

麻烦有空再帮忙看看哈

磁盘 扩容了没 ??? 现在 解决了没




[admin@obdb1 clog]$ du -sh *
52G log_pool
13G tenant_1
12G tenant_1001
104G tenant_1002
[admin@obdb2 clog]$ du -sh *
95G log_pool
4.3G tenant_1
14G tenant_1001
68G tenant_1002
[admin@obdb3 clog]$ du -sh *
52G log_pool
13G tenant_1
12G tenant_1001
104G tenant_1002
通过查询,数据盘和日志盘并未满
select * from oceanbase.__all_unit_config ; - -这个表我看下

select * from v$unit\G 。 执行下 wo 我看看
1、利用gcore工具收集下server信息
gcore pid > core_server.txt
2、先重启zone2,观察合并是否正常,首先看看zone2是否合并正常了,然后看看zone1是否合并上去了,
3、如果重启zone2合并没有完成的话,先把主切到zone3,再重启下zone1
注意:gcore收集过程中可能耗时会很久且需要比较大的容量,不方便收集的话可以直接重启
重启完zone2,sys租户zone2已经合并完成,META$1002租户zone1,zone2也已合并完成,业务租户test_tenant数据量比较大,目前还没啥变化
mysql> select * from dba_ob_tenants;
±----------±------------±------------±---------------------------±---------------------------±------------------±--------------------------------------------±------------------±-------------------±-------±--------------±-------±------------±------------------±-----------------±--------------------±--------------------±--------------------±--------------------±-------------±---------------------------+
| TENANT_ID | TENANT_NAME | TENANT_TYPE | CREATE_TIME | MODIFY_TIME | PRIMARY_ZONE | LOCALITY | PREVIOUS_LOCALITY | COMPATIBILITY_MODE | STATUS | IN_RECYCLEBIN | LOCKED | TENANT_ROLE | SWITCHOVER_STATUS | SWITCHOVER_EPOCH | SYNC_SCN | REPLAYABLE_SCN | READABLE_SCN | RECOVERY_UNTIL_SCN | LOG_MODE | ARBITRATION_SERVICE_STATUS |
±----------±------------±------------±---------------------------±---------------------------±------------------±--------------------------------------------±------------------±-------------------±-------±--------------±-------±------------±------------------±-----------------±--------------------±--------------------±--------------------±--------------------±-------------±---------------------------+
| 1 | sys | SYS | 2023-04-20 19:22:13.538700 | 2023-04-20 19:23:12.766483 | zone1;zone2,zone3 | FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1001 | META$1002 | META | 2023-04-24 11:49:50.934309 | 2023-04-24 11:50:15.342963 | zone1,zone2,zone3 | FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | NULL | NULL | NULL | NULL | NOARCHIVELOG | DISABLED |
| 1002 | test_tenant | USER | 2023-04-24 11:49:50.941679 | 2023-04-24 11:50:15.487715 | zone1,zone2,zone3 | FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3 | NULL | MYSQL | NORMAL | NO | NO | PRIMARY | NORMAL | 0 | 1684322613786151762 | 1684322613786151762 | 1684322613741022480 | 4611686018427387903 | NOARCHIVELOG | DISABLED |
