【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】社区版4.0
【问题描述】
【复现路径】问题出现前后相关操作
【问题现象及影响】
【附件】
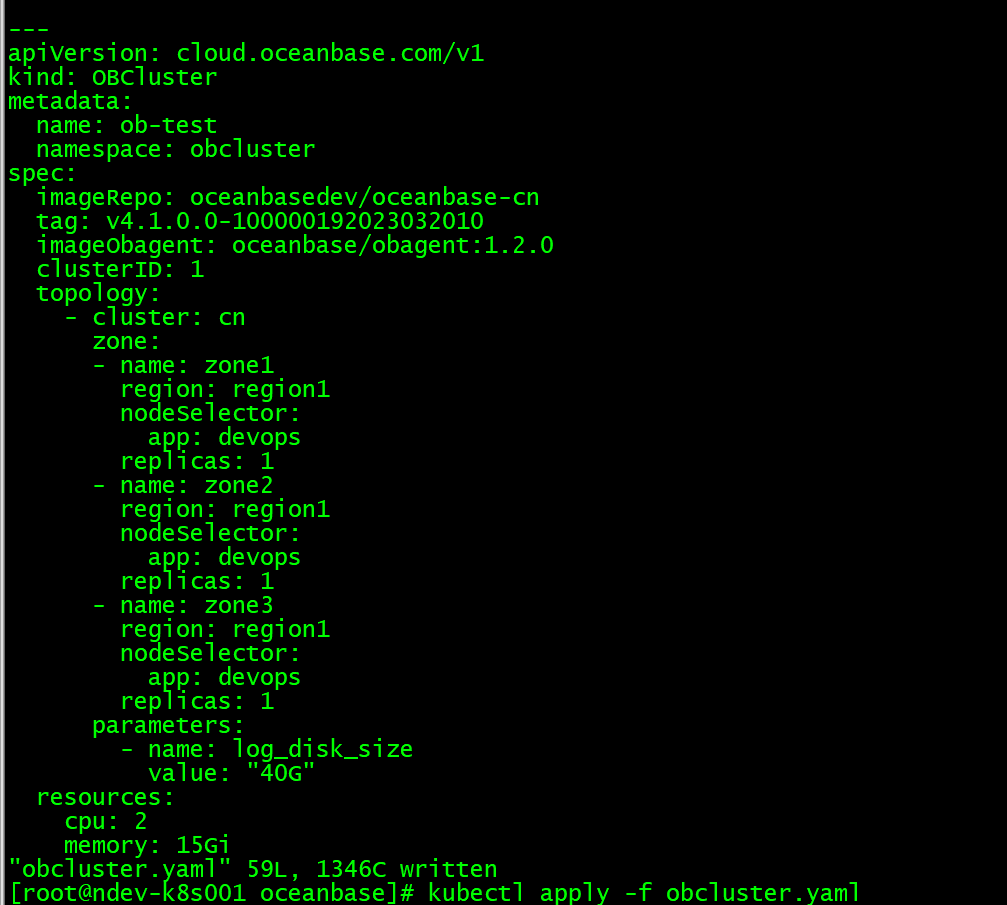
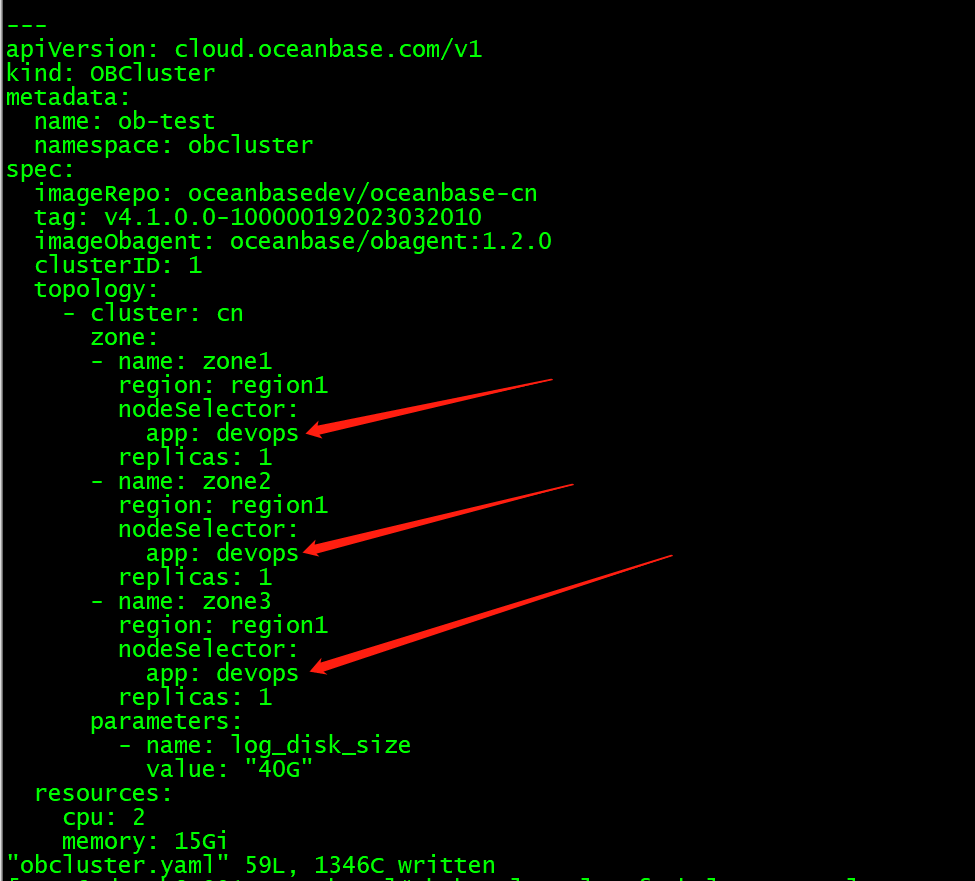
obcluster.yaml文件内容
【 使用环境 】 测试环境
【 OB or 其他组件 】
【 使用版本 】社区版4.0
【问题描述】
