使用环境 】测试环境
【 OB or 其他组件 】observer
【 使用版本 】社区版 3.1.5 oceanbase-ce-3.1.5-100020022023091114.el7.x86_64.rpm
【问题描述】最近在备考obcp认证,想通过单台物理机部署多个observer实例,用于练习实验,安装以下实验环境

物理机配置
CentOS Linux release 7.5.1804 (Core)
cpu:40核
内存:128G
目录规划如下:
zone1 192.168.89.14 2881 2882
安装目录:/home/admin/oceanbase/1
日志目录:/gpdata/redo/1
数据目录:/gpdata/data/1
zone2 192.168.89.14 3881 4882
安装目录:/home/admin/oceanbase/2
日志目录:/gpdata/redo/2
数据目录:/gpdata/data/2
zone3 192.168.89.14 4881 4882
安装目录:/home/admin/oceanbase/3
日志目录:/gpdata/redo/3
数据目录:/gpdata/data/3
zone1 192.168.89.14 5881 5882
安装目录:/home/admin/oceanbase/4
日志目录:/gpdata/redo/4
数据目录:/gpdata/data/4
zone2 192.168.89.14 6881 6882
安装目录:/home/admin/oceanbase/5
日志目录:/gpdata/redo/5
数据目录:/gpdata/data/5
zone3 192.168.89.14 7881 7882
安装目录:/home/admin/oceanbase/6
日志目录:/gpdata/redo/6
数据目录:/gpdata/data/6
1.先启动前三个节点创建一个集群
启动observer进程正常
cd /home/admin/oceanbase/1 && bin/observer -z zone1 -p 2881 -P 2882 -n obdemo -c 20230910 -d ~/oceanbase/1/store/obdemo -i ens2f0 -o “memory_limit=24G,__min_full_resource_pool_memory=2147483648,system_memory=4G,cache_wash_threshold=1G,memory_chunk_cache_size=128M,cpu_count=16,net_thread_count=2,datafile_size=50G,stack_size=1536K” -r ‘192.168.89.14:2882:2881;192.168.89.14:3882:3881;192.168.89.14:4882:4881’
cd /home/admin/oceanbase/2 && bin/observer -z zone2 -p 3881 -P 3882 -n obdemo -c 20230910 -d ~/oceanbase/2/store/obdemo -i ens2f0 -o “memory_limit=24G,__min_full_resource_pool_memory=2147483648,system_memory=4G,cache_wash_threshold=1G,memory_chunk_cache_size=128M,cpu_count=16,net_thread_count=2,datafile_size=50G,stack_size=1536K” -r ‘192.168.89.14:2882:2881;192.168.89.14:3882:3881;192.168.89.14:4882:4881’
cd /home/admin/oceanbase/3 && bin/observer -z zone3 -p 4881 -P 4882 -n obdemo -c 20230910 -d ~/oceanbase/3/store/obdemo -i ens2f0 -o “memory_limit=24G,__min_full_resource_pool_memory=2147483648,system_memory=4G,cache_wash_threshold=1G,memory_chunk_cache_size=128M,cpu_count=16,net_thread_count=2,datafile_size=50G,stack_size=1536K” -r ‘192.168.89.14:2882:2881;192.168.89.14:3882:3881;192.168.89.14:4882:4881’
初始化
obclient -h192.168.89.14 -uroot -P2881 -p -c -A
set session ob_query_timeout=100000000000;
alter system bootstrap ZONE ‘zone1’ SERVER ‘192.168.89.14:2882’,ZONE ‘zone2’ SERVER ‘192.168.89.14:3882’,ZONE ‘zone3’ SERVER ‘192.168.89.14:4882’;
并在集群中创建了两个租户
2.准备将第四个observer启动并扩容到zone1中
cd /home/admin/oceanbase/4 && bin/observer -z zone1 -p 5881 -P 5882 -n obdemo -c 20230910 -d ~/oceanbase/4/store/obdemo -i ens2f0 -o “memory_limit=24G,__min_full_resource_pool_memory=268435456,system_memory=3G,cache_wash_threshold=1G,memory_chunk_cache_size=128M,cpu_count=16,net_thread_count=4,datafile_size=50G,stack_size=1536K,config_additional_dir=/home/admin/4/etc3;/home/admin/4/etc2” -r ‘10.168.89.14:5882:5881’
启动进程一直启动不起来,observer.log报如下错误
[2023-09-20 16:13:55.175254] INFO ob_page_manager.cpp:43 [323855][1612][Y0-0000000000000000] [lt=11] [dc=0] unregister pm finish(&pm=0x7f861c930900, pm.get_tid()=323855)
