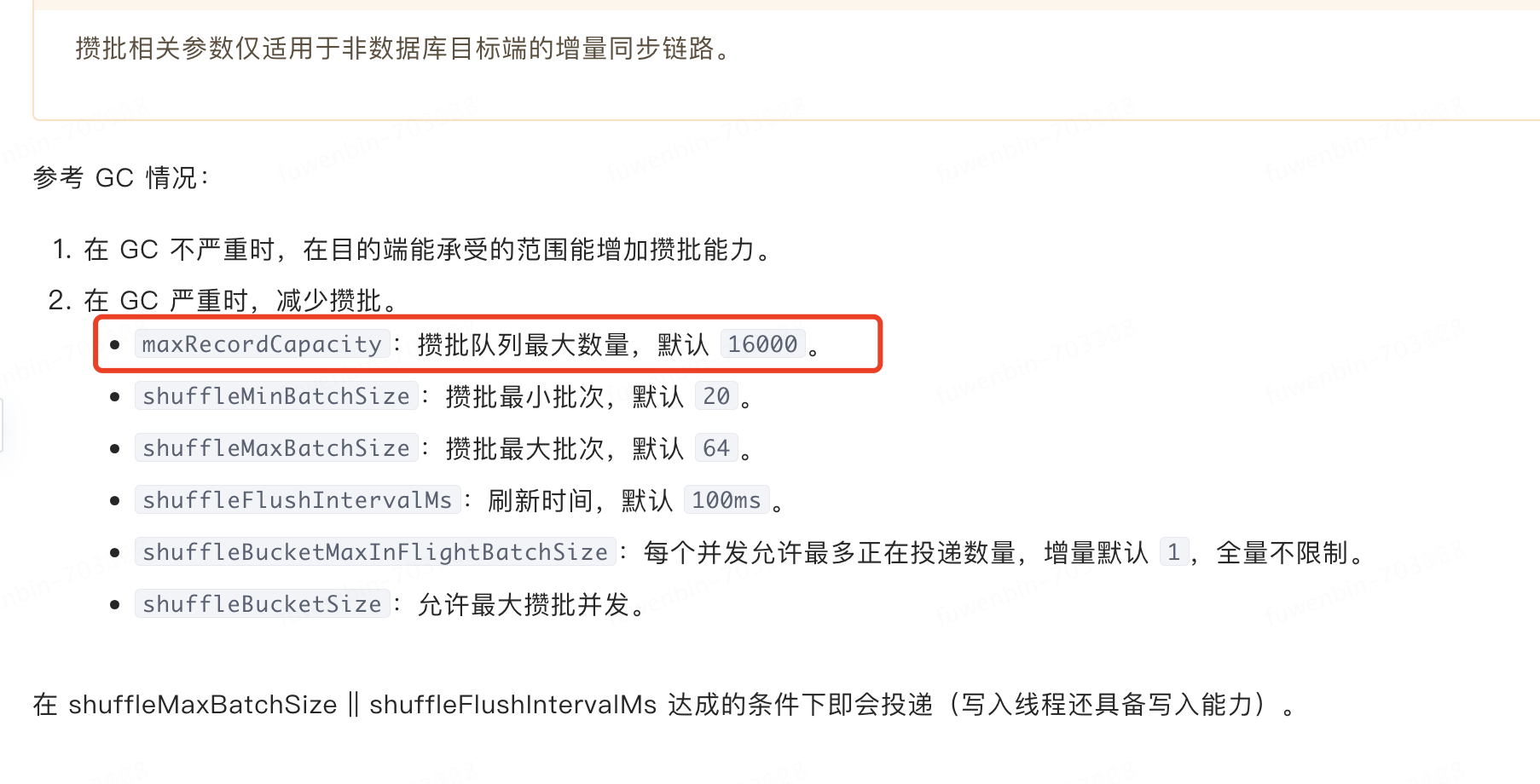
如果最后一个队列 batchAccumulate 满则证明瓶颈在 RecordDispatcher(冲突矩阵/散列) 中,此时需要看 DISPATCHER 的 metrics,看延迟比较高的时候queue_slot1 batchAccumulate: 32, recordAccumulate: 800,是DISPATCHER这里有瓶颈么?文档上好像没写怎么查看dispatcher的日志,在docker内部logs目录下也没有找到

是的
调大workerNum,同时调大jvm内存
记录数
Incr_Sync 读取store慢,Incr_Sync 处理store数据的时候需要将数据经过事务冲突矩阵,保证记录按照按照顺序执行,这里有个很复杂的判断过程
这块可以调优么?针对目前这个case,优化的思路是啥?source端新加如下配置?
useSchemaCache=true
useBetaListener=true