【复现路径】问题出现前后相关操作
【问题现象及影响】
【附件】
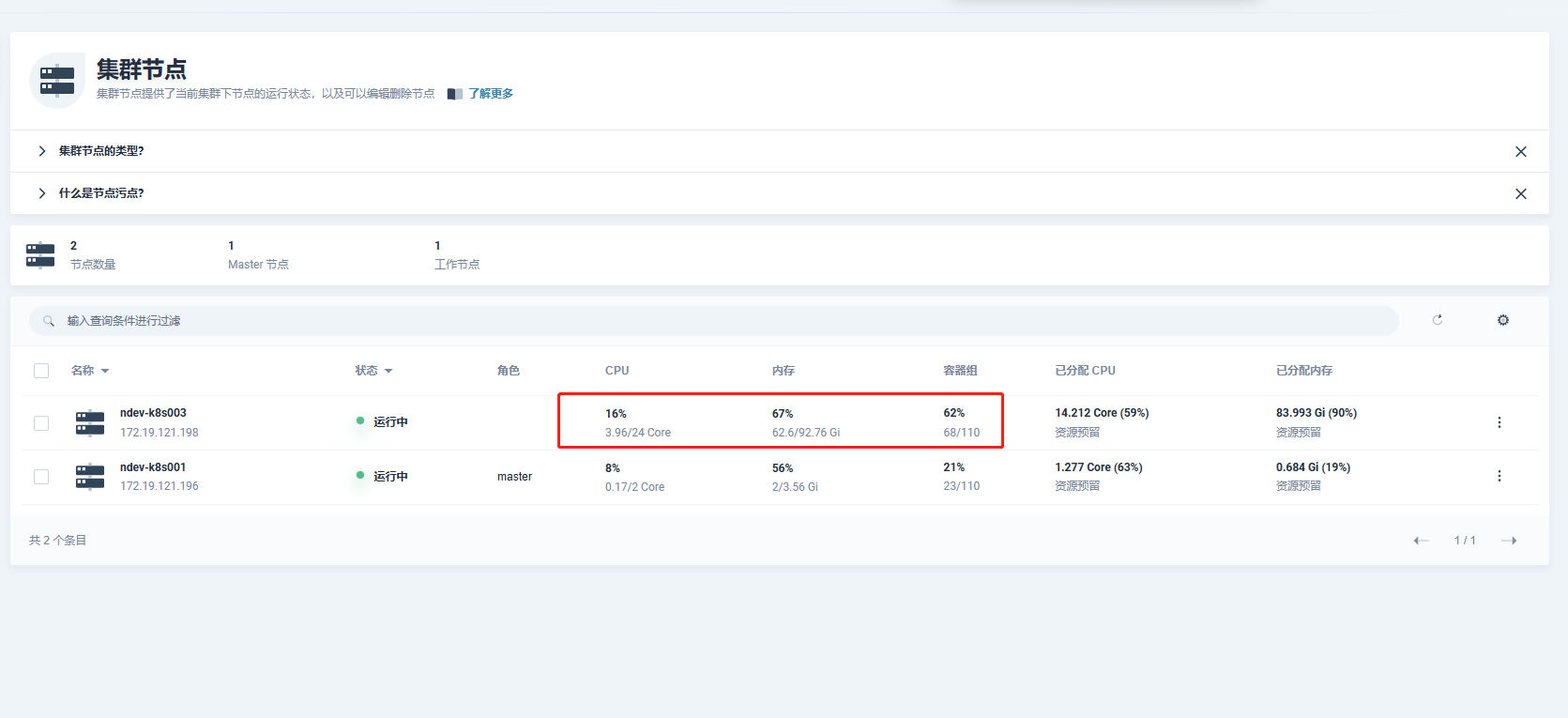
部署的k8s集群只有1个worker节点,资源充足,obcluster.yaml将3个zone的nodeselector