【 使用环境 】生产环境
【 OB or 其他组件 】ob
【 使用版本 】4.0
【问题描述】
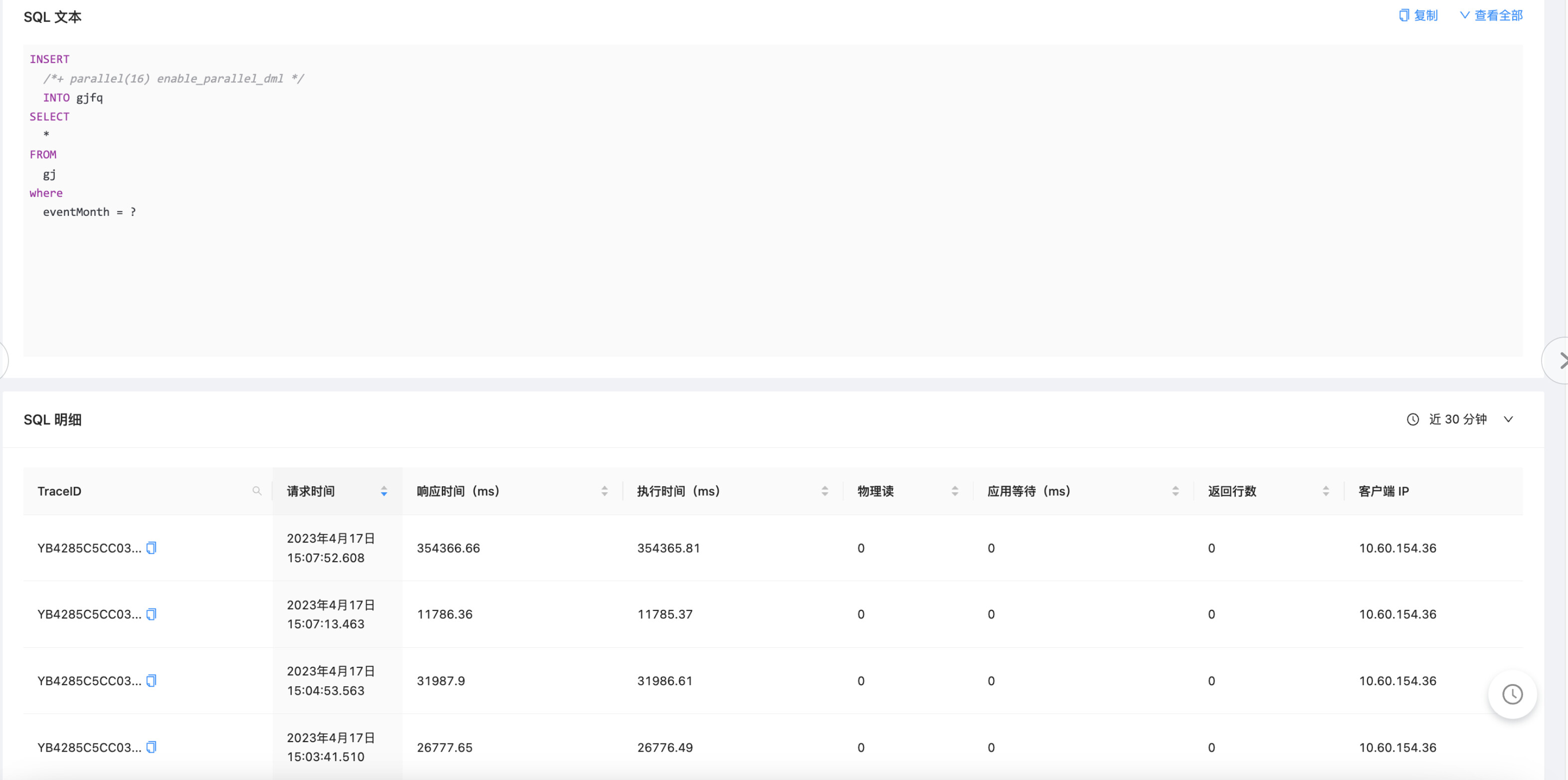
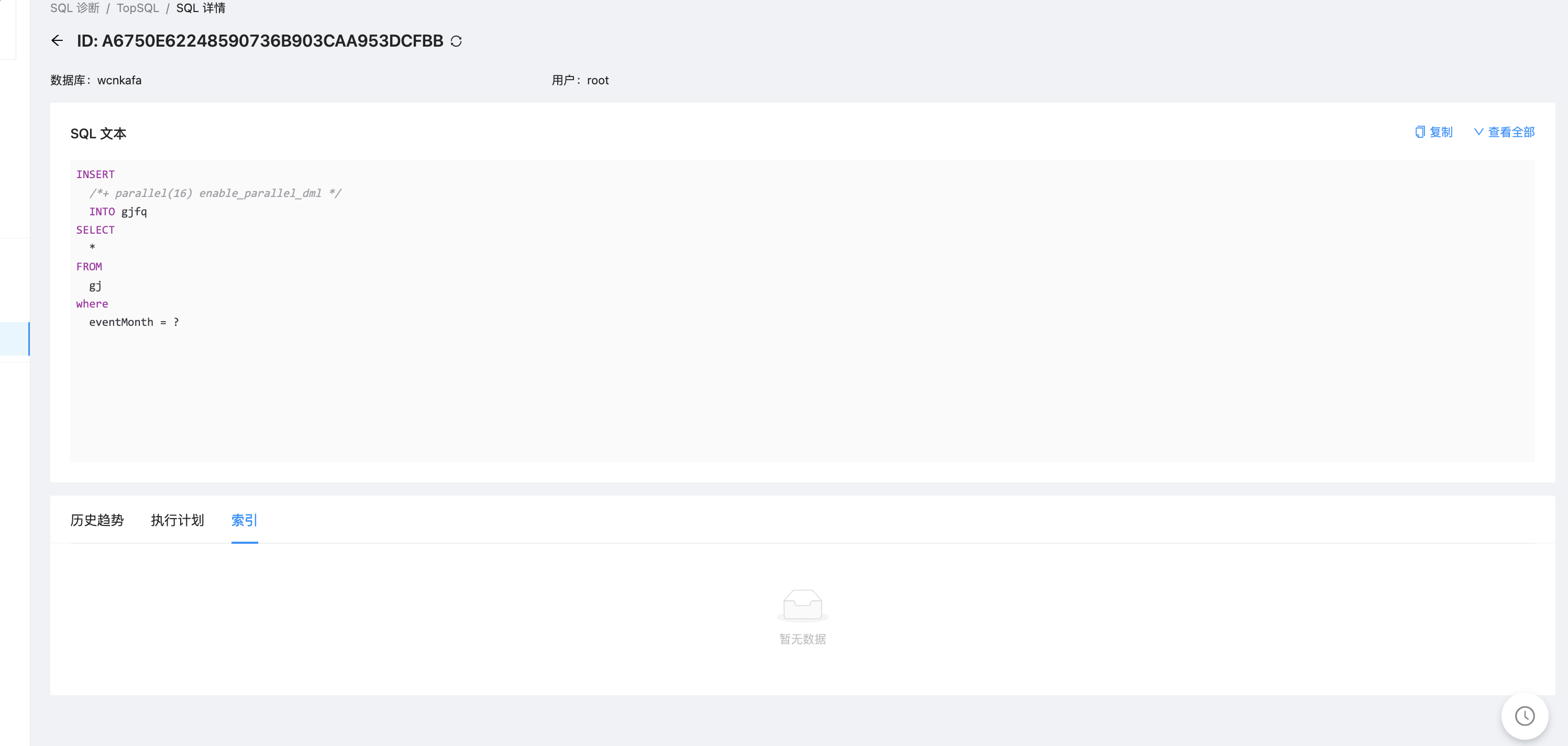
从gj表查询数据后执行插入gjfq(分区表),很卡。