[2023-09-20 16:13:55.176463] ERROR [LIB] start (thread.cpp:107) [323045][0][Y0-0000000000000000] [lt=21] [dc=0] pthread create failed(pret=11, errno=11) BACKTRACE:0x9b9cc0e 0x996fe41 0x23372af 0x2336efb 0x2336cc2 0x232aae4 0x9925222 0x9920f95 0x9920e59 0x2d07c72 0x93a8acf 0x938dcb5 0x938d412 0x9467ae5 0x945c7b6 0x22f8b85 0x7f884dba8445 0x22f7869
[2023-09-20 16:13:55.176615] ERROR [SERVER.OMT] create_worker (ob_worker_pool.cpp:126) [323045][0][Y0-0000000000000000] [lt=78] [dc=0] start worker fail(ret=-4015) BACKTRACE:0x9b9cc0e 0x996fe41 0x22fc534 0x22fc01b 0x22fbd81 0x22faa18 0x93a8c01 0x938dcb5 0x938d412 0x9467ae5 0x945c7b6 0x22f8b85 0x7f884dba8445 0x22f7869
[2023-09-20 16:13:55.176652] ERROR [SERVER.OMT] init (ob_worker_pool.cpp:45) [323045][0][Y0-0000000000000000] [lt=31] [dc=0] create worker fail(ret=-4015) BACKTRACE:0x9b9cc0e 0x996fe41 0x22fc534 0x22fc01b 0x22fbd81 0x22faa18 0x938de8f 0x938d412 0x9467ae5 0x945c7b6 0x22f8b85 0x7f884dba8445 0x22f7869
[2023-09-20 16:13:55.176686] INFO ob_page_manager.cpp:34 [323857][0][Y0-0000000000000000] [lt=0] [dc=0] register pm finish(ret=0, &pm=0x7f861c2e4900, pm.get_tid()=323857, tenant_id=500)
…
[2023-09-20 16:13:55.425064] WARN [SHARE.SCHEMA] check_formal_guard (ob_schema_getter_guard.cpp:7125) [323540][984][Y0-0000000000000000] [lt=11] [dc=0] local schema_version is not formal, try again(ret=-5627, schema_version=1)
[2023-09-20 16:13:55.425090] WARN [STORAGE] runTimerTask (ob_build_index_scheduler.cpp:1649) [323540][984][Y0-0000000000000000] [lt=24] [dc=0] schema_guard is not formal(ret=-5627)
[2023-09-20 16:13:55.425198] INFO [STORAGE] ob_pg_sstable_garbage_collector.cpp:188 [323419][746][Y0-0000000000000000] [lt=24] [dc=0] do one gc free sstable by queue(ret=0, free sstable cnt=0)
[2023-09-20 16:13:55.425494] WARN [SERVER.OMT] init (ob_multi_tenant.cpp:195) [323045][0][Y0-0000000000000000] [lt=14] [dc=0] init worker pool fail(ret=-4015, init_workers_cnt=312, idle_workers_cnt=312, max_workers_cnt=566, node_quota=1.400000000000000000e+01, times_of_workers=10)
[2023-09-20 16:13:55.425513] ERROR [SERVER] init_multi_tenant (ob_server.cpp:1206) [323045][0][Y0-0000000000000000] [lt=14] [dc=0] init multi tenant fail(ret=-4015) BACKTRACE:0x9b9cc0e 0x996fe41 0x22fc534 0x22fc01b 0x22fbd81 0x22faa18 0x9468a02 0x945c7b6 0x22f8b85 0x7f884dba8445 0x22f7869
[2023-09-20 16:13:55.425563] ERROR [SERVER] init (ob_server.cpp:318) [323045][0][Y0-0000000000000000] [lt=44] [dc=0] init multi tenant fail(ret=-4015) BACKTRACE:0x9b9cc0e 0x996fe41 0x22fc534 0x22fc01b 0x22fbd81 0x22faa18 0x945e831 0x22f8b85 0x7f884dba8445 0x22f7869
[2023-09-20 16:13:55.425580] INFO [SERVER] ob_service.cpp:265 [323045][0][Y0-0000000000000000] [lt=14] [dc=0] [NOTICE] observice need stop now
请问是我哪里配置的不对吗?,详细的日志见下附件
log20230920.tar.gz (193.7 KB)
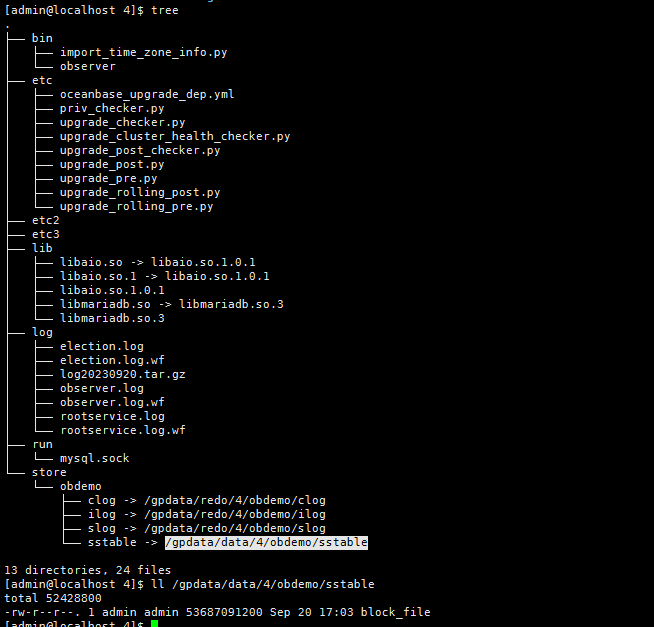
第4个节点的目录结构如下: