

本文主要分享 OceanBase 3.2.4 锁阻塞问题排查。虽然官网给出了一个排查方法指引,实践发现,这个方法有一些不足。
用本文最后给出的方法能快速定位所有场景的锁阻塞会话信息。
对OB理解有限,可能有不当之处,欢迎留言交流。
数据库环境介绍
三节点 OB 集群,租户 obmysql 也是三副本。
SELECT tenant_name, ZONE, svr_ip, unit_config_name, round(max_memory/1024/1024/1024) max_mem_gb, round(min_memory/1024/1024/1024) min_mem_gb
FROM gv$unit
ORDER BY ZONE ;
| tenant_name | ZONE | svr_ip | unit_config_name | max_mem_gb | min_mem_gb |
|---|---|---|---|---|---|
| obmysql | zone1 | 10.0.0.61 | config_obmysql_zone1_S3C3G_ptn | 3 | 3 |
| obmysql | ZONE2 | 10.0.0.62 | config_obmysql_ZONE2_S3C3G_xyt | 3 | 3 |
| obmysql | ZONE3 | 10.0.0.63 | config_obmysql_ZONE3_S3C3G_hgb | 3 | 3 |
测试表 bmsql_oorder 是分区表,分区分布在三个节点上。
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp,
primary key (o_w_id, o_d_id, o_id)
) partition by hash (o_w_id) partitions 12 ;
SELECT
t5.tenant_name,
t4.database_name,
t3.tablegroup_name,
t1.table_id,
t1.table_name,
t2.partition_id,
t2.role,
t2.zone,
concat(t2.svr_ip, ':', t2.svr_port) observer,
round(t2.data_size / 1024 / 1024) data_size_mb,
t2. row_count
FROM
gv$table t1
JOIN gv$partition t2 ON (t1.tenant_id = t2.tenant_id AND t1.table_id = t2.table_id)
LEFT JOIN __all_virtual_tablegroup t3 ON (t1.tenant_id = t3.tenant_id AND t1.tablegroup_id = t3.tablegroup_id)
JOIN gv$database t4 ON (t1.tenant_Id = t4.tenant_id AND t1.database_id = t4.database_id)
JOIN gv$tenant t5 ON (t1.tenant_id = t5.tenant_id)
WHERE
t5.tenant_id = 1008
AND t2.role = 1 AND t4.database_name = 'TPCCDB' AND t1.table_name = 'bmsql_oorder'
ORDER BY
t5.tenant_name,
t4.database_name,
t3.tablegroup_name,
t2.partition_id;
| tenant_name | database_name | tablegroup_name | table_id | table_name | partition_id | role | zone | observer | data_size_mb | row_count |
|---|---|---|---|---|---|---|---|---|---|---|
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 0 | 1 | ZONE2 | 10.0.0.62:2882 | 0 | 30,012 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 1 | 1 | ZONE2 | 10.0.0.62:2882 | 0 | 60,015 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 2 | 1 | ZONE2 | 10.0.0.62:2882 | 0 | 60,018 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 3 | 1 | ZONE2 | 10.0.0.62:2882 | 0 | 30,014 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 4 | 1 | zone1 | 10.0.0.61:2882 | 0 | 30,009 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 5 | 1 | zone1 | 10.0.0.61:2882 | 0 | 30,013 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 6 | 1 | zone1 | 10.0.0.61:2882 | 0 | 30,014 |
| obmysql | tpccdb | tgtpcc | 1,108,307,720,848,215 | bmsql_oorder | 7 | 1 | zone1 | 10.0.0.61:2882 | 0 | 30,012 |
- 分区表
bmsql_oorder的table_id是:1108307720848215,十六进制是0x3F0000000C357,第11位以上是租户 ID 的十六进制数据。 - 分区的主副本分布在节点
10.0.0.61和10.0.0.62上。
租户超时参数
业务租户查看变量。
show global variables where variable_name in ('lock_wait_timeout','ob_query_timeout','ob_trx_idle_timeout','ob_trx_timeout');
| Variable_name | Value |