不知道什么原因,麻烦老师帮分析下。
gj表600万
gjfq表400万,两个一级分区,每个对应12个二级分区,按照月份。
【附件】
【 使用环境 】生产环境
【 OB or 其他组件 】ob
【 使用版本 】4.0
【问题描述】
从gj表查询数据后执行插入gjfq(分区表),很卡。
不知道什么原因,麻烦老师帮分析下。
gj表600万
gjfq表400万,两个一级分区,每个对应12个二级分区,按照月份。
【附件】
1 分区键是啥,是不是写的数据跨分区了
2 每次而且写的数据量是不是很大,看下 affected_rows
麻烦提供一下:
1、2张表的结构 show create table xxx \G
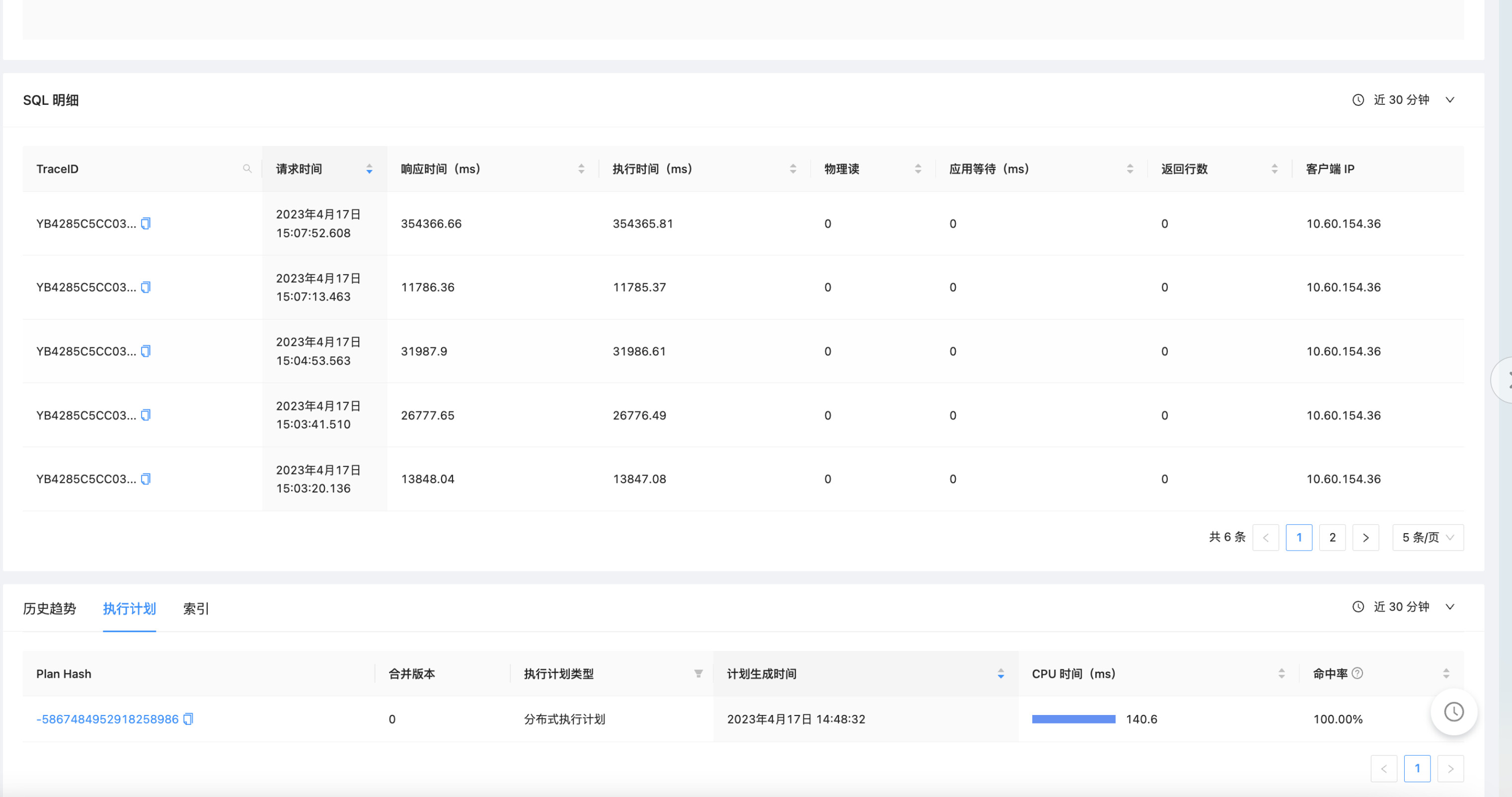
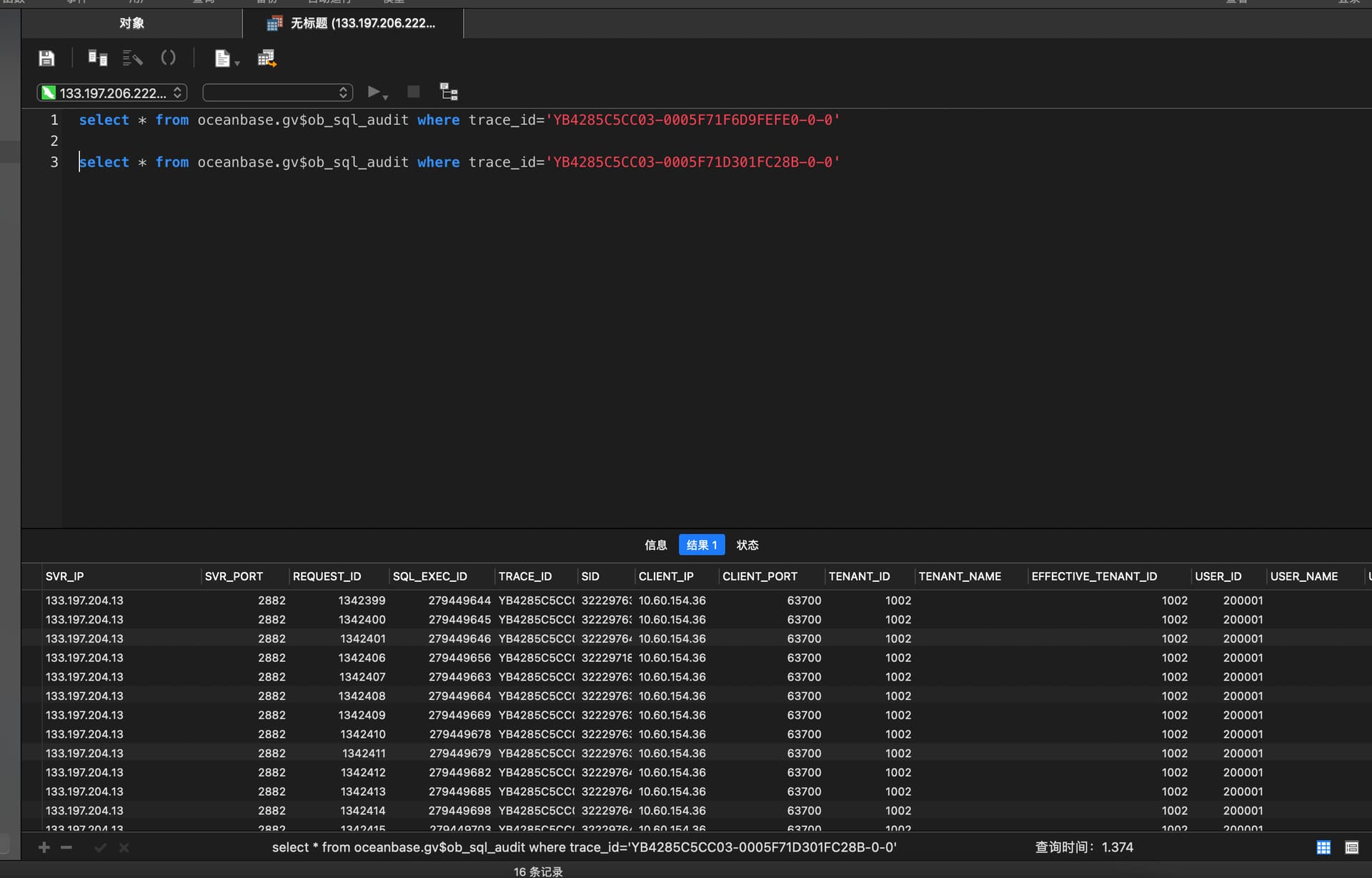
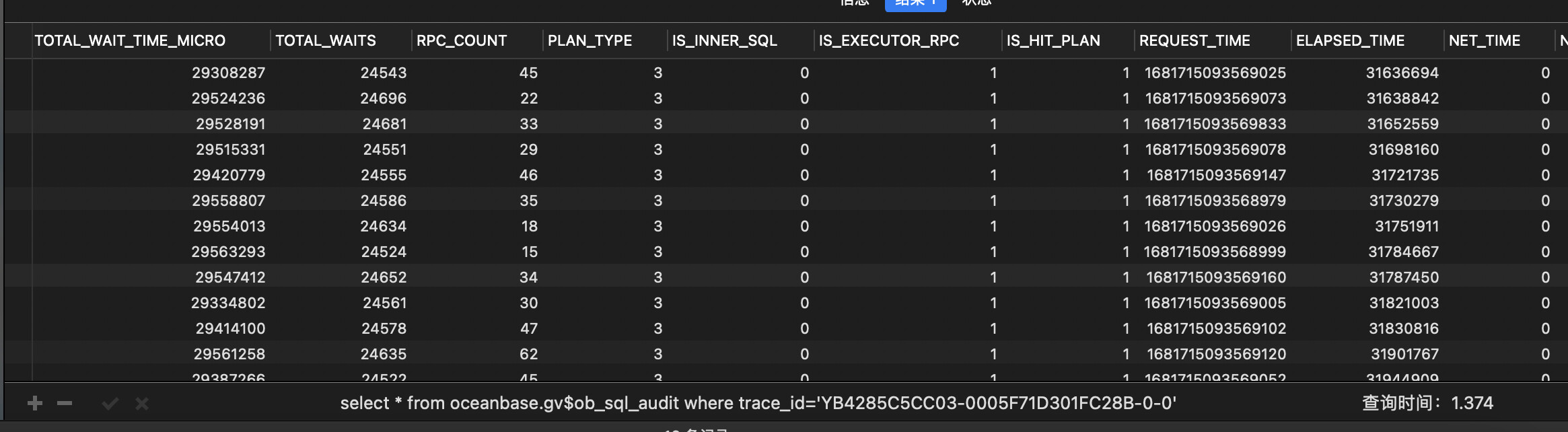
2、根据ocp上sql明细对应的traceid ,执行 select * from