【 使用环境 】测试环境
【 OB or 其他组件 】OMS
【 使用版本 】4.1.1
【问题描述】请教下大佬们,现在想通过OMS同步变更日志到公司自建的Kafka集群,拉变更日志的时候是单线程拉的还是并发拉的?看OMS的文档是要先把拉的变更日志在OMS的机器上暂存,这块性能怎么样,有官方的性能测试数据么?
【复现路径】无
【附件及日志】无
日志流间并行,日志流内串行+异步
租户的unit数量,一个unit一个日志流
性能测试数据目前没有,目前从用户使用情况来说,还没有出现过这部分性能不满足的情况
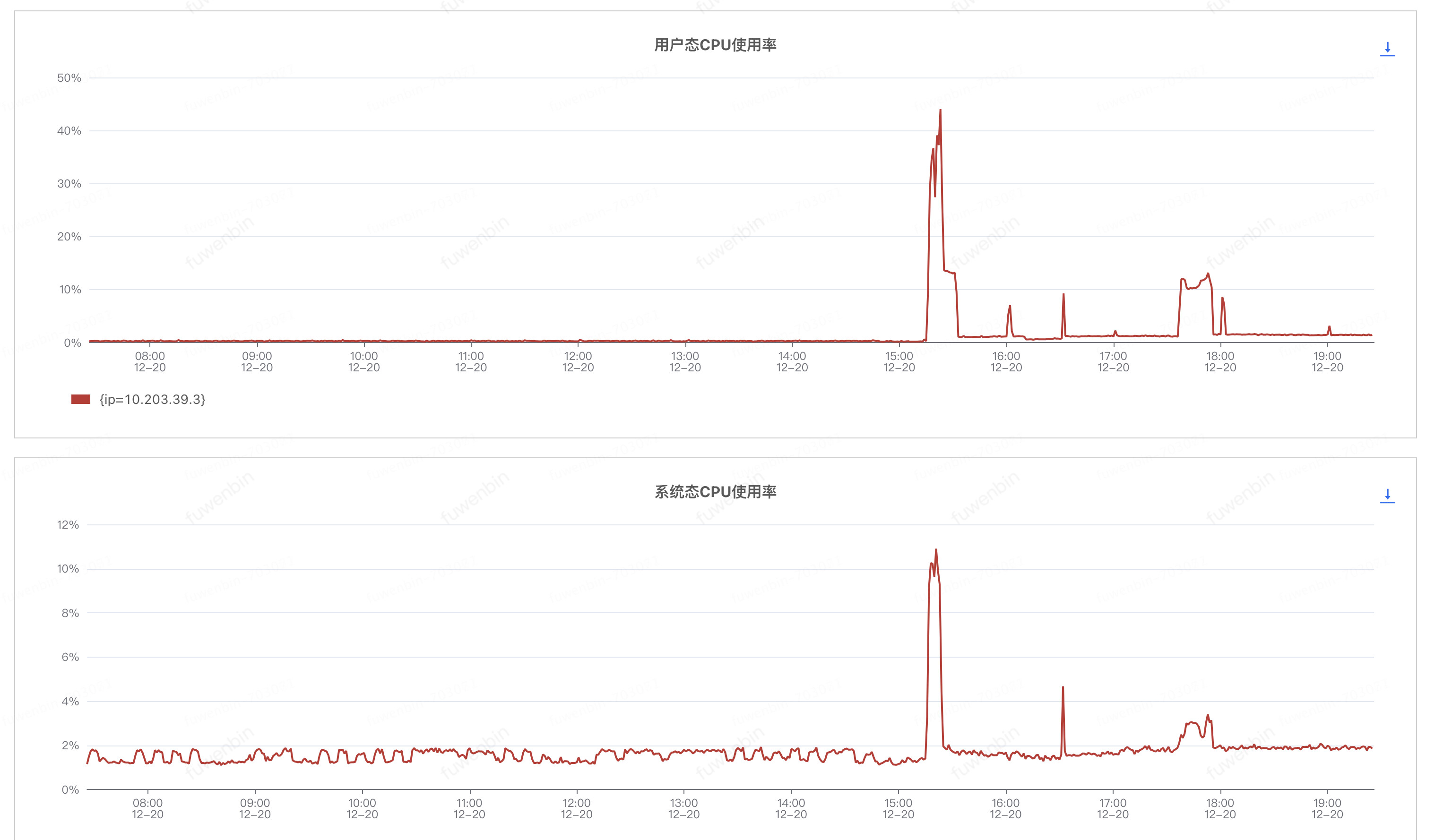
做了下性能测试:最大延迟10min,下面是OMS以及Kafka的一些配置,大佬们帮看看怎么优化下:
OMS采用单地域3节点的配置,每台机器的配置32c128g,kafka的topic有18个partition,同步时候监控如下:
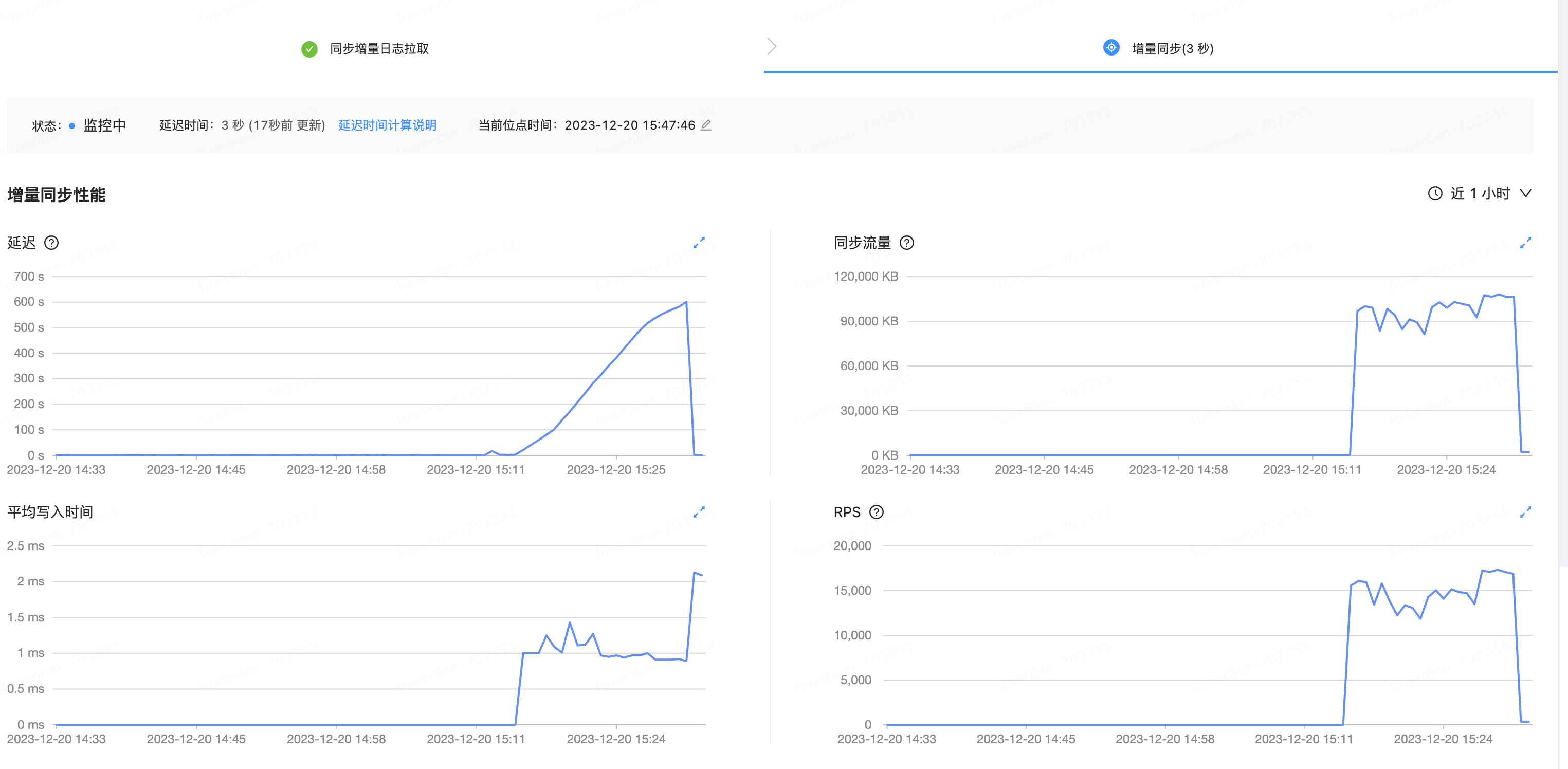
kafka的监控显示同步大概每分钟100w条左右
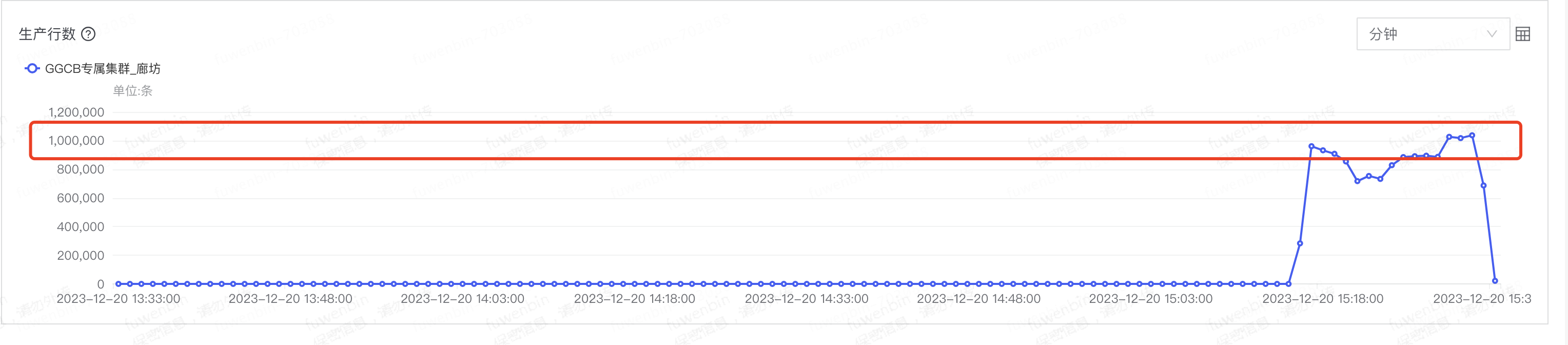
oms显示主要慢在增量同步端,具体如下图。我的理解是应该慢在了发kafka上
