【 使用环境 】测试环境
【 OB or 其他组件 】OB
【 使用版本 】社区版 4.0, 集群模式 1:1:1
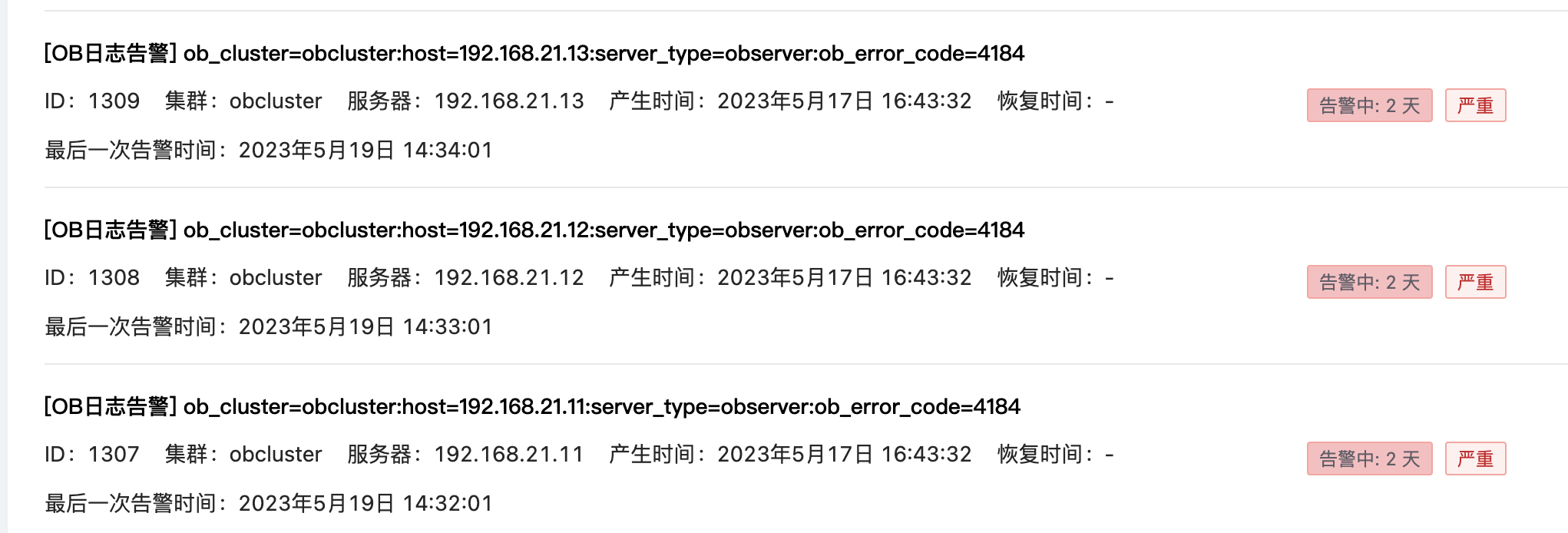
【问题描述】OCP 告警 3 台 observer 均有以下错误日志:
ERROR [SERVER] cal_all_part_disk_size (ob_server_utils.cpp:149) [779011][LogLoop][T0][Y0-0000000000000000-0-0] [lt=5] decide clog disk size failed(ret=-4184, ret=“OB_SERVER_OUTOF_DISK_SPACE”, clog_dir="/data/clog"
【问题现象及影响】
根据日志初步判断是 clog 盘满,进 observer 检索 observer.log:
observer.log.wf.20230519075729410:[2023-05-19 07:53:22.880516] ERROR [SERVER] cal_all_part_disk_size (ob_server_utils.cpp:149) [1448917][LogLoop][T0][Y0-0000000000000000-0-0] [lt=5] decide clog disk size failed(ret=-4184, ret="OB_SERVER_OUTOF_DISK_SPACE", clog_dir="/data/clog", suggested_data_disk_size=858993459200, suggested_data_disk_percentage=0, clog_default_disk_percentage=90, shared_mode=false) BACKTRACE:0xb617e7b 0xb609956 0x3bf0321 0x3bf000f 0x3befe10 0x3befc52 0x3f2380e 0x3f22ff7 0x3f22b7b 0x43f74b5 0x43f7889 0xb5f880c 0xb5f6f5a 0x7fea2a6c12de 0x7fea2a3f2e83
observer.log.wf.20230519075729410:[2023-05-19 07:53:22.880534] ERROR [SERVER] cal_all_part_disk_size (ob_server_utils.cpp:158) [1448917][LogLoop][T0][Y0-0000000000000000-0-0] [lt=17] decide_all_disk_size