|---|---|
| lock_wait_timeout | 31536000 |
| ob_query_timeout | 1000000000 |
| ob_trx_idle_timeout | 12000000000 |
| ob_trx_timeout | 10000000000 |
OceanBase 锁和事务相关视图
-
__all_virtual_trans_stat:用于监控活跃事务。 -
__all_virtual_trans_lock_stat:记录了当前集群中所有活跃事务持有行锁的相关信息。 -
__all_virtual_lock_wait_stat:统计了当前集群中所有等待行锁的请求或语句的相关信息。 -
__all_virtual_trans_table_status:文档没有描述,猜测是每次冻结后产生的脏事务的详细信息。 - gv$lock :展示 OceanBase 数据库的行锁信息。
- gv$lock_wait_stat :整个集群中行锁的状态。
- gv$ob_trans_table_status :展示每次冻结后产生的脏事务的详细信息。
官网出了一个锁阻塞排查指引:行锁问题排查 -OceanBase 数据库 -OceanBase文档中心-分布式数据库使用文档 。能解决一部分场景的锁阻塞问题,也有一些场景下没有用。后面先用这个指引分析看看。
测试场景以及分析
小事务阻塞
- 会话 1 开启事务,锁住记录,不提交事务。
obclient [test]> select connection_id(), host_ip(), effective_tenant_id();
+-----------------+-----------+-----------------------+
| connection_id() | host_ip() | effective_tenant_id() |
+-----------------+-----------+-----------------------+
| 3221779663 | 10.0.0.62 | 1008 |
+-----------------+-----------+-----------------------+
1 row in set (0.007 sec)
obclient [tpccdb]> begin;
Query OK, 0 rows affected (0.001 sec)
obclient [tpccdb]> select * from bmsql_oorder where o_w_id=5 and o_d_id=1 and o_id=3000 for update ;
+--------+--------+------+--------+--------------+----------+-------------+---------------------+
| o_w_id | o_d_id | o_id | o_c_id | o_carrier_id | o_ol_cnt | o_all_local | o_entry_d |
+--------+--------+------+--------+--------------+----------+-------------+---------------------+
| 5 | 1 | 3000 | 3000 | NULL | 6 | 1 | 2023-06-20 10:17:58 |
+--------+--------+------+--------+--------------+----------+-------------+---------------------+
1 row in set (0.142 sec)
···
2. 分析会话1 的事务和锁信息
```sql
SELECT inc_num, session_Id, trans_type, trans_mode, part_trans_action,state, ctx_id, trans_id,active_memstore_version mem_version, s.participants, `PARTITION`,trans_consistency,ctx_create_time, expired_time
FROM oceanbase.__all_virtual_trans_stat s
WHERE tenant_id = 1008 AND session_id IN ( 3221779663 );
| inc_num | session_id | trans_type | trans_mode | part_trans_action | state | ctx_id | trans_id | active_memstore_version | participants | partition | trans_consistency | ctx_create_time | expired_time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1360763 | 3221779663 | 2 | normal | 2 | 0 | 3686226 | {hash:2674005738353099637, inc:1360763, addr:“10.0.0.62:2882”, t:1687329462606522} | 2-0-0 | NULL | {tid:1108307720848215, partition_id:5, part_cnt:0} | 0 | 2023-06-21 14:37:42.610 | 2023-06-21 17:24:22.607 |
SELECT l.svr_ip, l.session_Id, l.trans_id, l.`PARTITION`, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 );
| svr_ip | session_id | trans_id | partition | rowkey | ctx_create_time | expired_time | row_lock_addr |
|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221779663 | {hash:2674005738353099637, inc:1360763, addr:“10.0.0.62:2882”, t:1687329462606522} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:1},{“INT”:3000}] | 2023-06-21 14:37:42.610 | 2023-06-21 17:24:22.607 | 7F28E3298138 |
可以看到有一笔记录,其中 rowkey 的信息就可以定位到表和主键值(5,1,3000)。
- 会话 2 开启事务 ,更新同一笔记录被阻塞。
obclient [tpccdb]> begin;
Query OK, 0 rows affected (0.003 sec)
obclient [tpccdb]> select connection_id(), host_ip(), effective_tenant_id() from bmsql_oorder where o_w_id=5 and o_d_id=1 and o_id=3000 limit 1 ;
+-----------------+-----------+-----------------------+
| connection_id() | host_ip() | effective_tenant_id() |
+-----------------+-----------+-----------------------+
| 3221590376 | 10.0.0.61 | 1008 |
+-----------------+-----------+-----------------------+
1 row in set (0.019 sec)
obclient [tpccdb]> update bmsql_oorder set o_entry_d=now() where o_w_id=5 and o_d_id=1 and o_id=3000 ;
被阻塞。
- 分析锁等待视图。
SELECT w.svr_ip, w.session_id, w.rowkey, w.need_wait, usec_to_time(w.recv_ts) recv_time, usec_to_time(w.lock_ts) lock_time, usec_to_time(w.abs_timeout) abs_timeout, w.try_lock_times, sec_to_time(time_after_recv/1000000) time_after_recv, w.block_session_id, `type`, w.lock_mode, w.total_update_cnt
FROM __all_virtual_lock_wait_stat w;
| svr_ip | session_id | rowkey | need_wait | recv_time | lock_time | abs_timeout | try_lock_times | time_after_recv | block_session_id | type | lock_mode | total_update_cnt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221590376 | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:1},{“INT”:3000}] | 1 | 2023-06-21 15:06:32.328 | 2023-06-21 15:08:01.670 | 2023-06-21 15:23:12.228 | 10 | 00:01:35 | 3221590376 | 0 | 0 | 1 |
这个结果里可以看到多个信息:
- session id
3221590376被阻塞,阻塞的记录rowkey里有表和主键信息 (5,1,3000) 。 - 字段
block_session_id表示的是在这个记录数第一个被阻塞的会话(等待记录锁释放的会话),所以它的值跟session_id一致。 - 这个锁阻塞时间和超时时间都定了,超时时间是租户变量
ob_query_timeout决定。
下面是超时的报错:
obclient [tpccdb]> update bmsql_oorder set o_entry_d=now() where o_w_id=5 and o_d_id=1 and o_id=3000 ;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
超时后,重新发起update 重试一下。
从上面视图里看不到的是后面这个事务具体是被哪个会话事务阻塞了。
根据官网指引,根据这个 rowkey 信息去查 锁持有视图,可以找出源端会话。
SELECT l.svr_ip, l.session_Id, l.trans_id, l.`PARTITION`, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 ) AND rowkey LIKE '%"INT":5},{"INT":1},{"INT":3000}%';
| svr_ip | session_id | trans_id | partition | rowkey | ctx_create_time | expired_time | row_lock_addr |
|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221779663 | {hash:2674005738353099637, inc:1360763, addr:“10.0.0.62:2882”, t:1687329462606522} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:1},{“INT”:3000}] | 2023-06-21 14:37:42.610 | 2023-06-21 17:24:22.607 | 7F28E3298138 |
这里就找出源端会话 3221779663 。
截止到这里,一切还很顺利。
但是,假设在阻塞发生的时候,源端会话事务已经被转储(minor freeze )出去了。上面这个方法就有问题了。
- 发起转储。
sys 租户发起转储。
alter system minor freeze;
转储后,查看锁等待视图依然能看到阻塞信息。我们继续根据 rowkey 信息去 锁持有视图找源端会话。
SELECT l.svr_ip, l.session_Id, l.trans_id, l.`PARTITION`, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 ) AND rowkey LIKE '%"INT":5},{"INT":1},{"INT":3000}%';