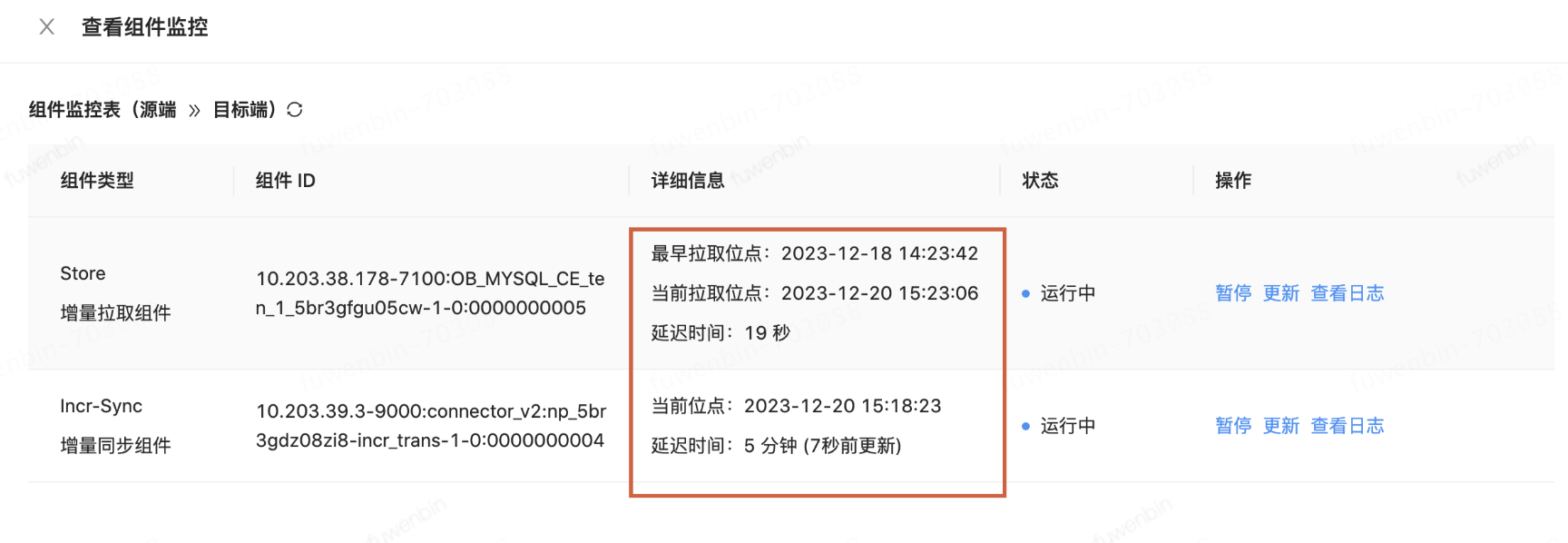
kafka的监控也显示18个partition上所有的生产者都来自与一个ip,具体如下图。这个增量同步可以从多个oms节点上并发拉取么?我看同步期间,cpu和内存大概也就百分之20多,这块需要怎么优化?
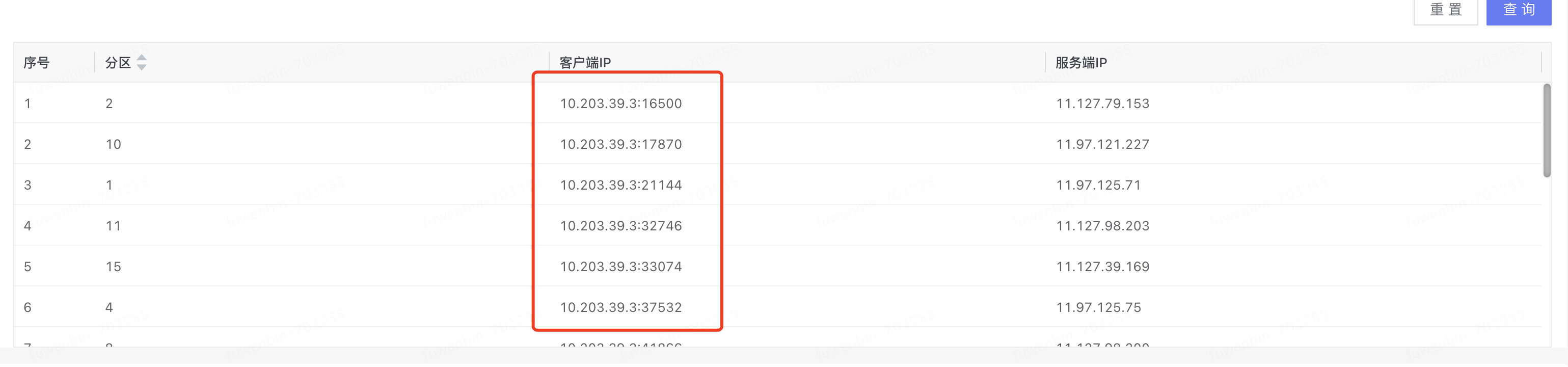
还有个问题,这三个oms节点都是机械磁盘的机器,换成固态硬盘会有质的提升么?我看增量同步最终要在本地持久化,这个是异步的么?
一条链路,store只会有一个,writer也只有一个,不会有并发拉去,上面说的并发拉去是store层面会并发从数据库的日志流中拉去,但进程还是一个
截图看上去是写入端有延迟,这种情况一般分两种情况:
1、大事务导致的延迟-这种情况并发真正延迟,而是由于大事务位点导致的延迟
2、写入瓶颈,这个是真的延迟的情况,可以参考下面这份文档调优:https://www.oceanbase.com/docs/community-oms-cn-1000000000425898
请问如果一个oms同时进行数据库间的主从同步,和发变更日志到kafka,这两个互相之间会影响性能吗?
