

本节接前面分享在资源不足的情况下部署的 OB 集群 的使用问题,仅用于学习研究 OB 和 OCP 的运维原理。
有问题欢迎留言讨论。
问题现象
OB 集群从单副本扩容到三副本时报错。
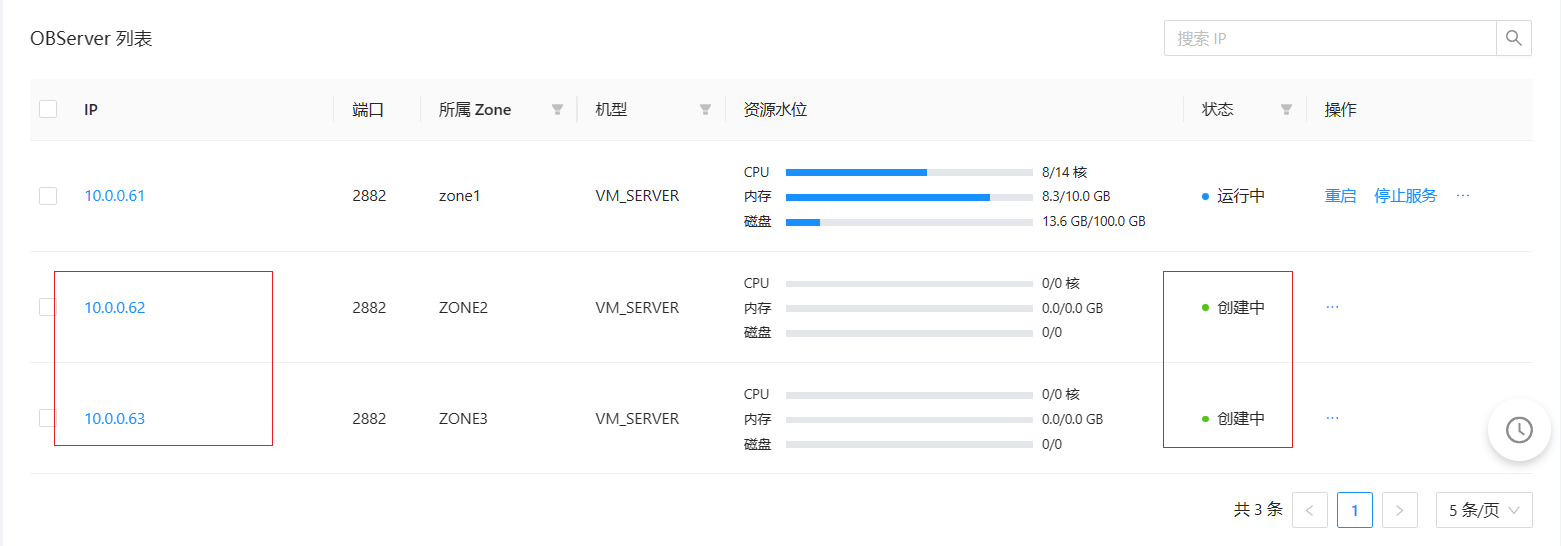
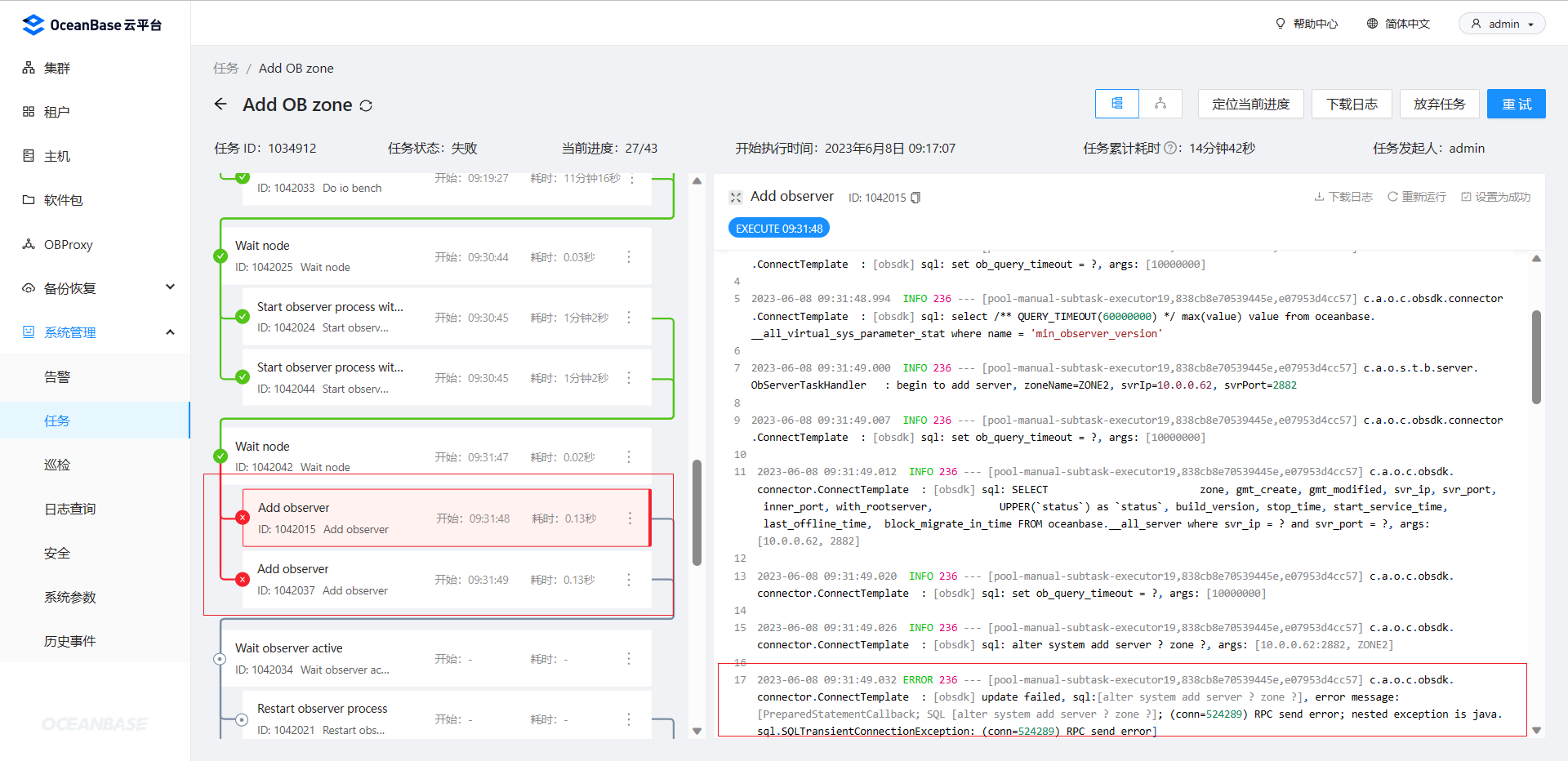
报错信息是:RPC send error
问题分析
- 查看 zone 信息
SELECT * FROM `__all_zone` az
WHERE name IN ('idc', 'region');
| gmt_create | gmt_modified | zone | name | value | info |
|---|---|---|---|---|---|
| 2023-05-16 12:32:49.662 | 2023-06-06 10:36:14.766 | zone1 | idc | 0 | HZ |
| 2023-05-16 12:32:49.662 | 2023-05-16 12:32:49.662 | zone1 | region | 0 | ZJ |
| 2023-06-08 09:17:11.774 | 2023-06-08 09:17:18.119 | ZONE2 | idc | 0 | HZ |
| 2023-06-08 09:17:11.774 | 2023-06-08 09:17:18.119 | ZONE2 | region | 0 | ZJ |
| 2023-06-08 09:17:15.984 | 2023-06-08 09:17:18.152 | ZONE3 | idc | 0 | SH |
| 2023-06-08 09:17:15.984 | 2023-06-08 09:17:18.152 | ZONE3 | region | 0 | SH |
- 查看节点信息
SELECT zone, gmt_create, gmt_modified, svr_ip, svr_port, inner_port, with_rootserver, UPPER(`status`) as `status`, build_version, stop_time, start_service_time, last_offline_time, block_migrate_in_time
FROM oceanbase.__all_server
| zone | gmt_create | gmt_modified | svr_ip | svr_port | inner_port | with_rootserver | status | version | stop_time | start_service_time | last_offline_time |
|---|---|---|---|---|---|---|---|---|---|---|---|
| zone1 | 2023-05-16 12:32:39.355 | 2023-05-26 15:39:20.405 | 10.0.0.61 | 2,882 | 2,881 | 1 | ACTIVE | 3.2.4.1_101000052023 | 1970-01-01 08:00:00.000 | 2023-05-16 12:50:40.217 | 1970-01-01 08:00:00.000 |
新增的节点没有添加成功。
- 查看最近的集群事件
select gmt_create , module , event, name1 , value1 , name2, value2, name3, value3 , rs_svr_ip