此时没有记录。去掉这个查询条件。
SELECT l.svr_ip, l.session_Id, l.trans_id, l.`PARTITION`, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008
依然没有记录。也就是说在 OB 3.2.4 这个版本,当发生转储后,被转储的事务持有的锁记录信息在视图里会消失。
这里间接推测这个锁持有视图的信息取自于 Memtable 的内存。
这一步先分析到这里,具体后续如何定位源端会话就在最后面再分享。
接下来再看目前这个方法在另外一个场景下的问题。
大批量更新事务锁特点
前面从锁持有视图 oceanbase.__all_virtual_trans_lock_stat 里看到事务锁住的记录,初步看这个跟 传统数据库 SQLServer 的锁对象设计思路有点像。再深入想想可能就感觉会有问题。当事务更新了几十万几百万记录的时候,难道会这个视图有几十万几百万记录? 如果真是这样,数据库这个开销也就很大了。
所以,再做一个测试,更新 bmsql_oorder
- 会话 1 更新大批量数据。
obclient [tpccdb]> begin;
Query OK, 0 rows affected (0.000 sec)
obclient [tpccdb]> select connection_id(), host_ip(), effective_tenant_id() from bmsql_oorder where o_w_id=5 limit 1 ;
+-----------------+-----------+-----------------------+
| connection_id() | host_ip() | effective_tenant_id() |
+-----------------+-----------+-----------------------+
| 3221488132 | 10.0.0.61 | 1008 |
+-----------------+-----------+-----------------------+
1 row in set (0.025 sec)
obclient [tpccdb]> update bmsql_oorder set o_entry_d=now() where o_w_id=5 ;
Query OK, 30013 rows affected (1.929 sec)
Rows matched: 30013 Changed: 30013 Warnings: 0
- 会话 2 更新少数几笔数据。
obclient [tpccdb]> begin;
Query OK, 0 rows affected (0.000 sec)
obclient [tpccdb]> select connection_id(), host_ip(), effective_tenant_id() from bmsql_oorder where o_w_id=5 and o_d_id=1 and o_id=3000 limit 1 ;
+-----------------+-----------+-----------------------+
| connection_id() | host_ip() | effective_tenant_id() |
+-----------------+-----------+-----------------------+
| 3221738961 | 10.0.0.61 | 1008 |
+-----------------+-----------+-----------------------+
1 row in set (0.021 sec)
obclient [tpccdb]> update bmsql_oorder set o_entry_d=now() where o_w_id=5 order by o_d_id desc, o_id desc limit 1;
- 分析锁阻塞。
查找锁阻塞视图信息。
SELECT w.svr_ip, w.session_id, w.rowkey, w.need_wait, usec_to_time(w.recv_ts) recv_time, usec_to_time(w.lock_ts) lock_time, usec_to_time(w.abs_timeout) abs_timeout, w.try_lock_times, sec_to_time(time_after_recv/1000000) time_after_recv, w.block_session_id, `type`, w.lock_mode, w.total_update_cnt
FROM __all_virtual_lock_wait_stat w;
| svr_ip | session_id | rowkey | need_wait | recv_time | lock_time | abs_timeout | try_lock_times | time_after_recv | block_session_id | type | lock_mode | total_update_cnt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221738961 | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:10},{“INT”:3002}] | 1 | 2023-06-21 15:45:34.912 | 2023-06-21 15:46:33.964 | 2023-06-21 16:02:14.812 | 7 | 00:01:00 | 3221738961 | 0 | 0 | 2 |
从上面看出阻塞的记录的 rowkey 信息是:{“INT”:5},{“INT”:10},{“INT”:3002} 。
从锁持有视图里根据这个 rowkey 信息查看一下。
SELECT l.svr_ip, l.session_Id, l.trans_id, l.PARTITION, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 ) AND rowkey LIKE ‘%“INT”:5},{“INT”:10},{“INT”:3002}%’;
返回记录为 0 。这个为什么没有找到第一个会话的事务锁记录呢?