都指定这1个worker节点上了,请问是这个原因导致的吗?必须3个zone放在不同的worker节点?
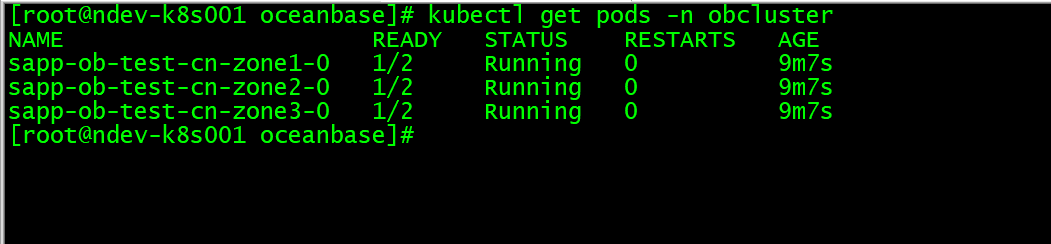
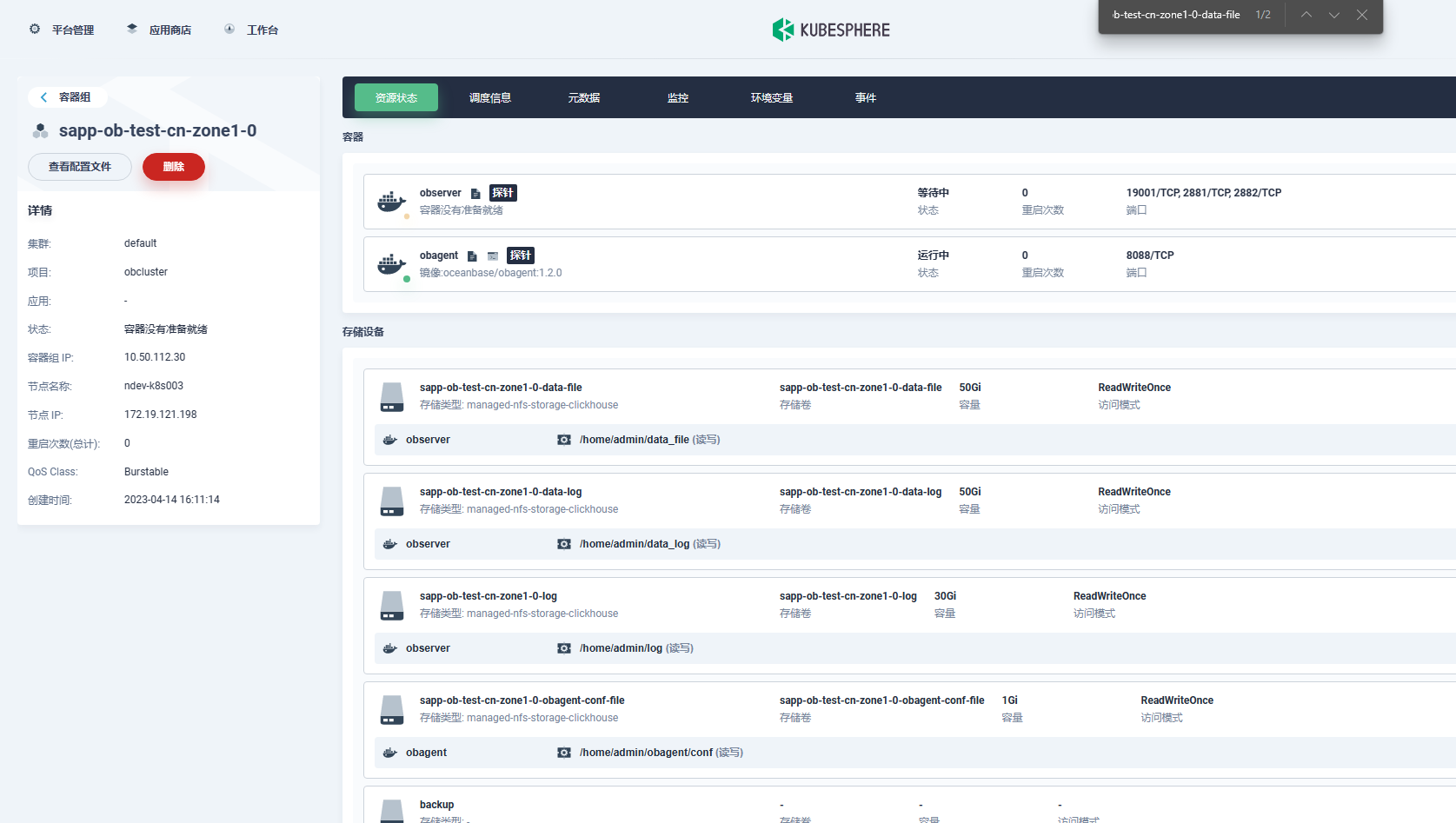