from `__all_rootservice_event_history` areh
WHERE 1=1
order by gmt_create desc limit 10;
| gmt_create | module | event | name1 | value1 | name2 | value2 | name3 | value3 | rs_svr_ip |
|---|---|---|---|---|---|---|---|---|---|
| 2023-06-08 09:31:46.663 | root_service | add_server | ret | -4121 | arg | {servers:[10.0.0.63:2882], zone:ZONE3, force_stop:false, op:0} | 10.0.0.61 | ||
| 2023-06-08 09:31:46.515 | root_service | add_server | ret | -4121 | arg | {servers:[10.0.0.62:2882], zone:ZONE2, force_stop:false, op:0} | 10.0.0.61 | ||
| 2023-06-08 09:17:18.154 | root_service | alter_zone | ret | 0 | sql_text | alter system alter zone ‘ZONE3’ set, region = ‘SH’, idc = ‘SH’ | 10.0.0.61 | ||
| 2023-06-08 09:17:18.154 | zone | alter_zone | zone | ZONE3 | region | SH | idc | SH | 10.0.0.61 |
| 2023-06-08 09:17:18.122 | root_service | alter_zone | ret | 0 | sql_text | alter system alter zone ‘ZONE2’ set, region = ‘ZJ’, idc = ‘HZ’ | 10.0.0.61 | ||
| 2023-06-08 09:17:18.121 | zone | alter_zone | zone | ZONE2 | region | ZJ | idc | HZ | 10.0.0.61 |
| 2023-06-08 09:17:17.056 | root_service | start_zone | ret | 0 | sql_text | alter system start zone ‘ZONE3’ | 10.0.0.61 | ||
| 2023-06-08 09:17:17.056 | zone | start_zone | zone | ZONE3 | 10.0.0.61 | ||||
| 2023-06-08 09:17:15.987 | root_service | add_zone | ret | 0 | sql_text | alter system add zone ‘ZONE3’ region ‘SH’ | 10.0.0.61 | ||
| 2023-06-08 09:17:15.987 | zone | add_zone | zone | ZONE3 | 10.0.0.61 |
官网查询错误代码 4121 .
在 RS 节点 10.0.0.61 的 rootservice.log 里搜索到错误 4121 . 跟上面事件日志表内容一致。
- 查看进程监听端口
[admin@server062 log]$ ps -ef|grep observer