这里我们再看看哪些会话在这个表上持有锁记录。正常来说,应该是返回第一个会话的记录。
SELECT l.svr_ip, l.session_Id, l.trans_id, l.`PARTITION`, l.rowkey, l.ctx_create_time, l.expired_time, conv(l.row_lock_addr,10,16) row_lock_addr
FROM oceanbase.__all_virtual_trans_lock_stat l
WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 )
ORDER BY row_lock_addr DESC LIMIT 5 ;
记录非常多,所以排序取最后 5 笔记录。
| svr_ip | session_id | trans_id | partition | rowkey | ctx_create_time | expired_time | row_lock_addr |
|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221488132 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:2},{“INT”:860}] | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 | 7F2A29272B50 |
| 10.0.0.61 | 3221488132 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:2},{“INT”:859}] | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 | 7F2A292729F0 |
| 10.0.0.61 | 3221488132 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:2},{“INT”:858}] | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 | 7F2A29272890 |
| 10.0.0.61 | 3221488132 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:2},{“INT”:857}] | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 | 7F2A29272730 |
| 10.0.0.61 | 3221488132 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | {tid:1108307720848215, partition_id:5, part_cnt:0} | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:2},{“INT”:856}] | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 | 7F2A292725D0 |
从这个结果里看排在后面的并不是期望的数据。 有多种可能,也可能是这个排序并不一定跟记录顺序一致。
不过先看看有多少记录。
mysql> select count(*) FROM oceanbase.__all_virtual_trans_lock_stat l
-> WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 );
+----------+
| count(*) |
+----------+
| 4234 |
+----------+
1 row in set (0.42 sec)
mysql> select count(*) FROM oceanbase.__all_virtual_trans_lock_stat l WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 );
+----------+
| count(*) |
+----------+
| 5688 |
+----------+
1 row in set (0.40 sec)
mysql> select count(*) FROM oceanbase.__all_virtual_trans_lock_stat l WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 );
+----------+
| count(*) |
+----------+
| 5718 |
+----------+
1 row in set (0.36 sec)
mysql> select count(*) FROM oceanbase.__all_virtual_trans_lock_stat l WHERE TENANT_ID=1008 AND table_id IN (1108307720848215 );
+----------+
| count(*) |
+----------+
