蓝色的云
2023 年5 月 25 日 11:20
#1
【 使用环境 】测试环境
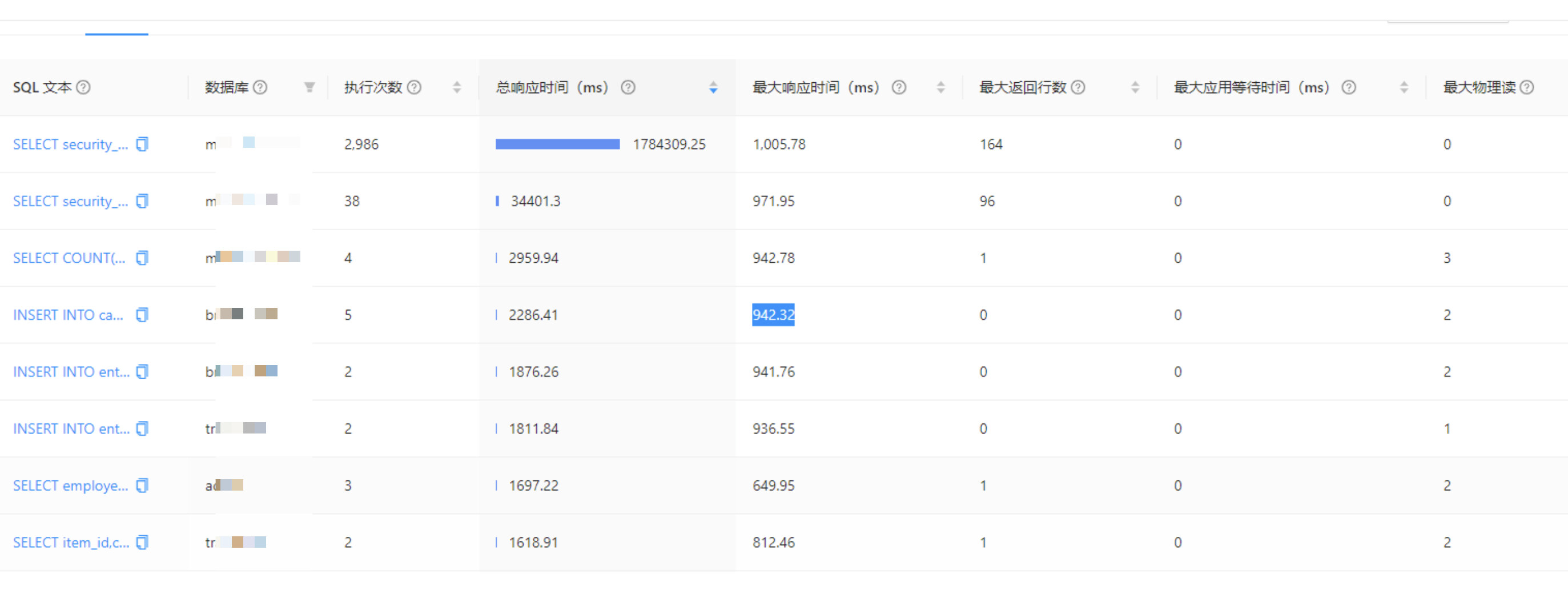
数据库操作期间,并没有频繁操作时,会在某个时间点突然所有操作都变得很慢:
时间点:9:50 左右
排查:
怀疑是 MINI_MERGE 导致,但时间点有点都不上:
这下无从下手排查了,提了一份 rootservice 节点的 observer.log.wf,希望能给出一些排查意见
【附件】observer.log.wf.20230525095435240.zip (1.4 MB)
蓝色的云
2023 年5 月 25 日 11:38
#4
谢谢!
补充一个信息:
热海
2023 年5 月 25 日 15:07
#5
执行下面这个sql查看一下这5次insert的执行情况: select * from gv$sql_audit where query_sql like ‘xxx’
蓝色的云
2023 年5 月 25 日 15:19
#6
应该是 GV$OB_SQL_AUDIT?
select * from GV$OB_SQL_AUDIT WHERE QUERY_SQL LIKE “INSERT INTO xxx%”;
请问下我该关注哪个字段?