admin 3062 1 2 09:30 ? 00:01:07 /home/admin/oceanbase/bin/observer -i ens192 -p 2881 -P 2882 -n obdemo -z ZONE2 -d /home/admin/oceanbase/store/obdemo -l info -orootservice_list=10.0.0.61:2882:2881,config_additional_dir=/data/log1/obdemo/etc2,/data/1/obdemo/etc3,cluster_id=1680747946,
admin 66194 43306 0 10:14 pts/5 00:00:00 grep --color=auto observer
[admin@server062 log]$ logout
[root@server062 ~]# netstat -ntlp |grep 3062
[root@server062 ~]#
没有看到进程开启监听端口。
在节点 10.0.0.62 的 observer.log 里搜索到 错误 4002
[2023-06-08 09:30:48.395482] WDIAG [COMMON] ob_tenant_mgr.cpp:986 [3062][0][Y0-0000000000000000-0-0] [lt=6] [dc=0][errcode=-4002] invalid argument(ret=-4002, tenant_id=1, lower_limit=-2996
962918, upper_limit=-3596355502)
[2023-06-08 09:30:48.395527] ERROR issue_dba_error (ob_log.cpp:2322) [3062][0][Y0-0000000000000000-0-0] [lt=31] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the
internal errcode(errcode=-4002, file="ob_server.cpp", line_no=1480, info="Fail to set tenant mem limit")
[2023-06-08 09:30:48.395545] EDIAG [SERVER] ob_server.cpp:1480 [3062][0][Y0-0000000000000000-0-0] [lt=16] [dc=0][errcode=-4002] Fail to set tenant mem limit(ret=-4002) BACKTRACE:0x1142dc68 0x1141f093 0x6243ff9 0x6243b1f 0x62437db 0x6243373 0xd08853c 0xd074dcc 0xd06c1a6 0x6241d73 0x7fa108984555 0x62407d9
[2023-06-08 09:30:48.395652] ERROR issue_dba_error (ob_log.cpp:2322) [3062][0][Y0-0000000000000000-0-0] [lt=103] [dc=0][errcode=-4388] Unexpected internal error happen, please checkout the internal errcode(errcode=-4002, file="ob_server.cpp", line_no=309, info="init multi tenant fail")