±----------±------------±------------±---------------------------±---------------------------±------------------±--------------------------------------------±------------------±-------------------±-------±--------------±-------±------------±------------------±-----------------±--------------------±--------------------±--------------------±--------------------±-------------±---------------------------+
3 rows in set (0.05 sec)
[admin@obdb1 ~]$ ps -ef |grep obser
admin 258636 1 99 Apr20 ? 69-03:34:35 /data/oceanbase/product/ob/oceanbase/bin/observer
admin 348831 345395 0 19:26 pts/0 00:00:00 grep --color=auto obser
[admin@obdb1 ~]$
[admin@obdb1 ~]$ gcore 258636 > /data/soft/core_server_89_11.txt
[root@obdb2 ~]# ps -ef |grep obser
admin 253477 1 99 May10 ? 10-20:33:13 /data/oceanbase/product/ob/oceanbase/bin/observer
root 389655 268711 0 19:23 pts/0 00:00:00 grep --color=auto obser
[admin@obdb2 ~]$ gcore 253477 > /data/soft/core_server_89_12.txt
[admin@obdb3 ~]$ ps -ef |grep obser
admin 258142 1 99 4月20 ? 40-05:46:57 /data/oceanbase/product/ob/oceanbase/bin/observer
admin 400743 400200 0 19:25 pts/0 00:00:00 grep --color=auto obser
[admin@obdb3 ~]$ gcore 258142 > /data/soft/core_server_89_13.txt
core_server_89_11.txt (21.6 KB)
core_server_89_13.txt (21.3 KB)
core_server_89_12.txt (20.5 KB)
zone1重启过吗,我看1002租户的zone1和1001租户的zone3还是在合并中
麻烦在zone1节点的最新的rootservice.log(如果rs节点还在zone1的话)上grep一下这个看看
select* from __all_server where with_rootserver=‘1’; --确认rs节点
grep “check updating merge status(tenant_id=1001” rootservice.log
grep “check updating merge status(tenant_id=1002” rootservice.log
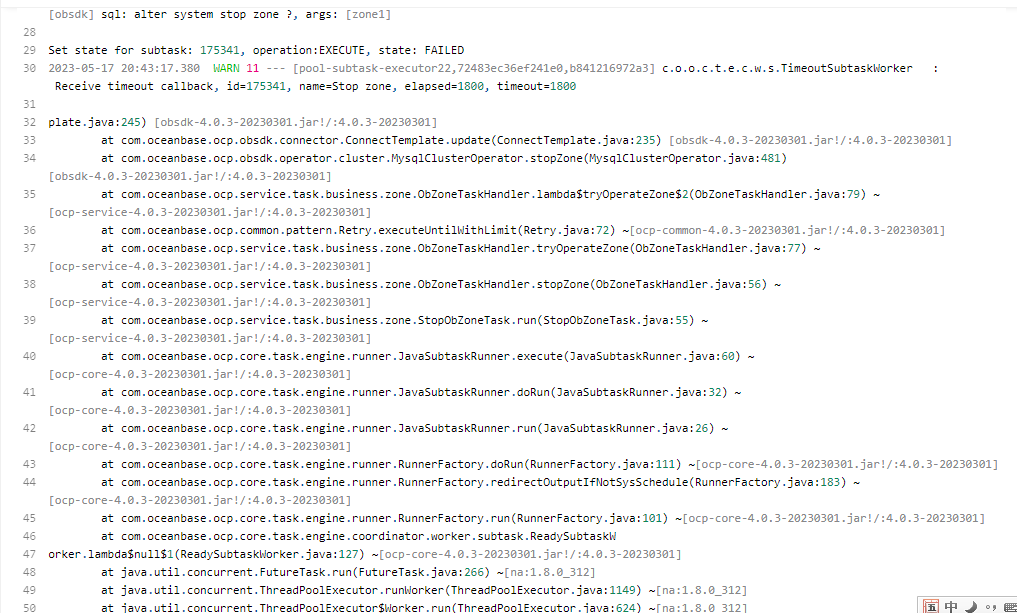
rootservice还在zone1上,zone1重启失败,zone2,zone3都已重启成功了,zone1重启报错信息如下:
grep_1002.log (225.9 KB)
grep_1001.log (1.4 MB)
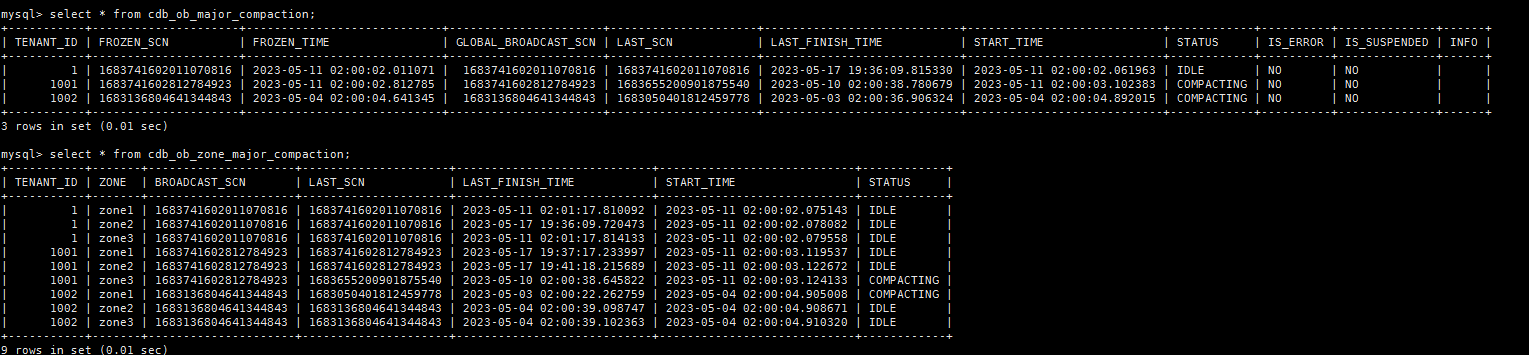
目前合并只剩下zone1的1002租户的合并还卡着,其他的已完成
mysql> select * from GV$OB_COMPACTION_PROGRESS where STATUS!=‘FINISH’;
±-------------±---------±----------±------------±------±--------------------±-------------±-------------------±------------------------±----------±---------------------±------------------±---------------------------±---------------------------±--------------------------------------------------------------------------------------------+
| SVR_IP | SVR_PORT | TENANT_ID | TYPE | ZONE | COMPACTION_SCN | STATUS | TOTAL_TABLET_COUNT | UNFINISHED_TABLET_COUNT | DATA_SIZE | UNFINISHED_DATA_SIZE | COMPRESSION_RATIO | START_TIME | ESTIMATED_FINISH_TIME | COMMENTS |
±-------------±---------±----------±------------±------±--------------------±-------------±-------------------±------------------------±----------±---------------------±------------------±---------------------------±---------------------------±--------------------------------------------------------------------------------------------+