| 5869 |
+----------+
1 row in set (0.38 sec)
反复统计表上锁记录,发现数量一直在变化,维持在 6000 以内。实际上会话1 事务更新的记录数是 30013 笔。
这也说明 OB 并没有把事务修改的所有记录都记录在 视图 oceanbase.__all_virtual_trans_lock_stat 中。推测其原因是认为这样没有必要。实现逻辑可能是在记录上有未提交事务的信息,但是不需要专门取维护一个锁对象。如果这个事务在这个记录上没有阻塞后续会话,那么不维护这个锁对象也没关系。而第二个事务来更新同一笔记录时,发现记录上有事务信息时,就自己注册了一个锁阻塞记录信息,并将自己记录未等待该记录上的最早的那个会话 ID (也就是字段 block_session_id ) 信息。在有些数据库里,有延迟加锁的技术,可能跟这个类似。
既然 OB 里锁阻塞发生的时候能知道记录上的事务信息,那推测以后就有某个视图可以展示这个信息。目前这个版本 OB 只是把这个源端事务信息写到 OBServer 的运行日志里。这个信息就是 ctx_id 信息。从而为定位锁阻塞问题提供了新的途径。
大批量更新的事务更容易引起转储。当转储发生后,已有的这些记录所在的锁信息都会从视图里消失。除非后期有会话再次更新里面的记录成功(即又将数据写入到 memtable 内存中了)。
定位锁阻塞问题新方法
- 首先找到被阻塞的会话 ID 。
这里测试的时候,我提前把会话id通过 connection_id() 取出来了,是为了便于后期分析理解。在真实的生产问题里,运维一般是从会话列表里定位这个会话 ID。 或者直接从锁等待视图里取。
SELECT w.svr_ip, w.session_id, w.rowkey, w.need_wait, usec_to_time(w.recv_ts) recv_time, usec_to_time(w.lock_ts) lock_time, usec_to_time(w.abs_timeout) abs_timeout, w.try_lock_times, sec_to_time(time_after_recv/1000000) time_after_recv, w.block_session_id, `type`, w.lock_mode, w.total_update_cnt
FROM __all_virtual_lock_wait_stat w;
| svr_ip | session_id | rowkey | need_wait | recv_time | lock_time | abs_timeout | try_lock_times | time_after_recv | block_session_id | type | lock_mode | total_update_cnt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.0.0.61 | 3221738961 | table_id=1108307720848215 rowkey_object=[{“INT”:5},{“INT”:10},{“INT”:3002}] | 1 | 2023-06-21 16:06:15.807 | 2023-06-21 16:06:15.860 | 2023-06-21 16:22:55.707 | 1 | 00:00:06 | 3221738961 | 0 | 0 | 2 |
生产环境大面积阻塞的时候,这里记录会非常多。那么就看 block_session_id ,如果很多会话的 block_session_id 一样,说明是被相同的事务阻塞。
这里找到 session id 3221738961。
- 根据会话ID 找到会话的事务上下文 ID :
ctx_id。
SELECT inc_num, session_Id, trans_type, trans_mode, part_trans_action,state, ctx_id, trans_id,active_memstore_version mem_version, s.participants, `PARTITION`,trans_consistency,ctx_create_time, expired_time
FROM oceanbase.__all_virtual_trans_stat s
WHERE tenant_id = 1008 AND session_id IN ( 3221738961 );
| inc_num | session_id | trans_type | trans_mode | part_trans_action | state | ctx_id | trans_id | active_memstore_version | participants | partition | trans_consistency | ctx_create_time | expired_time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 38603642 | 3221738961 | 2 | normal | 2 | 0 | 3812185 | {hash:8385019362885822373, inc:38603642, addr:“10.0.0.61:2882”, t:1687333281980924} | 2-0-0 | NULL | {tid:1108307720848215, partition_id:5, part_cnt:0} | 0 | 2023-06-21 15:45:34.962 | 2023-06-21 18:28:01.981 |