[2023-06-08 09:30:48.395660] EDIAG [SERVER] ob_server.cpp:309 [3062][0][Y0-0000000000000000-0-0] [lt=7] [dc=0][errcode=-4002] init multi tenant fail(ret=-4002) BACKTRACE:0x1142dc68 0x1141f
093 0x6243ff9 0x6243b1f 0x62437db 0x6243373 0xd074ffa 0xd06cca3 0x6241d73 0x7fa108984555 0x62407d9
这里面有个信息比较可疑:ret=-4002, tenant_id=1, lower_limit=-2996 962918, upper_limit=-3596355502 。
租户 ID=1 就是 sys 租户,sys 租户的内存是在 [2G,3G] 。这里显示的却是个负值。而进程的启动参数里没有看到内存相关的参数,并进程的监听端口也还没有看到,结合日志,多方面信息说明这个进程还没有走完启动流程。而原因很可能就是默认的内存参数设置导致进程 sys 租户的值是个负数,从而启动失败。
直到原因后改为手动启动进程。一方面复制已有的进程启动参数,同时到 OB 节点 10.0.0.61 上面查看已有的 内存相关的参数,附加到这个进程后面。
[admin@server061 oceanbase]$ hostname -i
10.0.0.61
[admin@server061 oceanbase]$ strings etc/observer.config.bin |grep memory
__min_full_resource_pool_memory=536870912
memory_chunk_cache_size=512M
system_memory=2G
memory_limit=10G
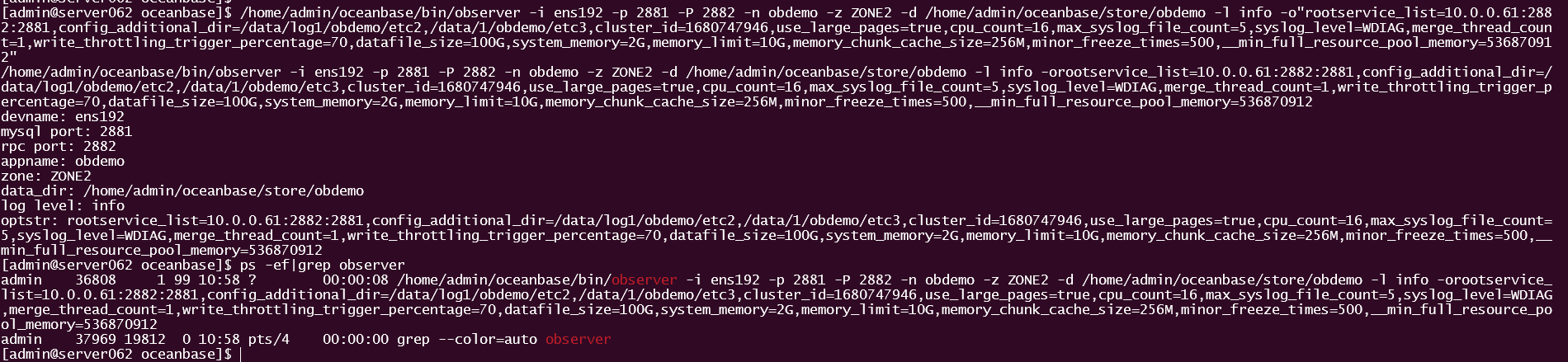
在 10.0.0.62 上杀掉已有的 observer 进程后,手动启动 observer 进程。
su - admin
cd /home/admin/oceanbase
/home/admin/oceanbase/bin/observer -i ens192 -p 2881 -P 2882 -n obdemo -z ZONE2 -d /home/admin/oceanbase/store/obdemo -l info -o"rootservice_list=10.0.0.61:2882:2881,config_additional_dir=/data/log1/obdemo/etc2,/data/1/obdemo/etc3,cluster_id=1680747946,use_large_pages=true,cpu_count=16,max_syslog_file_count=5,syslog_level=WDIAG,merge_thread_count=1,write_throttling_trigger_percentage=70,datafile_size=100G,system_memory=2G,memory_limit=10G,memory_chunk_cache_size=256M,minor_freeze_times=500,__min_full_resource_pool_memory=536870912"
[admin@server062 oceanbase]$ netstat -ntlp | grep 36808
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:2881 0.0.0.0:* LISTEN 36808/observer