热海
2023 年5 月 25 日 15:52
#7
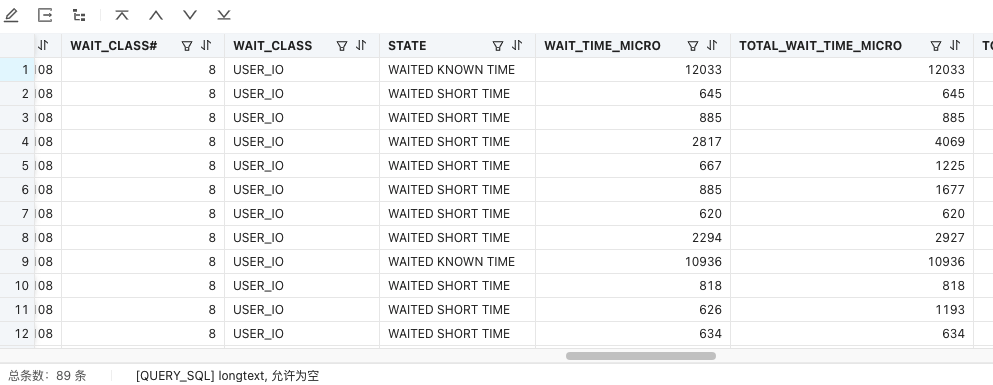
需要关注的字段我稍后给你整理一下列出来,为了更准确地排查问题,麻烦取一下insert into等待150ms的sql,然后取到的sql_audit全部字段都发出来可以吗?
热海
2023 年5 月 25 日 15:58
#8
sql_audit的字段说明文档在:ob_sql_audit字段说明
字段名称
类型
是否可以为 NULL
描述
EVENT
varchar(64)
NO
最长等待事件名称
P1TEXT
varchar(64)
NO
等待事件参数 1
P1
bigint(20) unsigned
NO
等待事件参数 1 的值
P2TEXT
varchar(64)
NO
等待事件参数 2
P2
bigint(20) unsigned
NO
等待事件参数 2 的值
P3TEXT
varchar(64)
NO
等待事件参数 3
P3
bigint(20) unsigned
NO
等待事件参数 3 的值
LEVEL
bigint(20)
NO
等待事件的级别
WAIT_CLASS_ID
bigint(20)
NO
等待事件所属的 Class ID
WAIT_CLASS#
bigint(20)
NO
等待事件所属的 Class 的下标
WAIT_CLASS
varchar(64)
NO
等待事件所属的 Class 名称
STATE
varchar(19)
NO
等待事件的状态
WAIT_TIME_MICRO
bigint(20)
NO
该等待事件所等待的时间,单位:微秒
TOTAL_WAIT_TIME_MICRO
bigint(20)
NO
执行过程所有等待的总时间,单位:微秒
蓝色的云
2023 年5 月 25 日 16:04
#9
额。。再执行了 select,刚刚那几条耗时的记录查不到了
热海
2023 年5 月 25 日 16:38
#10
好的。没关系,当再有这个问题的时候,你再提供一下就行,我这里会持续跟进这个问题
1 个赞
恩怨似云烟
2023 年5 月 26 日 16:35
#11
SQL 诊断的 SQL 明细 TraceID 在 select * from GV$ob_sql_audit where TRACE_ID =‘YB42C0A8150B-0005FBDFA6E754B3-0-0’ 查询不到结果是什么情况,给的TraceID 不对?
君野
2023 年5 月 26 日 17:01
#12
可能淘汰掉了,调大点 ob_sql_audit_percentage 试试
蓝色的云
2023 年5 月 26 日 17:47
#14
你好。
Archive.zip (12.5 KB)
劳烦协助排查下,感谢!