这里找到 ctx_id 3812185 。以及记录所在分区节点 10.0.0.61 。
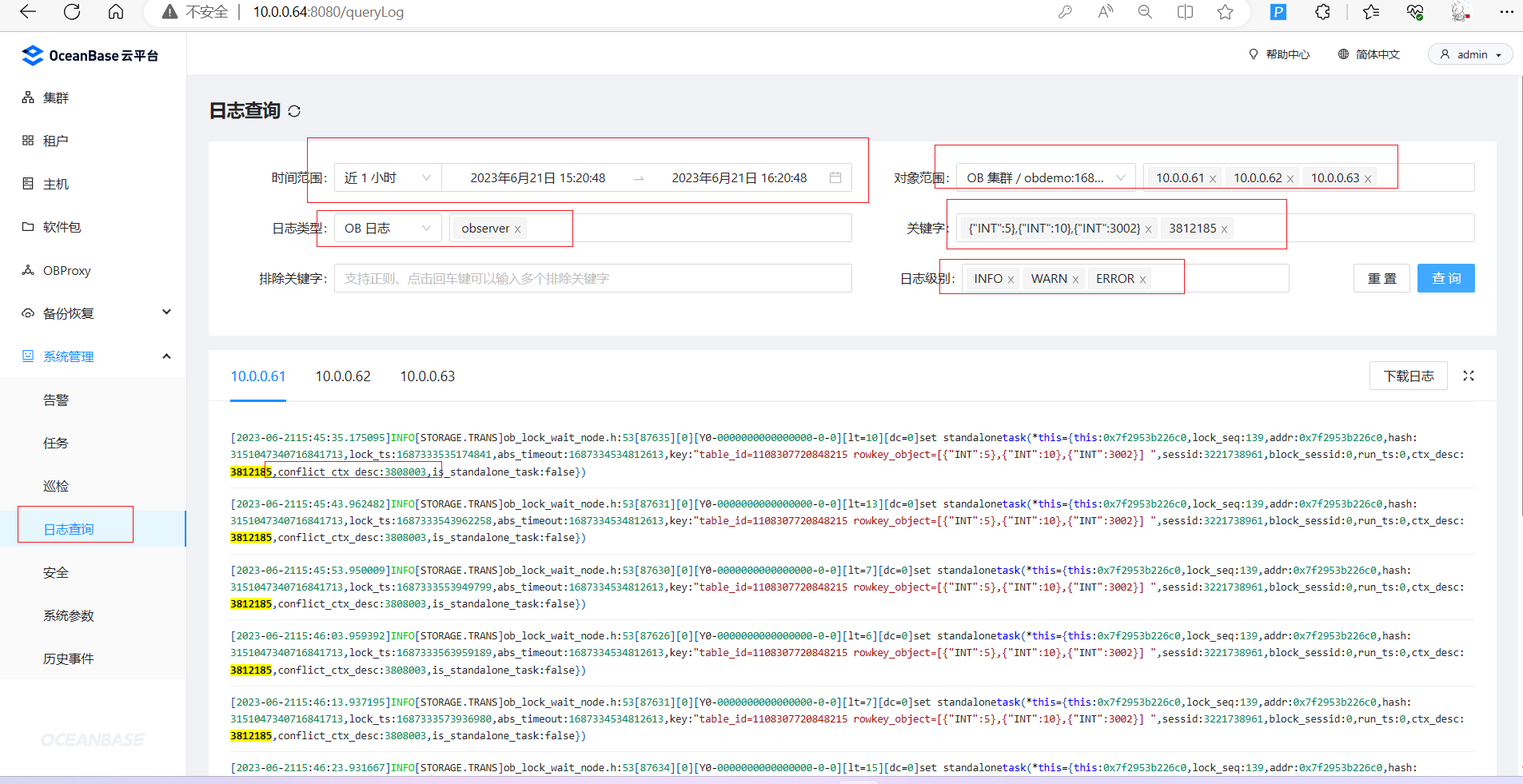
- 根据 ctx_id 和 rowkey 信息 查询 observer.log 最新运行日志
注意,复制rowkey的时候防止编辑器将英文双引号自动变化为中文双引号。必须改回英文双引号。
[admin@server061 log]$ cat observer.log|grep '{"INT":5},{"INT":10},{"INT":3002}' | grep 3812185 | tail -n 5
[2023-06-21 16:14:45.858045] INFO [STORAGE.TRANS] ob_lock_wait_node.h:53 [87634][0][Y0-0000000000000000-0-0] [lt=6] [dc=0] set standalone task(*this={this:0x7f2953b226c0, lock_seq:140, addr:0x7f2953b226c0, hash:3151047340716841713, lock_ts:1687335285857847, abs_timeout:1687335775707032, key:"table_id=1108307720848215 rowkey_object=[{"INT":5},{"INT":10},{"INT":3002}] ", sessid:3221738961, block_sessid:0, run_ts:0, ctx_desc:3812185, conflict_ctx_desc:3808003, is_standalone_task:false})
[2023-06-21 16:14:55.758196] INFO [STORAGE.TRANS] ob_lock_wait_node.h:53 [87634][0][Y0-0000000000000000-0-0] [lt=9] [dc=0] set standalone task(*this={this:0x7f2953b226c0, lock_seq:140, addr:0x7f2953b226c0, hash:3151047340716841713, lock_ts:1687335295757936, abs_timeout:1687335775707032, key:"table_id=1108307720848215 rowkey_object=[{"INT":5},{"INT":10},{"INT":3002}] ", sessid:3221738961, block_sessid:0, run_ts:0, ctx_desc:3812185, conflict_ctx_desc:3808003, is_standalone_task:false})
[2023-06-21 16:15:05.749327] INFO [STORAGE.TRANS] ob_lock_wait_node.h:53 [87635][0][Y0-0000000000000000-0-0] [lt=6] [dc=0] set standalone task(*this={this:0x7f2953b226c0, lock_seq:140, addr:0x7f2953b226c0, hash:3151047340716841713, lock_ts:1687335305749097, abs_timeout:1687335775707032, key:"table_id=1108307720848215 rowkey_object=[{"INT":5},{"INT":10},{"INT":3002}] ", sessid:3221738961, block_sessid:0, run_ts:0, ctx_desc:3812185, conflict_ctx_desc:3808003, is_standalone_task:false})
[2023-06-21 16:15:15.786140] INFO [STORAGE.TRANS] ob_lock_wait_node.h:53 [87634][0][Y0-0000000000000000-0-0] [lt=18] [dc=0] set standalone task(*this={this:0x7f2953b226c0, lock_seq:140, addr:0x7f2953b226c0, hash:3151047340716841713, lock_ts:1687335315785878, abs_timeout:1687335775707032, key:"table_id=1108307720848215 rowkey_object=[{"INT":5},{"INT":10},{"INT":3002}] ", sessid:3221738961, block_sessid:0, run_ts:0, ctx_desc:3812185, conflict_ctx_desc:3808003, is_standalone_task:false})
