【 使用环境 】测试环境
【 使用版本 】obce:4.1.0.0 ocp:4.0.3,使用obd部署的集群+prometheus+grafana,并对接到ocp
【问题描述】 prometheus无法查询 node_load1 等主机性能指标
【问题现象及影响】
从host的metrics可以获取 cpu load 等指标
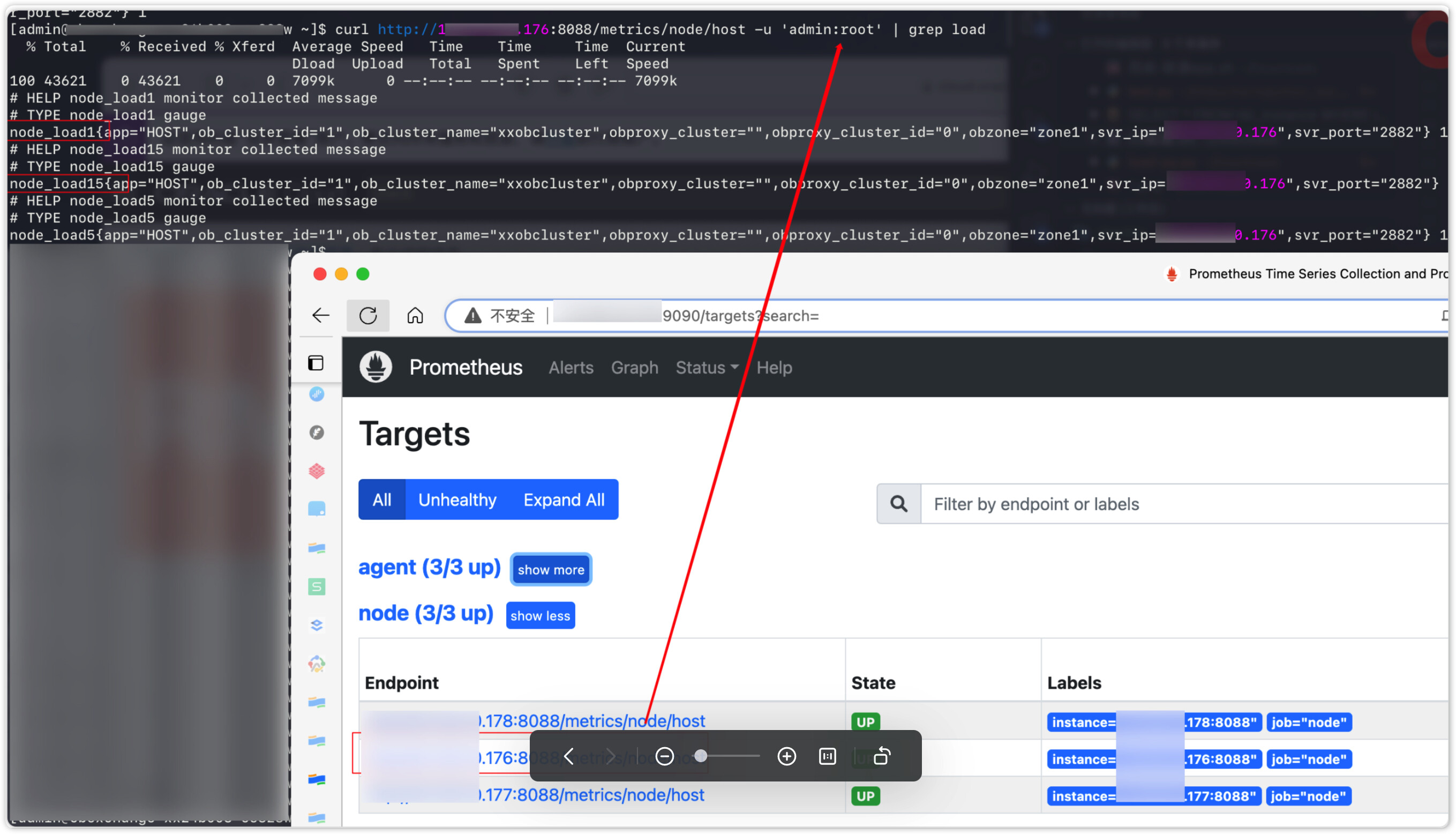
但是在 prometheus 查询不到相关主机指标(cpu_load1等)
【 使用环境 】测试环境
【 使用版本 】obce:4.1.0.0 ocp:4.0.3,使用obd部署的集群+prometheus+grafana,并对接到ocp
【问题描述】 prometheus无法查询 node_load1 等主机性能指标
【问题现象及影响】
从host的metrics可以获取 cpu load 等指标
prom 日志有如下错误:ts=2023-05-24T07:52:04.354Z caller=scrape.go:1604 level=warn component=“scrape manager” scrape_pool=node target=http://xxxxxx:8088/metrics/node/host msg=“Error on ingesting samples that are too old or are too far into the future” num_dropped=119
尝试停止prom,清空prom data目录,启动prom 问题依旧
你好,问下咱们这边是什么原因需要使用prometheus呢,ob生态的ocpexpress和ocp运维工具,对监控信息还是比较完善的。
是哪些功能不满足吗?
准备结合混沌工程压测,grafana 观测更直观
解决方法:
prom 配置文件 node job 添加:
- job_name: node
honor_timestamps: false
然后重启 prom
ocp express 只能监控一个集群