张雨齐
2023 年5 月 26 日 20:45
#15
业务有新发布上线时,会有新 SQL 产生,在有些情况下可能存在一些未经 review 的慢 SQL 在生产上占用了过多资源,影响了核心业务。此时需要排查数据库中的慢 SQL 来定位问题所在,并进行后续优化处理。
通过 OCP 查找慢 SQL。可以在 OCP 的 TOP SQL 页面查看最近一段时间耗时、执行次数最高的查询,从高到低进行排序,对于计划走错的 SQL直接在线绑定,具体操作请参见 可疑 SQL 诊断 ;对于需要限流的 SQL,需要结合业务研发的确认信息,定位可以进行限流的SQL。
在命令行查找慢 SQL。
查询特定租户下消耗 CPU 最多的 top sql。
SELECT
sql_id,
avg(execute_time) avg_exec_time,
count(*) cnt,
avg(execute_time - TOTAL_WAIT_TIME_MICRO) cpu_time,
RETRY_CNT,QUEUE_TIME,IS_HIT_PLAN
FROM
OCEANBASE.V$OB_SQL_AUDIT
WHERE
tenant_id = 1002
GROUP BY
1
ORDER BY
(avg_exec_time * cnt) desc
limit
5;
其中 EXECUTE_TIME 值,如果值过大,考虑存在等待事件或逻辑读次数异常多。
RETRY_CNT 字段即 retry 次数,如果次数很多,则可能有锁冲突或切主等情况。
QUEUE_TIME 过大,则表明 CPU 资源不够用。
GET_PLAN_TIME 为获取执行计划的时间,如果如果时间很长,一般会伴随 IS_HIT_PLAN=0,表示没有命中 plan。
其他相关查询。OceanBase 提供两张虚拟表 V$OB_SQL_AUDIT,GV$OB_SQL_AUDIT 记录最近一段时间 SQL 执行历史,V$OB_SQL_AUDIT 存储本机的 SQL 执行历史,GV$OB_SQL_AUDIT 存储整个集群的 SQL 执行历史。可以根据需要进行相关查询。
查询 GV$OB_SQL_AUDIT 表,如查询某租户执行时间大于1s (1000000微秒)的 SQL。
SELECT * FROM oceanbase.GV$OB_SQL_AUDIT WHERE tenant_id= <tenantid> AND elapsed_time> 1000000 limit 10;
查询 SQL 执行时间按秒分布的直方图。
SELECT round(elapsed_time/1000000), count(*) FROM oceanbase.V$OB_SQL_AUDIT WHERE tenant_id = <tenant_id> GROUP BY 1;
在 OceanBase 日志中查找慢 SQL。OceanBase 中 SQL 执行时间超过 trace_log_slow_query_watermark (系统参数)的,在 observer 日志中都会打印 slow query 消息,该参数默认值为 100ms。可以通过 observer 日志查找慢 SQL。这种方式没有上述两种方法高效直观,但在一些情况下也有助于一些问题的问题,例如当 sql_audit 中的缓存已经淘汰时。记录慢 SQL 日志的位置:/home/admin/oceanbase/log
看日志中所有的 slow query。fgrep '[slow query]' observer.log |sed -e 's/|/\n/g' | more
根据 trace_id 查询某个 slow query。fgrep "<trace_id>" observer.log |sed -e 's/|/\n/g' | more
在observer.log里搜索慢SQL
https://www.oceanbase.com/docs/common-oceanbase-database-cn-10000000001699942
1 个赞
近墨者
2023 年5 月 27 日 09:27
#17
TEST(慢)与TEST2(快),差在执行时间(execute time),大概差了0.08秒。 SQL一样,PLAH HASH一样,执行计划是本地,且没有rpc,都是返回2行数据,走的索引,且使用的内存资源一样。 执行快的SQL与执行慢的sql除了执行时间,其他都一样。。。
建议根据REQUEST_TIME,通过函数usec_time算出开始时间,根据时间,看看OBSERVER端的负载,比如cpu的使用率;客户端和服务端查查是否有丢包的现象