gv$ob_sql_audit where trace_id=‘xxx’ \G
3、在insert 时候,是否触发了写入限速(1002替换成我们实际的用户租户ID)
grep “T1002.*report write throttle info” observer.log
partition by range columns(year) subpartition by hash(eventmonth)
插入数量不固定,大概几万左右
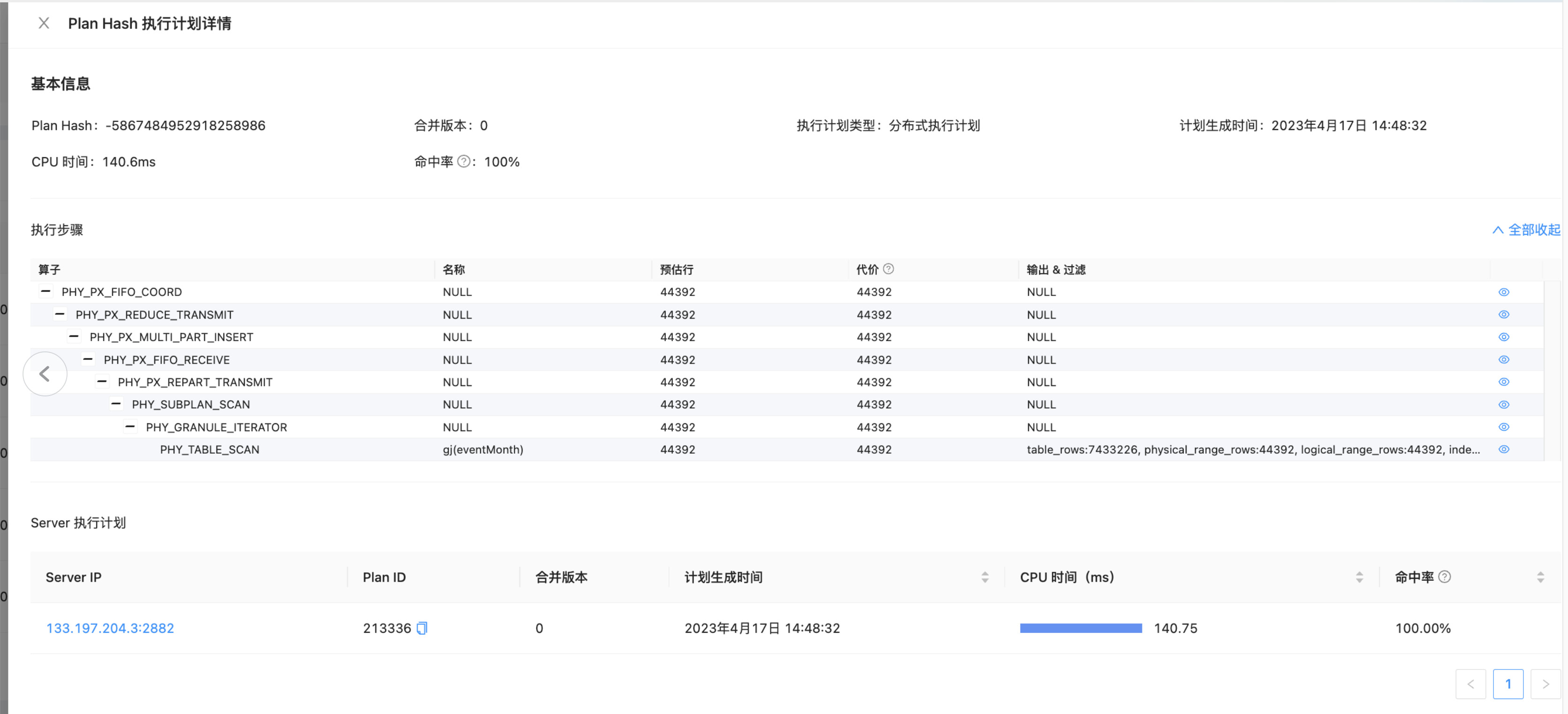
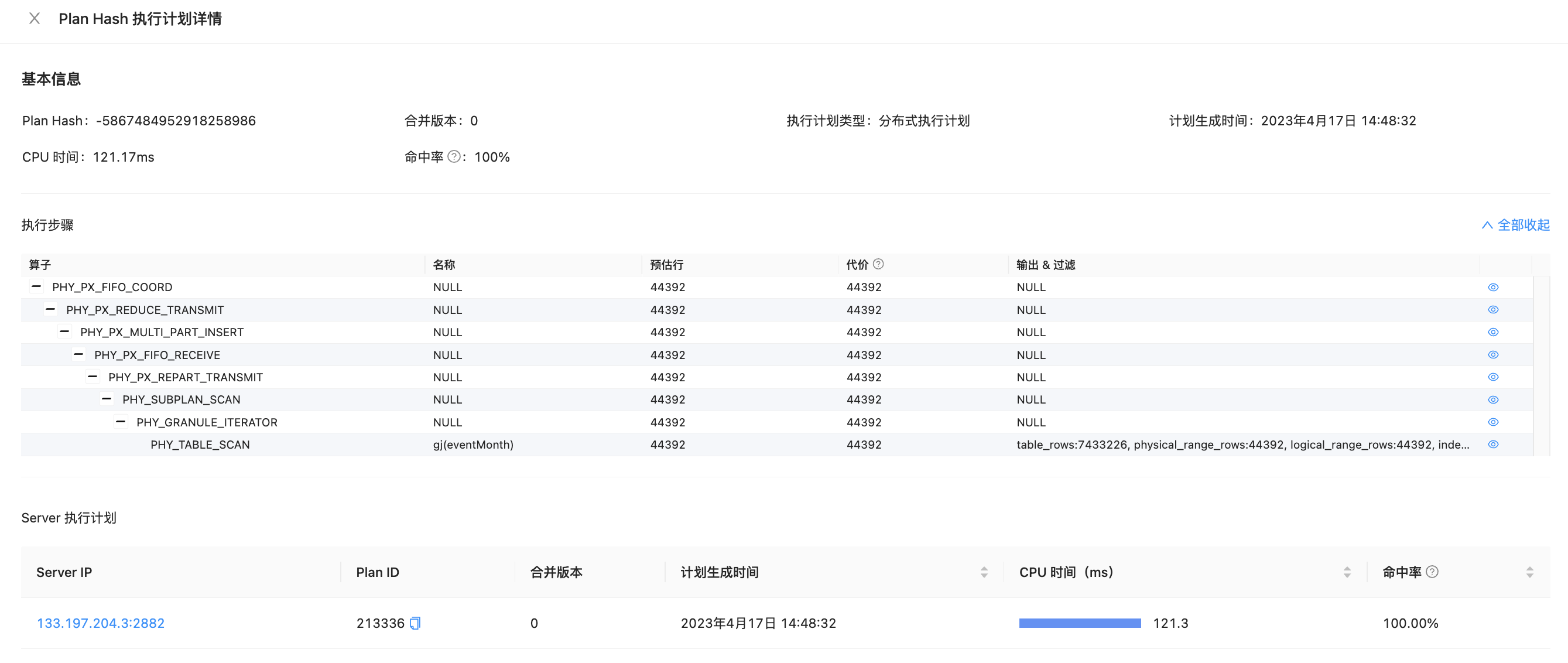
分布式执行计划。表上索引情况是什么样子的哪?