可以在k8s中执行kubectl get pods -n obcluster 看下吗
执行 kubectl logs ${operator-podname} manager -n oceanbase-system看下operator日志,其中${operator-podname} 就是 ob-operator对应的pod的名字
没有必须3个zone放在不同的worker节点
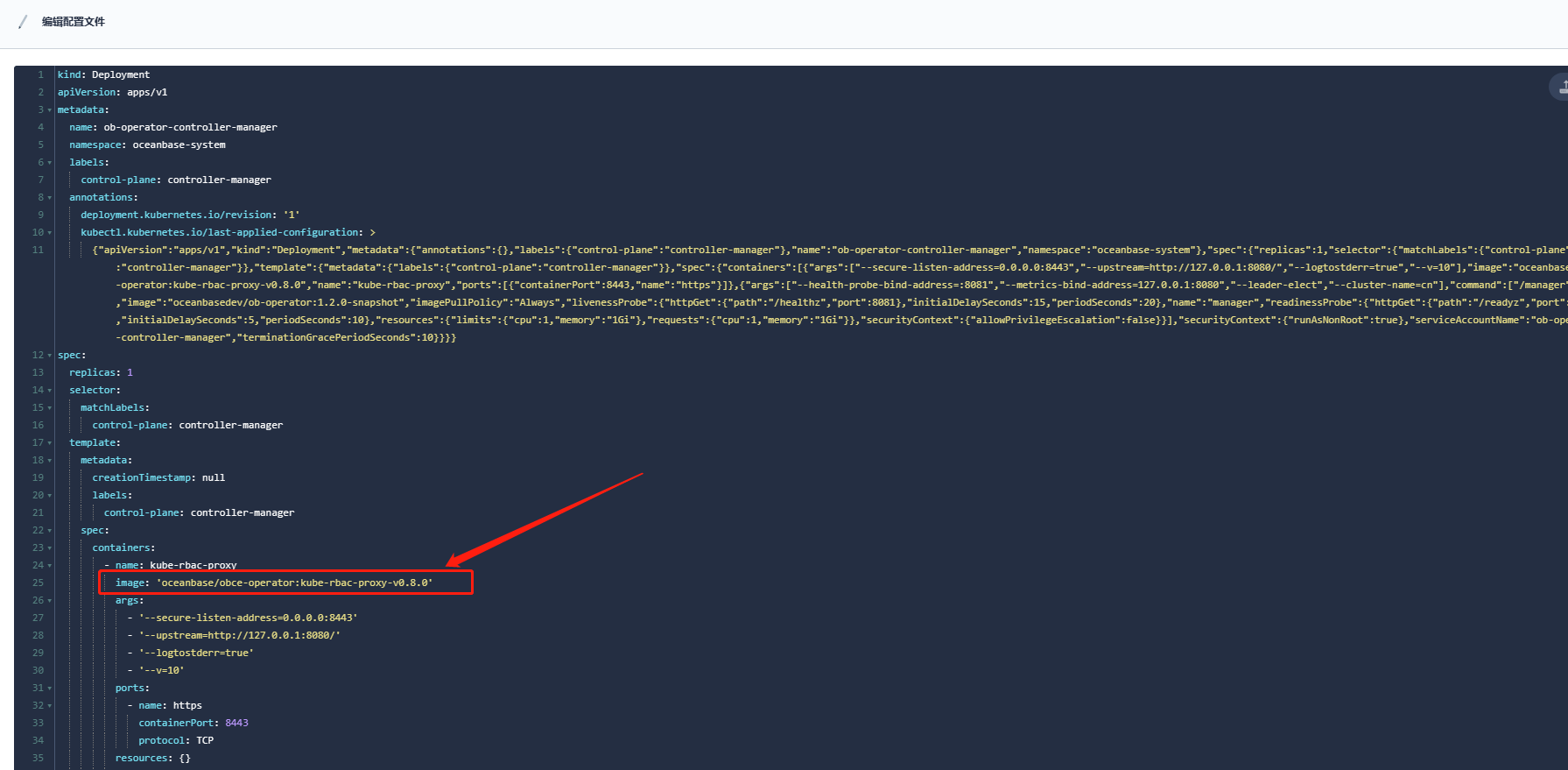