| 10.168.89.11 | 2982 | 1002 | MAJOR_MERGE | zone1 | 1683136804641344843 | NODE_RUNNING | 931 | 127 | 952346359 | 213010574 | 0.69 | 2023-05-04 02:00:05.790398 | 2023-05-18 10:45:05.611463 | SCHEDULER_LOOP:schedule_stats={schedule_cnt:1898, finish_cnt:1898, wait_rs_validate_cnt:0}, |
±-------------±---------±----------±------------±------±--------------------±-------------±-------------------±------------------------±----------±---------------------±------------------±---------------------------±---------------------------±--------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT * FROM oceanbase.CDB_OB_ZONE_MAJOR_COMPACTION;
±----------±------±--------------------±--------------------±---------------------------±---------------------------±-----------+
| TENANT_ID | ZONE | BROADCAST_SCN | LAST_SCN | LAST_FINISH_TIME | START_TIME | STATUS |
±----------±------±--------------------±--------------------±---------------------------±---------------------------±-----------+
| 1 | zone1 | 1684346404473693146 | 1684346404473693146 | 2023-05-18 10:29:58.610514 | 2023-05-18 02:00:07.178597 | IDLE |
| 1 | zone2 | 1684346404473693146 | 1684346404473693146 | 2023-05-18 10:30:08.655121 | 2023-05-18 02:00:07.273926 | IDLE |
| 1 | zone3 | 1684346404473693146 | 1684346404473693146 | 2023-05-18 10:31:30.547959 | 2023-05-18 02:00:07.276787 | IDLE |
| 1001 | zone1 | 1683741602812784923 | 1683741602812784923 | 2023-05-17 19:37:17.233997 | 2023-05-11 02:00:03.119537 | IDLE |
| 1001 | zone2 | 1683741602812784923 | 1683741602812784923 | 2023-05-17 19:41:18.215689 | 2023-05-11 02:00:03.122672 | IDLE |
| 1001 | zone3 | 1683741602812784923 | 1683741602812784923 | 2023-05-18 10:20:14.065675 | 2023-05-11 02:00:03.124133 | IDLE |
| 1002 | zone1 | 1683136804641344843 | 1683050401812459778 | 2023-05-03 02:00:22.262759 | 2023-05-04 02:00:04.905008 | COMPACTING |
| 1002 | zone2 | 1683136804641344843 | 1683136804641344843 | 2023-05-04 02:00:39.098747 | 2023-05-04 02:00:04.908671 | IDLE |
| 1002 | zone3 | 1683136804641344843 | 1683136804641344843 | 2023-05-04 02:00:39.102363 | 2023-05-04 02:00:04.910320 | IDLE |
±----------±------±--------------------±--------------------±---------------------------±---------------------------±-----------+
9 rows in set (0.05 sec)
1、zone1重启失败,是卡在了哪一步重启失败,日志能发下完整的吗。上面的不太看的出。重启前切主了吗。(任务重试是否可以恢复)
2、查询下这个
select svr_ip,zone,status,with_rootserver,build_version,usec_to_time(stop_time) stop_time,usec_to_time(start_service_time) start_time from __all_server;
在stop_zone这一步失败,您说的切主是指把rootservice的主切到其他zone,还是啥,重启时没有切主,重试也无法恢复,应如何切主呢?