failed(ret=-4184, ret="OB_SERVER_OUTOF_DISK_SPACE", data_dir="/data/sstable", clog_dir="/data/clog", suggested_data_disk_size=858993459200, suggested_data_disk_percentage=0, data_default_disk_percentage=90, clog_default_disk_percentage=90, shared_mode=false, data_disk_size=858993459200, log_disk_size=279172874240) BACKTRACE:0xb617e7b 0xb609956 0x3d31f43 0x3d31c21 0x3d31a0c 0x3d3183e 0x3f23a9d 0x3f23067 0x3f22b7b 0x43f74b5 0x43f7889 0xb5f880c 0xb5f6f5a 0x7fea2a6c12de 0x7fea2a3f2e83
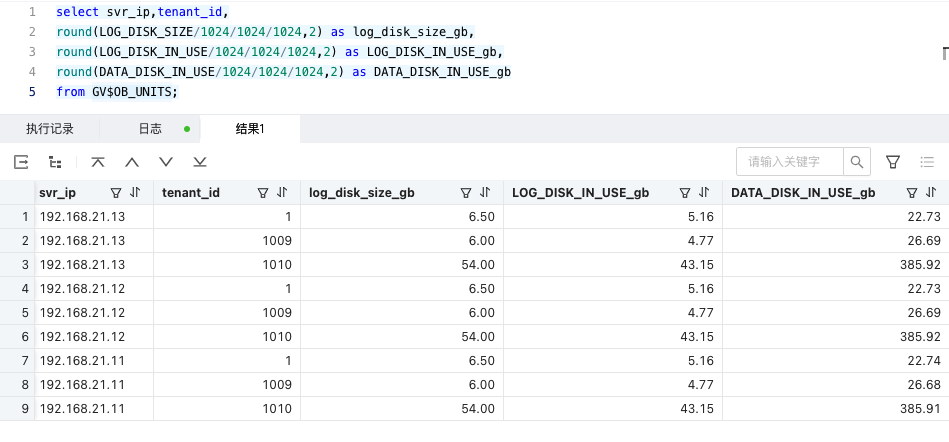
查看服务器磁盘使用情况:
[root@ecs6 log]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 32G 0 32G 0% /dev
tmpfs 32G 84K 32G 1% /dev/shm
tmpfs 32G 73M 32G 1% /run
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/vda2 193G 18G 167G 10% /
/dev/vdb 196G 157G 30G 84% /redo
/dev/vdd 984G 801G 134G 86% /data
/dev/vdc 492G 16G 451G 4% /home/admin/oceanbase
tmpfs 6.3G 0 6.3G 0% /run/user/1001
tmpfs 6.3G 0 6.3G 0% /run/user/0
tmpfs 6.3G 0 6.3G 0% /run/user/1002
[root@ecs log]# df -h /data/clog
Filesystem Size Used Avail Use% Mounted on
/dev/vdb 196G 157G 30G 84% /redo
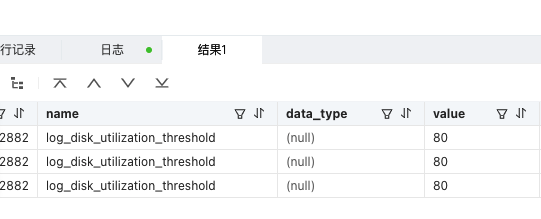
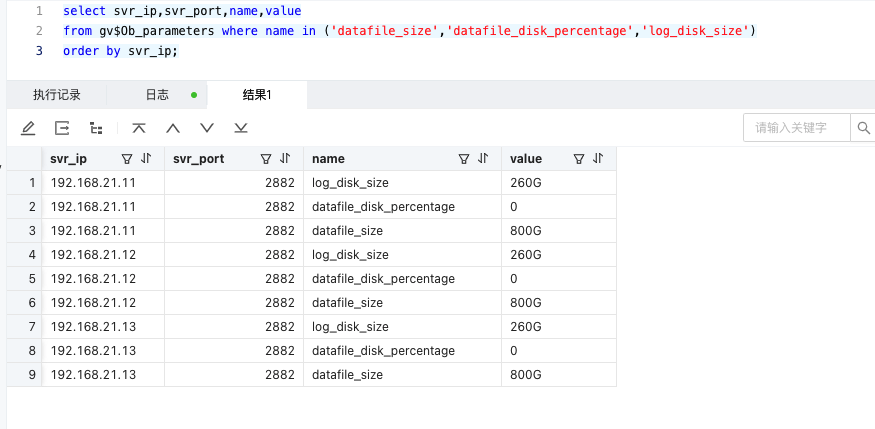
通过 obd cluster edit-config 看了下集群配置:
log_disk_size: 156G
检索了文档关于 「节点日志盘(Clog)空间满」 解决方案:https://www.oceanbase.com/docs/community-observer-cn-10000000000901966
疑问:
1、 clog 盘是否是预占满模式?
2、按节点日志盘(Clog)空间满」 解决方案处理,由 95% 调整到 98%后,告警会恢复正常吗?