【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】
5.7.25-OceanBase_CE-v4.0.0.0
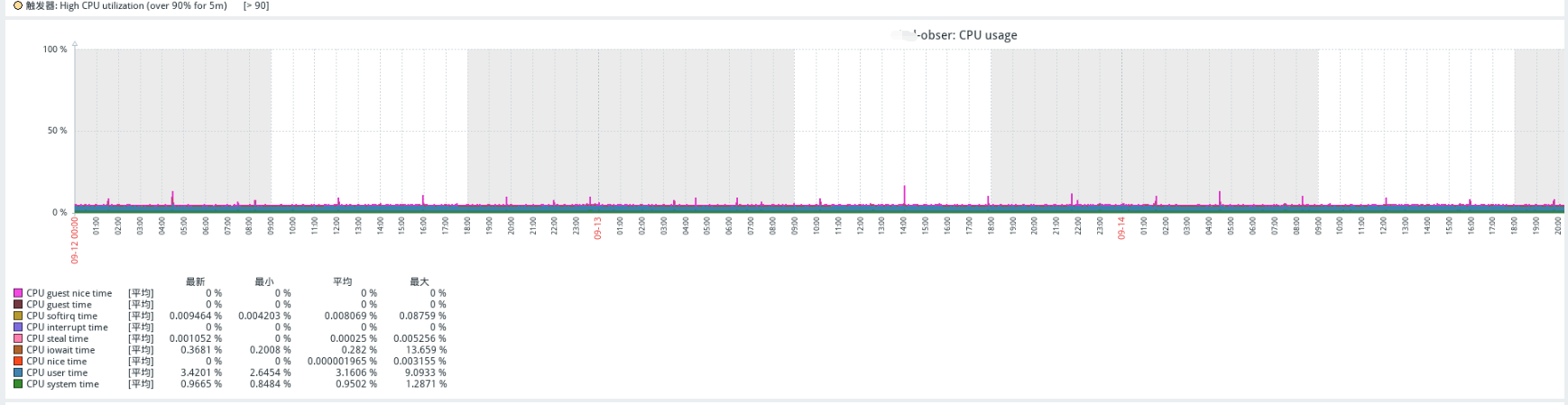
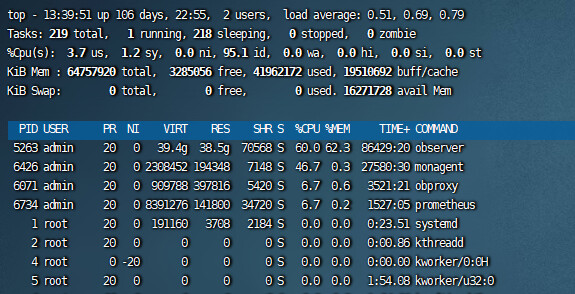
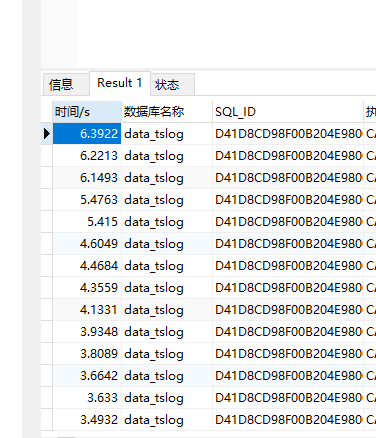
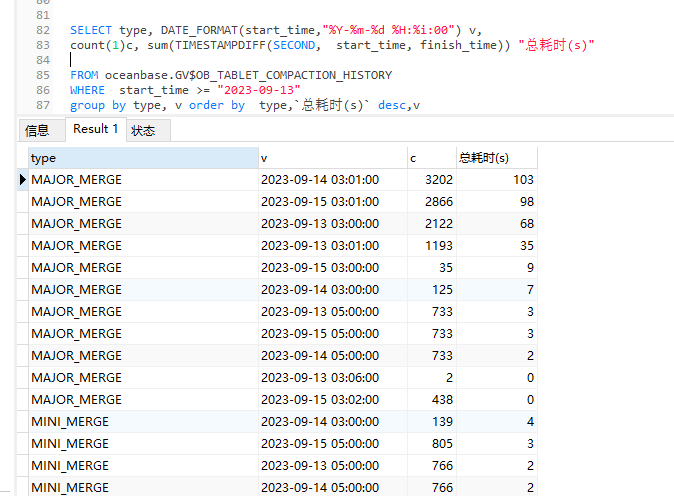
【问题描述】AWS线上业务查询昨天发生异常。秒级的查询,10-20秒才响应,等待时间长,怀疑是内存问题,于是把系统内存调低(12G–>8G),租户内存调高(26G–>30G),间隔一段时间后,查询时间恢复了正常,缓慢.查询监控显示数据盘io压力过大,磁盘利用率和队列每4小时飙高到90%+,CPU使用率低,内存占用率高。
正式服搭建的两套 单机4.0版本 发现好像都有此类问题.
配置如下
机器:16C 64G 3硬盘 2T+1T+1T
aws gp3 硬盘 : 2T (数据盘)iops:3000 吞吐:126 OB分配可用1.5T OB数据已用: 58.62G
| zone | svr_ip | svr_port | cpu_capacity | cpu_assigned_max | cpu_free | memory_total_gb | system_memory_gb | mem_assigned_gb | memory_free_gb | log_disk_capacity_gb | log_disk_assigned_gb | log_disk_free_gb | data_disk_gb | data_disk_used_gb | data_disk_free_gb |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| zone1 | 172.31.23.142 | 2882 | 16 | 13 | 3 | 50 | 8 | 36.25 | 5.75 | 152 | 18.25 | 133.75 | 1500 | 58.62 | 1441.38 |
【复现路径】问题出现前后相关操作
【问题现象及影响】
【附件】