

相同的代码,相同的120万数据量,Oracle回写速度90秒左右,但Oracle是本地单机部署;ob三节点集群,耗时在1800秒左右。
同样慢的一个步骤还有sr_crm_data = oracle_cursor.fetchall() 把ob查询到的数据赋值给python变量,Oracle的速度大概是ob的三十倍。
想求教一下,代码层面还有优化的空间吗
想求教一下,代码层面还有优化的空间吗
请问你是用的企业版本吗
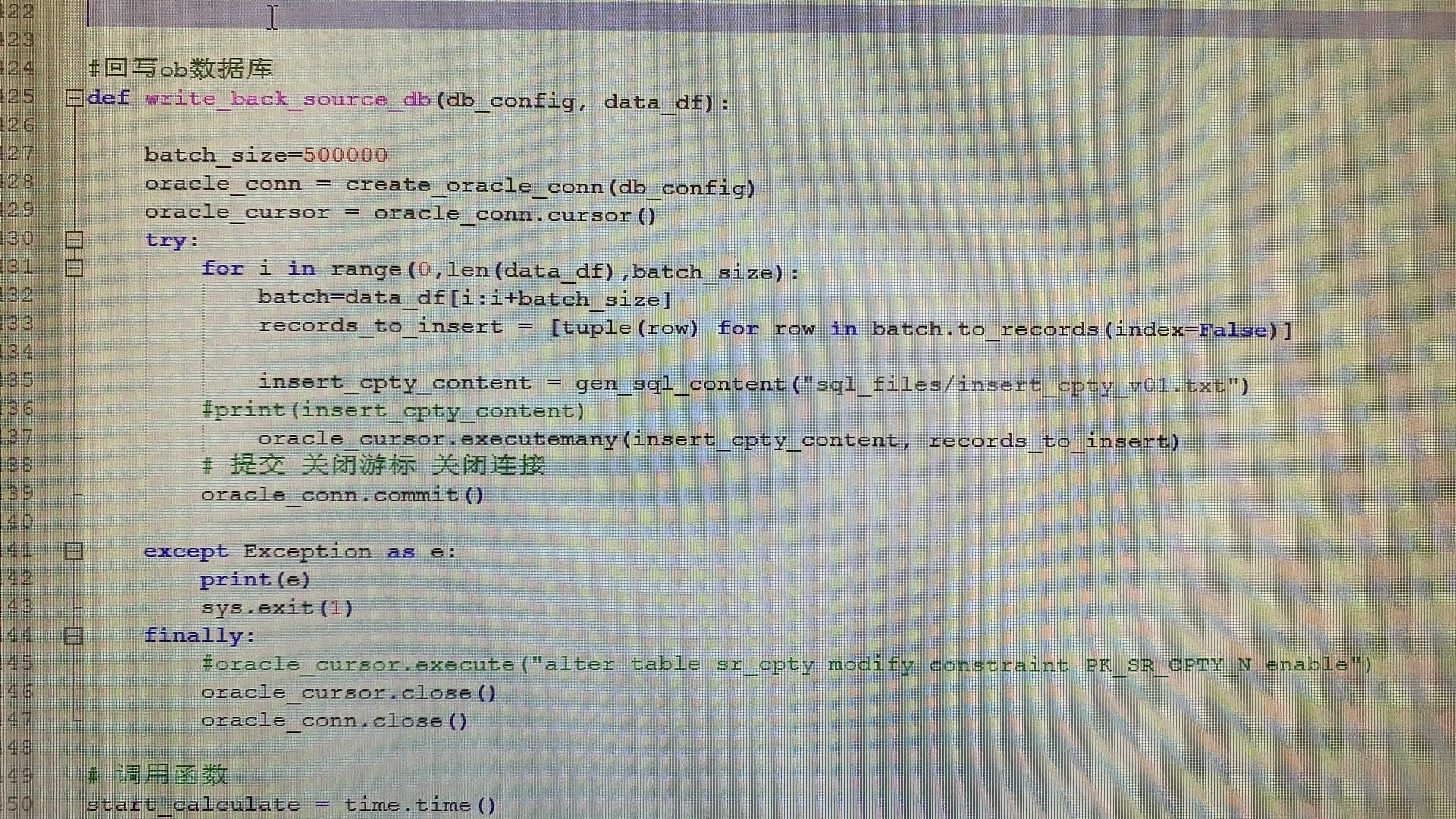
是的,企业版。现在在搭建某金融机构的一个系统,要求用存算分离,多数脚本的流程是:在python环境中,通过JDBC(目前驱动是2.2.9)连接ob,取到需要计算的数据后,导入内存数据库进行计算,得到一个结果集,最终这个结果集往ob里回写。现在存在性能问题的就是回写这部分,巨慢。回写的代码如上图。
辛苦联系下企业的技术支持他们会给你解答的
OB 写入慢,代码层面可以优化:
然后就是优化OB实例。
需要看看OB 租户资源大小。
在 SYS 租户里查看。
select a.zone,concat(a.svr_ip,':',a.svr_port) observer, cpu_total, (cpu_total-cpu_assigned) cpu_free
, round(mem_total/1024/1024/1024) mem_total_gb, round((mem_total-mem_assigned)/1024/1024/1024,2) mem_free_gb
, round(disk_total/1024/1024/1024) disk_total_gb, round((disk_total-disk_assigned)/1024/1024/1024) disk_free_gb
from __all_virtual_server_stat a join __all_server b on (a.svr_ip=b.svr_ip and a.svr_port=b.svr_port)
order by a.zone, a.svr_ip
;
select t1.name resource_pool_name, t2.`name` unit_config_name, t2.max_cpu, t2.min_cpu
, round(t2.max_memory/1024/1024/1024) max_mem_gb, round(t2.min_memory/1024/1024/1024) min_mem_gb
, round(t2.max_disk_size/1024/1024/1024) max_disk_size , t4.tenant_name
from __all_resource_pool t1 join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id
;
客户先让我们自己解决,到时候实在没办法再联系厂商吧
分批回写这个有尝试过,但无论怎么调整,速度始终保持在 1000条左右/秒 400多万数据用了一个多小时,总耗时还是太长了
终究还是要看你的租户资源配置,
还有内存相关的几个参数。下面SQL在业务租户下查看。
show parameters WHERE name IN ('minor_freeze_times','major_freeze_duty_time','freeze_trigger_percentage','writing_throttling_trigger_percentage');
请问解决了吗?我们也遇到了类似的问题,用Python程序执行sql很慢,直接使用ob客户端执行很快。