【 使用环境 】 测试环境
【附件】
pod也一直无法启动
1 个赞
其灵
2023 年10 月 17 日 14:50
#3
因为不是通过执行sql命令删除节点,所以会有信息残留,集群会认为该节点还在集群中,只是因为某些问题宕机/断连了。对于3副本的集群,如果停掉2个zone,剩下一个副本无法形成多数派,自然就不能提供服务。单zone 3replicas的情况,如果把这个zone删掉了,另外两个zone没有相关数据,那自然无法提供服务了。为什么必须要手动删pod呢,要不尝试下先从集群中把这个节点删除?
你好,这个问题是因为 OB 在设计上是靠多数派来保证高可用的,1.2 的实现上如果pod被删除,会重新创建一个 pod,并且执行add server 和delete server操作,这个操作是需要依靠整个 OB 集群正常可用的。
手动删除是模拟一下可能发生的情况,从集群删除的话pod是否也会由operater来重建呢。主要是不能完全避免发生手动删pod的情况,需要考虑发生之后如何处理。
2.0也测试过了的,发生过两个问题,就还是切到1.2了,以为1.2稳定些。那如果发生pod误删的话有解决方案么
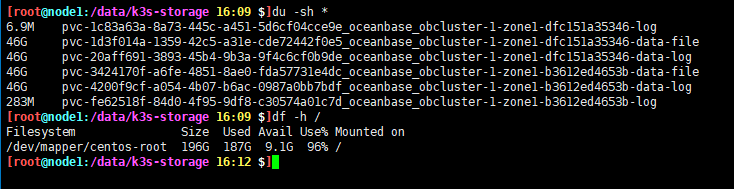
出现过节点100G的盘被写满的情况,发现都是ob的目录
3 zone 2 replicas出现了zone1 的一个pod一直无法ready的情况
还是推荐用2.0版本吧,我们之后主要精力也是在2.0版本上,100G磁盘写满是 OB 的日志写满了吗,第二个问题,可以帮忙提供下更详细的信息吗,describe一下这个pod有什么信息吗
当时的环境已经没有了,如果推荐2.0的话,我还是基于2.0验证一下看看能不能复现上面说的问题。另外还是比较关心的问题是误删pod导致集群故障以及其它情况导致集群异常的处理办法,目前没有找到这块的文档
3 zone 1 replicas的情况下没办法从集群里面删除节点,zone下的server不够。1 zone 3 replicas不是类似于 PXC的方案么,删除第2个和3个的pod正常,如果删除第一个pod就故障了。
如果使用了2.0版本的话,现在做了一些优化,对于calico网络插件做了识别,和自动设置annotation,在集群部署好了之后会设置pod ipaddrs的annotation,如果是这种情况,在pod删除了之后,重新拉起的pod是会设置成相同的ip,磁盘数据还在的话,即使多数派挂掉,但是pod重新起来之后,集群可以恢复正常
就是说如果k8s本身没有支持固定pod ip的网络插件的话,发生pod误删其实没有什么办法来恢复么,2.0也没有应对这种情况的办法。
比如3 zone 1 replicas,我删除了1个zone的pod,然后会有一个正常的pod加入到集群。我继续删第二个zone的pod,这个时候新的pod就无法创建成功了。但是这个时候应该会有2个zone有正常节点的,为什么是判断是多数节点掉线啊。
使用了2.0的部署测试
猜测是磁盘被打爆了,出现了2份pod数据,第二个pod没有复用之前的pvc
对于固定 IP 地址的插件,重新创建pod保证ip地址不变,相当于机器重启,进程重启,数据在的话会正常恢复,对于不支持的情况,重新创建pod相当于替换了一台新的机器,这个时候处理流程就是addserver + deleteserver,当第一个pod正常加入,进程提供了服务之后,再删除第二个pod是可以的,如果第一个pod还未正常加入到集群,那再删除一个pod之后,整个OB集群无法正常提供服务,就没办法继续走addserver的流程,就会不正常
你的环境是用的什么网络插件呢,磁盘空间是否是足够的
第一次删除pod之后新的pod已经起来并加入到集群了,这个时候删除另外一个zone的pod才会出问题。我理解的是第一次删pod时的zone里面是有1个正常server和1个离线server的,这种情况这个zone属于正常状态吗?如果不属于,第二次再删其它zone的pod才会出现多数掉线的现象吧。
网络插件是flannel,pod起不来的原因是磁盘耗尽了。但是我看pod挂载pvc是用的pod名+后缀的,pod名称是变化的,那旧pv的数据不是没法用了吗,删除pod之前的数据就没了。
zone里面有一个server正常一个离线,其实对于zone来说,只要正常的server能满足租户unit的资源要求,并且unit迁移到了这个server之后,那这个zone就是正常提供服务的,这个时候再删除第二个zone的pod是可以的
是的,但是为了保险起见,我们还是在addserver之后再deleteserver,数据也是在deleteserver之后就被级联的删除了,而且如果zone当中只有一个server,或者server的资源不够故障的server上的unit迁移,那删除server得操作也是会失败的
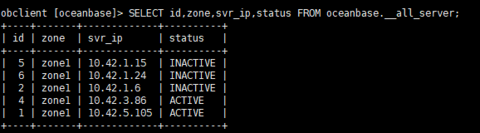
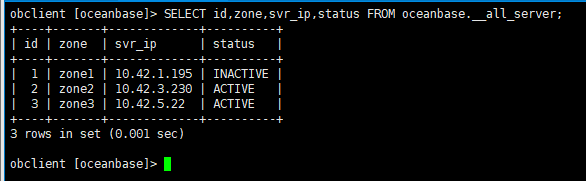
如果需要检查server是否正常了,可以看这些信息,首先在__all_server表中状态是ACTIVE,然后start_service_time > 0, __all_unit 表中,migrate_from_svr_ip,migrate_from_svr_port 是空的和0, 表示unit也迁移完了,如果server起来了,但是unit还没迁移好,这个时候再删除第二个zone的pod仍然有可能会不可用
之前1.2版本测试的时候我测试出现异常是不是有可能就是unit没有自动迁移导致的,新的pod已经起来了我之前创建的数据也能查到,但是继续删其它zone的pod时集群就不可用了。unit是不回自己迁么还是有延迟啊,当时我尝试删除离线server是会卡在deleteing状态的。