根据ocp上sql明细对应的traceid ,执行 select * from gv$ob_sql_audit where trace_id=‘xxx’ limit 1 \G
麻烦将完整输出贴一下。
上面提供的sql.txt里 QUERY_SQL: 对应的 字段是空,找一个对应我们该帖子中描述慢点sql看看。
根据ocp上面的TraceID查询到的,QUERY_SQL都是空的。
直接查询QUERY_SQL对应的like也没找到记录了。
这里不要写limit 1, 分布式计划执行时,会有多个sql_audit
不加limit 1的话,也无法查询到了,不知道是不是超过保存的时间
估计已经淘汰了,得重新执行,找到traceId 再查
好的,谢谢
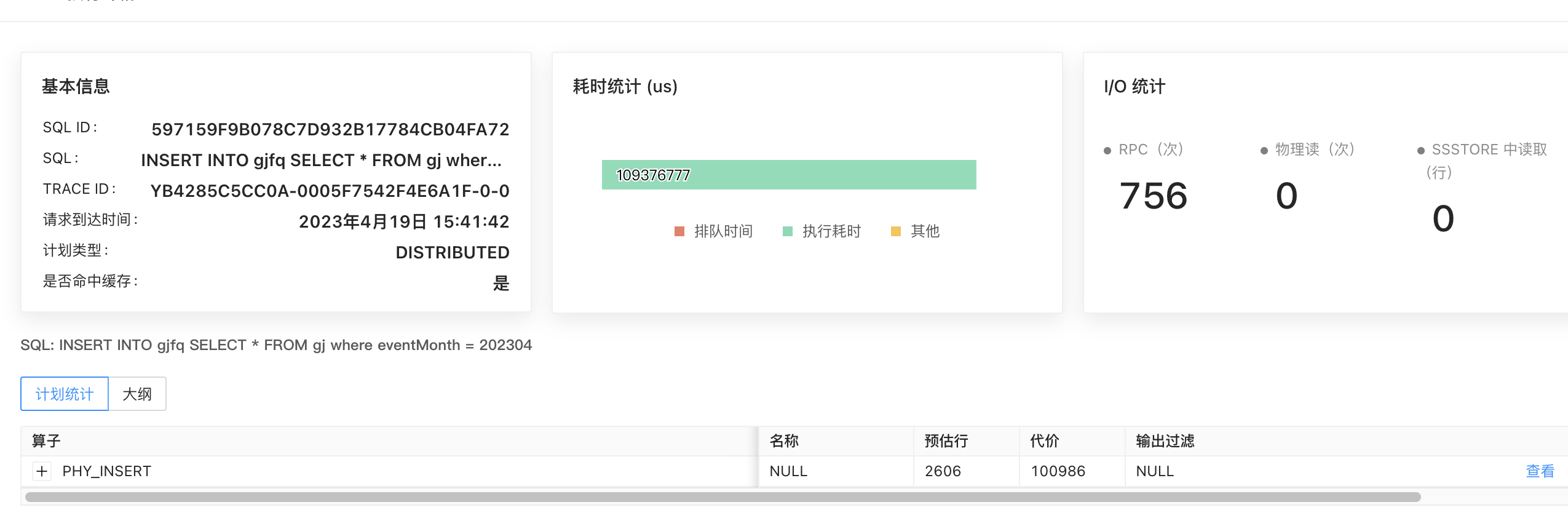
sql_audit 来看只需要600ms,110s 是从哪儿看到的
得找个执行耗时很长的SQL的traceId 对应的sql_audit