restart_zone1_stop_zone.log (14.8 KB)
mysql> select svr_ip,zone,status,with_rootserver,build_version,usec_to_time(stop_time) stop_time,usec_to_time(start_service_time) start_time from __all_server;
±-------------±------±-------±----------------±------------------------------------------------------------------------------------------±---------------------------±---------------------------+
| svr_ip | zone | status | with_rootserver | build_version | stop_time | start_time |
±-------------±------±-------±----------------±------------------------------------------------------------------------------------------±---------------------------±---------------------------+
| 10.168.89.11 | zone1 | ACTIVE | 1 | 4.1.0.0_100000202023040520-0765e69043c31bf86e83b5d618db0530cf31b707(Apr 5 2023 20:26:14) | 1970-01-01 08:00:00.000000 | 2023-04-20 19:25:51.900812 |
| 10.168.89.12 | zone2 | ACTIVE | 0 | 4.1.0.0_100000202023040520-0765e69043c31bf86e83b5d618db0530cf31b707(Apr 5 2023 20:26:14) | 1970-01-01 08:00:00.000000 | 2023-05-17 19:33:39.176109 |
| 10.168.89.13 | zone3 | ACTIVE | 0 | 4.1.0.0_100000202023040520-0765e69043c31bf86e83b5d618db0530cf31b707(Apr 5 2023 20:26:14) | 1970-01-01 08:00:00.000000 | 2023-05-18 10:07:56.432968 |
±-------------±------±-------±----------------±------------------------------------------------------------------------------------------±---------------------------±---------------------------+
ALTER SYSTEM ISOLATE SERVER ‘10.168.89.11:2982’;
执行完切主,zone1重启成功了,我再观察一下
另外,请教一下,如何查询分区在各observer的分布情况,如哪个observer上分布了哪些分区的主副本,应查什么表,__all_virtual_meta_table 这个表在社区版是否没有?

mysql> select * from __all_virtual_meta_table limit 5;
ERROR 1146 (42S02): Table ‘oceanbase.__all_virtual_meta_table’ doesn’t exist
解决了,手动触发了一次合并,也在4分钟内完成了,想咨询下,本次这个问题的原因大概是什么,是因为我操作了什么导致的吗?我们以后该如何避免
1、上述
ALTER SYSTEM ISOLATE SERVER ‘10.168.89.11:2982’; 这个命令为隔离server节点的命令,虽然也会触发切主。
ALTER SYSTEM START SERVER ‘10.168.89.11:2982’; 可以使用这个命令来取消server隔离(2982是自定义的rpc端口吗)。
一般切主命令可以使用这个
ALTER SYSTEM SWITCH ROOTSERVICE {LEADER | FOLLOWER} {zone | server};
2、目前集群合并正常了吗
3、数据分布可以看看这个表DBA_OB_TABLE_LOCATIONS
目前合并正常了,问题的原因还不明确
目前看的话是因为内存数据和磁盘数据不一致导致
解决办法只有重启
好的,谢谢