[2023-06-21 16:15:25.864046] INFO [STORAGE.TRANS] ob_lock_wait_node.h:53 [87633][0][Y0-0000000000000000-0-0] [lt=6] [dc=0] set standalone task(*this={this:0x7f2953b226c0, lock_seq:140, addr:0x7f2953b226c0, hash:3151047340716841713, lock_ts:1687335325863837, abs_timeout:1687335775707032, key:"table_id=1108307720848215 rowkey_object=[{"INT":5},{"INT":10},{"INT":3002}] ", sessid:3221738961, block_sessid:0, run_ts:0, ctx_desc:3812185, conflict_ctx_desc:3808003, is_standalone_task:false})
这个记录会反复在刷,是被阻塞的事务会定时去轮询尝试更新记录导致。从里面可以看到冲突的事务信息:conflict_ctx_desc:3808003 。
- 根据冲突事务 ID 反查事务信息。
SELECT inc_num, session_Id, trans_type, trans_mode, part_trans_action,state, ctx_id, trans_id,active_memstore_version mem_version, s.participants, `PARTITION`,trans_consistency,ctx_create_time, expired_time
FROM oceanbase.__all_virtual_trans_stat s
WHERE tenant_id = 1008 AND ctx_id = 3808003 ;
| inc_num | session_id | trans_type | trans_mode | part_trans_action | state | ctx_id | trans_id | active_memstore_version | participants | partition | trans_consistency | ctx_create_time | expired_time |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 38630957 | 3221488132 | 2 | normal | 2 | 0 | 3808003 | {hash:10924511975819362434, inc:38630957, addr:“10.0.0.61:2882”, t:1687333350353620} | 2-0-0 | NULL | {tid:1108307720848215, partition_id:5, part_cnt:0} | 0 | 2023-06-21 15:43:10.189 | 2023-06-21 18:29:10.354 |
从结果可知源端会话 ID 是 3221488132 。
很多研发同学可能没有权限登录 OB 服务器。但是可以通过 OCP 的日志查询功能。不得不说,企业版 OCP 这个日志查询功能非常实用! ![]()
总结
OB 企业版 3.2.4 版提供了事务和锁相关的三个视图,从这三个视图里能看到 OB 事务和锁的一些特征。 官网也给出简便的定位锁阻塞问题的方法,但是这个方法只适用于一部分场景。本文最后发现的从 OB 运行日志定位锁阻塞问题的方法很可能是当前版本唯一能适用于所有的场景的方法。虽然 OB的运行日志因为信息量巨大,对普通用户的可读性还不好,不过借助于 OCP 的日志查询功能,以及 OB 锁的一些关键信息(关键字),通过日志 线索和 相关 OB 锁视图 定位锁问题还是非常方便和精准的。
在这个试验里还有些场景没有尝试,比如说分布式事务场景、死锁的场景等等。可能会有一些新的特点,也可能当前结论还不严谨。欢迎大家尝试,留言交流。
最后补充一下,官网对这三个视图的介绍太过于简单,很多字段看不明白意思。比如说: __all_virtual_trans_stat 的 字段 state trans_mode trans_type 取值含义。
OB 在业务租户里提供视图 gv$lock gv$ gv$lock_wait_stat ,通过查看定义可以看出跟上面 锁两个视图有关系。但没有视图 __all_virtual_trans_stat 对应的视图信息。感觉企业版 3.2.4 这里视图还不够完善。所以没有从业务租户视角分析。
注意:查看 gv$lock 的视图定义后,千万不要到 SYS 租户里执行那个 DDL。否则会导致业务租户里 gv$lock 无法再使用。后续的MySQL 租户也不能使用这个视图了。估计是视图的实现 BUG 。