tcp 0 0 0.0.0.0:2882 0.0.0.0:* LISTEN 36808/observer
此时进程监听启动成功。同样的方法在 10.0.0.63 节点操作,注意启动参数ZONE为 ZONE3 。
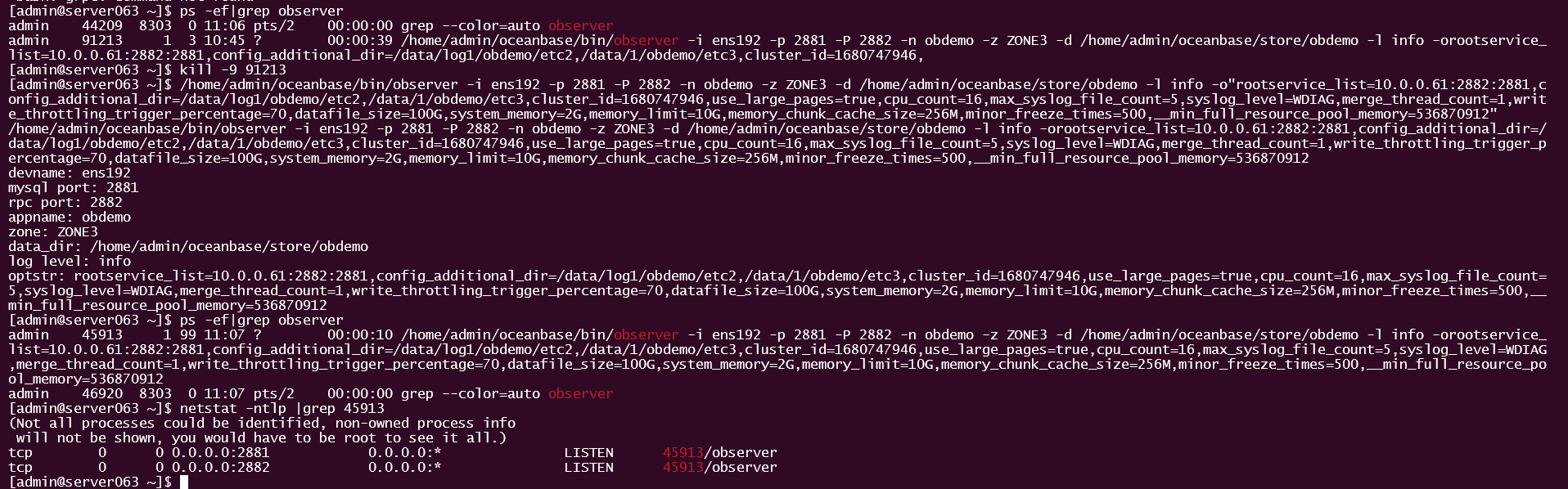
- 重试 OCP 里失败的子任务。
最终 OCP 任务成功。
成功后再去检查 10.0.0.62/63 节点上进程和参数,已经跟 OB 集群现有节点的方式保持一致了。
[admin@server063 oceanbase]$ netstat -ntlp |grep 90815
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:2881 0.0.0.0:* LISTEN 90815/observer
tcp 0 0 0.0.0.0:2882 0.0.0.0:* LISTEN 90815/observer
[admin@server063 oceanbase]$ strings etc/observer.config.bin
use_large_pages=true
_enable_oracle_priv_check=True
major_compact_trigger=500
minor_freeze_times=500
merge_thread_count=1
all_server_list=10.0.0.61:2882,10.0.0.62:2882,10.0.0.63:2882
__min_full_resource_pool_memory=536870912
min_observer_version=3.2.4.1
memory_chunk_cache_size=256M
max_syslog_file_count=5
syslog_level=WDIAG
obconfig_url=http://10.0.0.64:8080/services?Action=ObRootServiceInfo&User_ID=alibaba&UID=ocpmaster&ObRegion=obdemo
cluster_id=1680747946
cluster=obdemo
rootservice_list=10.0.0.61:2882:2881
_partition_balance_strategy=standard
enable_one_phase_commit=False
cpu_count=16
system_memory=2G
memory_limit=10G
zone=ZONE3
devname=ens192
mysql_port=2881
rpc_port=2882
config_additional_dir=/data/log1/obdemo/etc2
datafile_size=100G
data_dir=/home/admin/oceanbase/store/obdemo
[admin@server063 oceanbase]$
总结
OB 集群扩容逻辑简单来说就是 在新结点上安装 OB 软件,启动 OBServer 进程,然后加入到已有 OB 集群里。
这里出现问题的原因推测是 OCP 在启动新节点 OBServer 进程的时候,只传递了 RS 参数和相关目录参数,但是没有带入 OB 集群之前部署时用到的自定义内存参数。在我这个 资源很少的节点上,没有带上自定义的内存参数,OBServer 节点自然会启动失败。
而解决的办法,就是在失败的地方,手动启动 OBServer 进程,然后继续 OB 的集群扩容任务。