不会,但是增量数据会从数据库拉两次
那是不是可以理解成数据库的压力会变大?另外您上面说的两种可能得写入端延迟情况,应该如何定位具体可能是其中的哪一种呢?比如是主备同步的话,直接查询目标端的最新业务时间?
是的,数据拉两次,数据库压力会变大
两种延迟如何区分,可以通过上面性能调优文档看,如果发现没有记录积压情况,一般就是大事务导致的
当前延迟时间是多少?
需要在有延迟的情况下,并且这个延迟要持续一端时间,也可能页面上显示延迟,后台实际已经追上了,前端页面刷新会有时差
./connector_utils.sh diagnose -s ‘2023-12-20T15:15:00’ -e ‘2023-12-20T15:30:00’,我指定了是下午延迟的时间段,这样ok么?
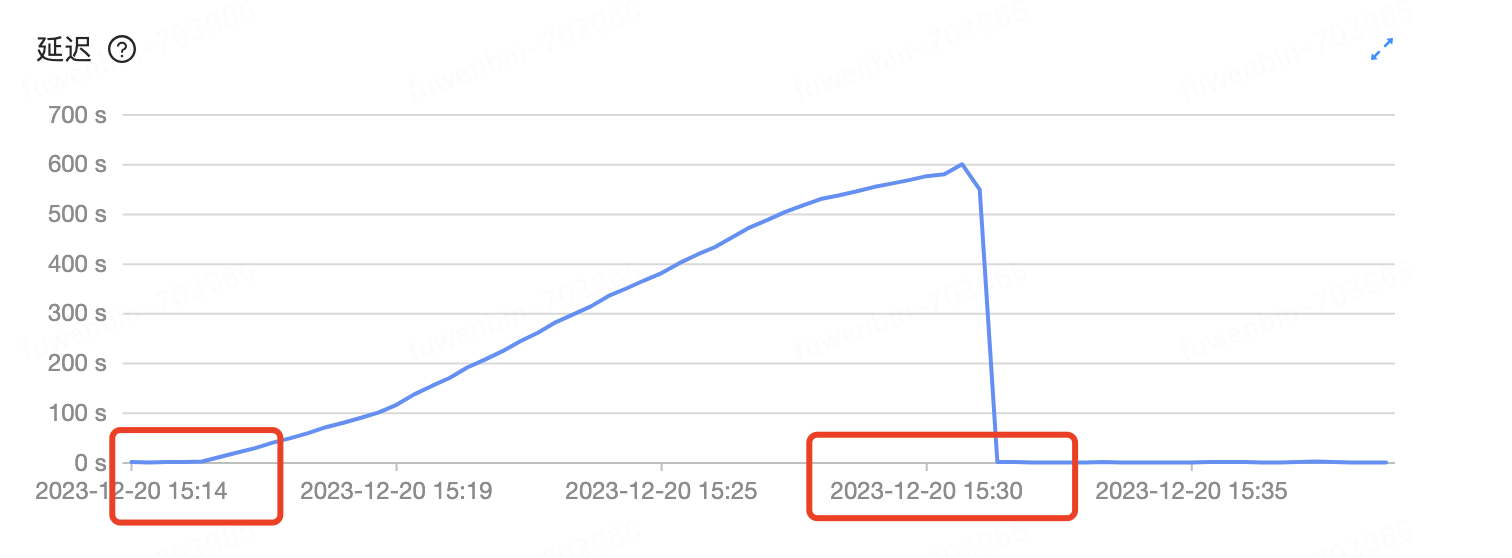
msg下面的:metrics.log 包含‘2023-12-20T15:15:00’ -e ‘2023-12-20T15:30:00’传一下看看
我找下哈,马上提供
延迟这段时间内,cpu load应该比较高,“dispatcher”:{“wait_dispatch_record_size”:468,“ready_execute_batch_size”:0}
这种日志说明记录分发有积压,考虑cpu load高导致,另外也有可能大流量时有fullgc产生,导致cpu load高,记录分发积压