【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】3.1
【问题描述】
问题1 L0 层内部 Compaction 怎么保证不合并掉上层SQL查询还依赖的多版本数据?
这里说,当 L0 层 Mini SSTable 总大小和 L1 Minor SSTable 大小比率达到指定阈值后, 才开始调度 L1 Compaction, 否则仍位置 L0 层内部 Compaction。
问题2 增量合并可以直接重用这个数据宏块,请问是怎么重用的?
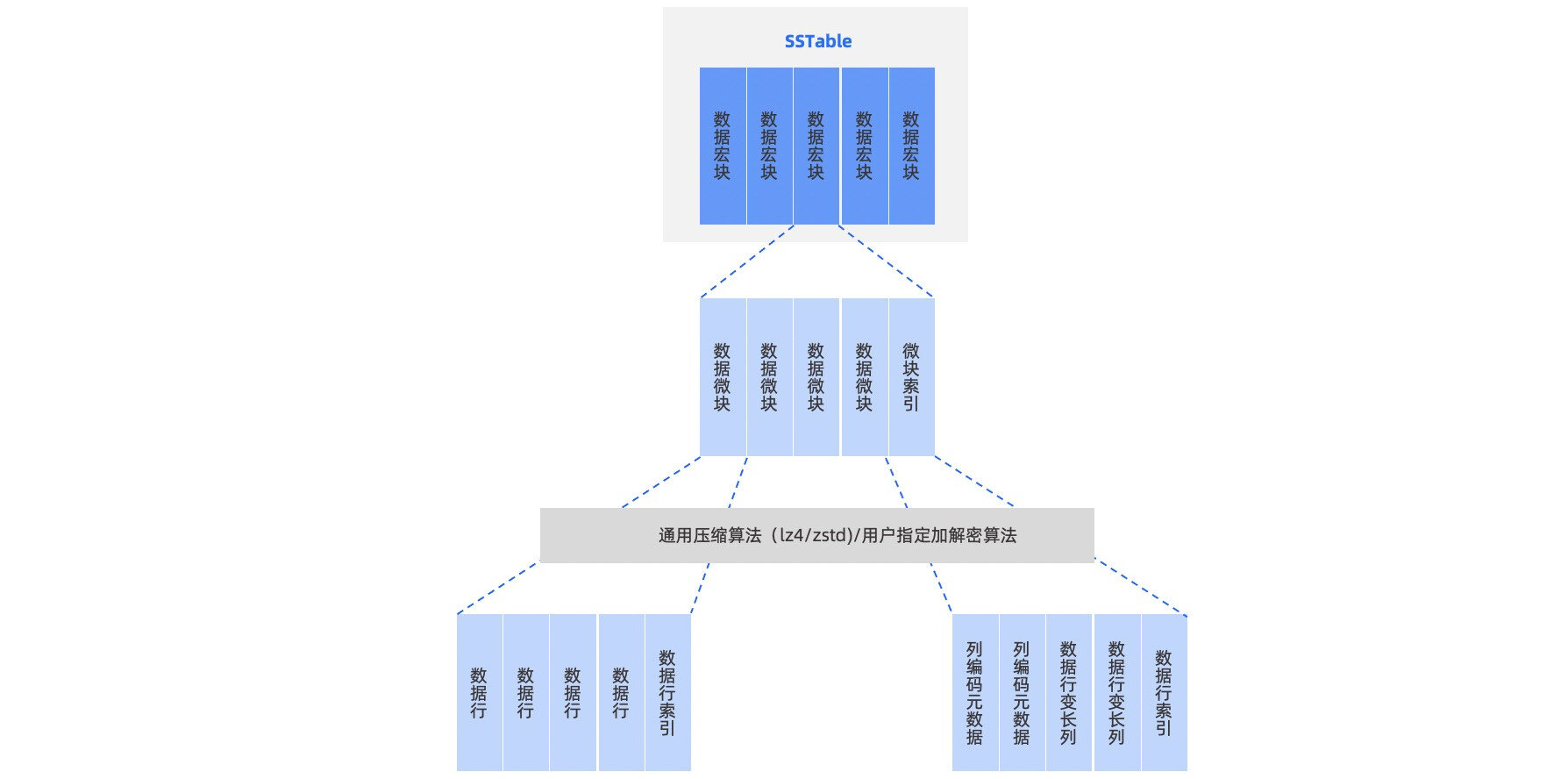
比如major sstable是一个磁盘文件,三个连续宏块的中间那个宏块,在大合并时需要改写,怎么重用前后2个宏块?在重写时由于可以确定中间宏块的偏移量,所有直接改写中间2MB的空间?
一个sstable的多个宏块是按照主键排列的吗?
如果因为新增了主键,比如 宏块1(key1-9),宏块2(key20-30),由于新增了key10-19,是否会在宏块1和宏块2之间再插入一个宏块?如果是这样的话, 宏块2是否可以重用,因为可能在文件中的偏移量变了,可能不需要重新计算生成,只需要重新写一遍?是否会导致后面所有宏块都重写一遍?
另外sstable的怎么知道有几个宏块?有meta信息记录在sstable固定的位置?
【复现路径】
【问题现象及影响】
【附件】
2 个赞
-
compaction后还是会保留下来
这个是怎么实现的?依据什么来确定这个版本是否需要保留?
-
sstable物理上并不是"连续的文件",而是由多个不连续的宏块构成的,
在磁盘上我看是一个整体文件啊。如果不连续,这些宏块是怎么组织的呢?怎么知道一个宏块在的sstable文件上的位置/偏移量
请发下3.0和4.0宏块meta的结构,是类似于B树的结构吗?
如果30的宏块meta只在内存中,宕机重启时怎么重新生成,需要扫描一遍sstable?
4.0的宏块索引结构,和其他sstable的宏块都保存在同一个sstable文件中?
合并时会收集现在活跃事务的读版本?如果是看完后,其他分片上已存在的读事务才读到这个分片,这种是不是就没法收集到了?
如果删除了很多行,大合并后,导致很多宏块被删除了,这个文件会有空洞吗?
进行紧缩的时机是什么?
镜水
#8
事务模块会提供这样的能力,能够提供最小活跃事务的快照。具体实现我了解不多。
宏块被删了,下一次同样的位置就可以作为新宏块写入新的数据
是否可以请事务模块的人帮忙回答下?
宏块被删了,下一次同样的位置就可以作为新宏块写入新的数据
那就不进行紧缩?如果我删除了大量行,结果发现block file占用空间没少,大合并后也不减少?
如果磁盘空间不足了,也没法通过删除行来腾空间?只能删除分区?
4x增加的微块索引,是一个sstable一整个微块索引树吗?还是一个宏块一个微块索引树?
rowkey+trans_version作为key就可以保留多个版本
一行的多个版本在微块索引树是一个叶子数据节点?类似于memtable报错多个版本的方式?叶子节点挂一个链表保存多个版本?
镜水
#10
block file你从磁盘看本来就不会减少的。ob不支持data file size的缩容。
但实际占用的磁盘空间是指被分配宏块使用了的空间。
一个sstable一整个索引树。
你上面的图里已经给出了答案,微块里存储数据行,数据行里增加一个trans_version列,这样就可以多个数据行多个版本但是是同一个rowkey了
合并时会收集现在活跃事务的读版本?如果是收集完后,其他分片上已存在的读事务才读到这个分片,这种是不是就没法收集到了?
事务模块会提供这样的能力,能够提供最小活跃事务的快照。具体逻辑是怎样的?