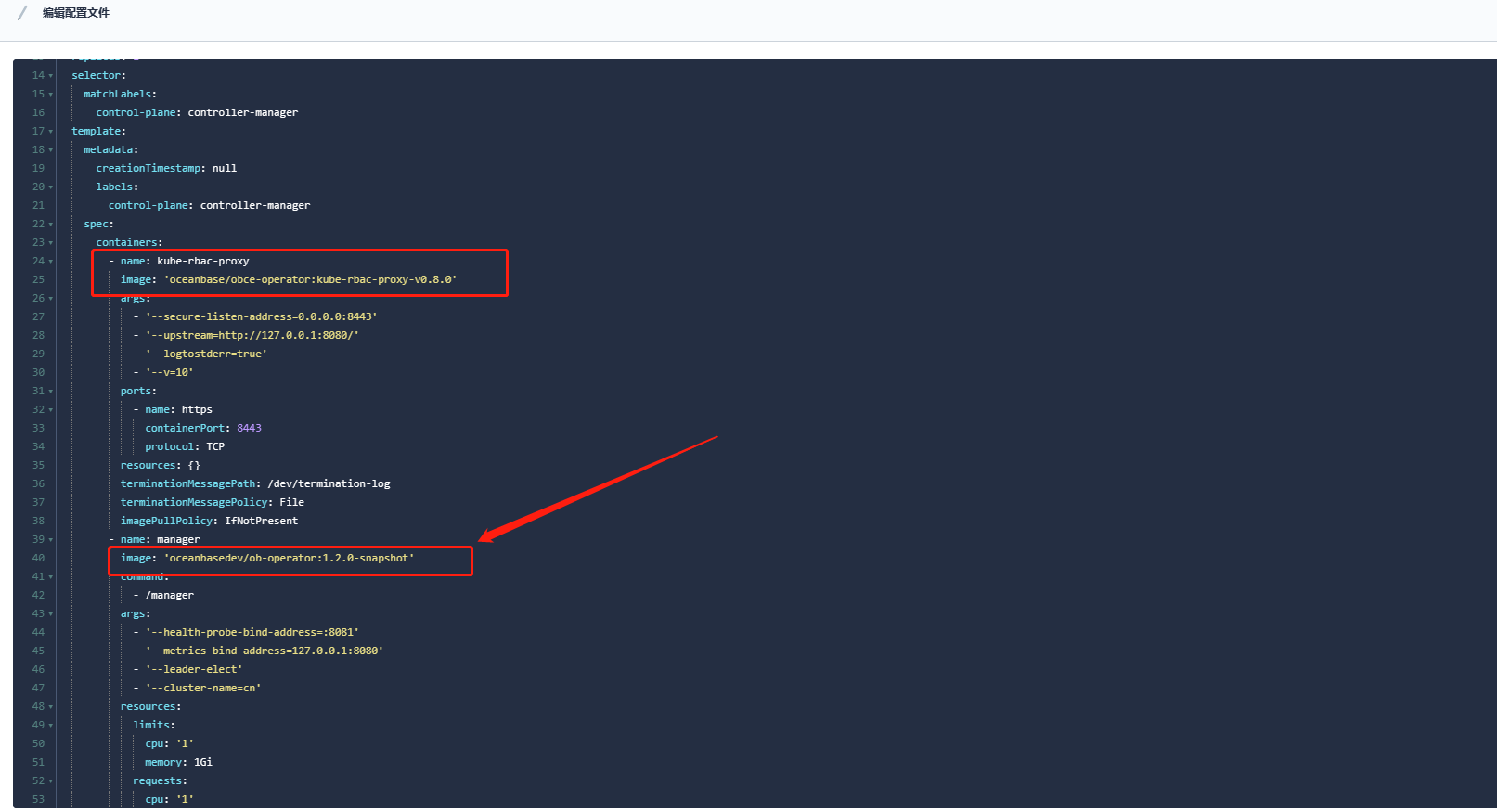
ob-operator 的镜像 tag是多少
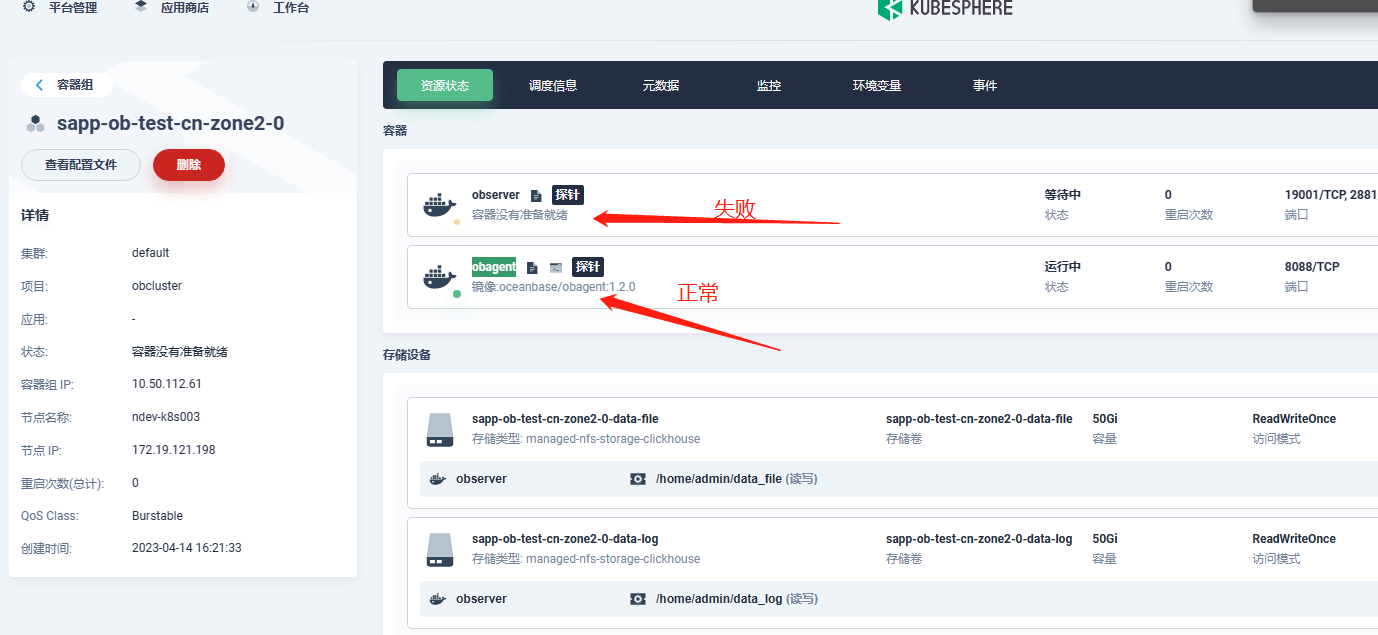
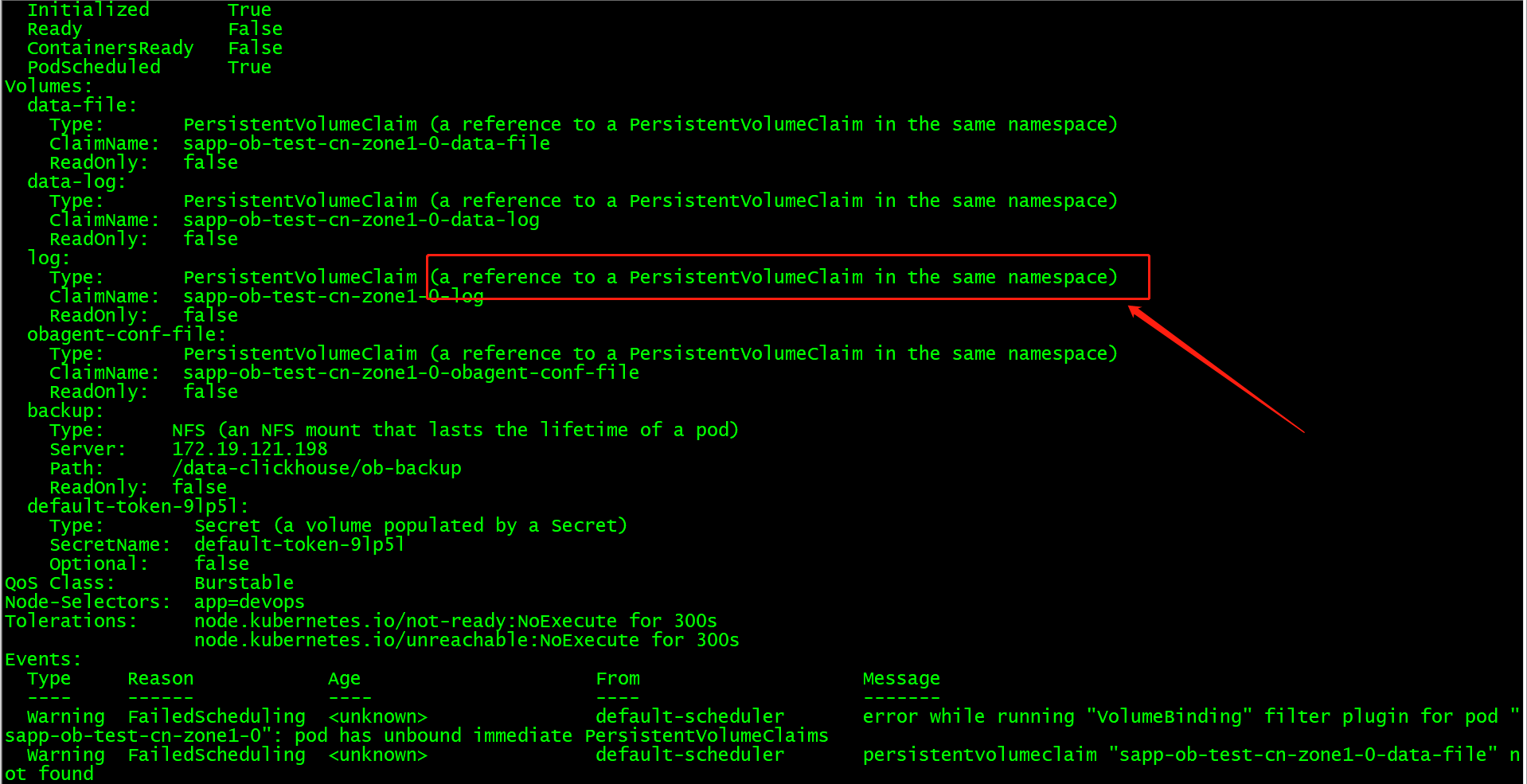
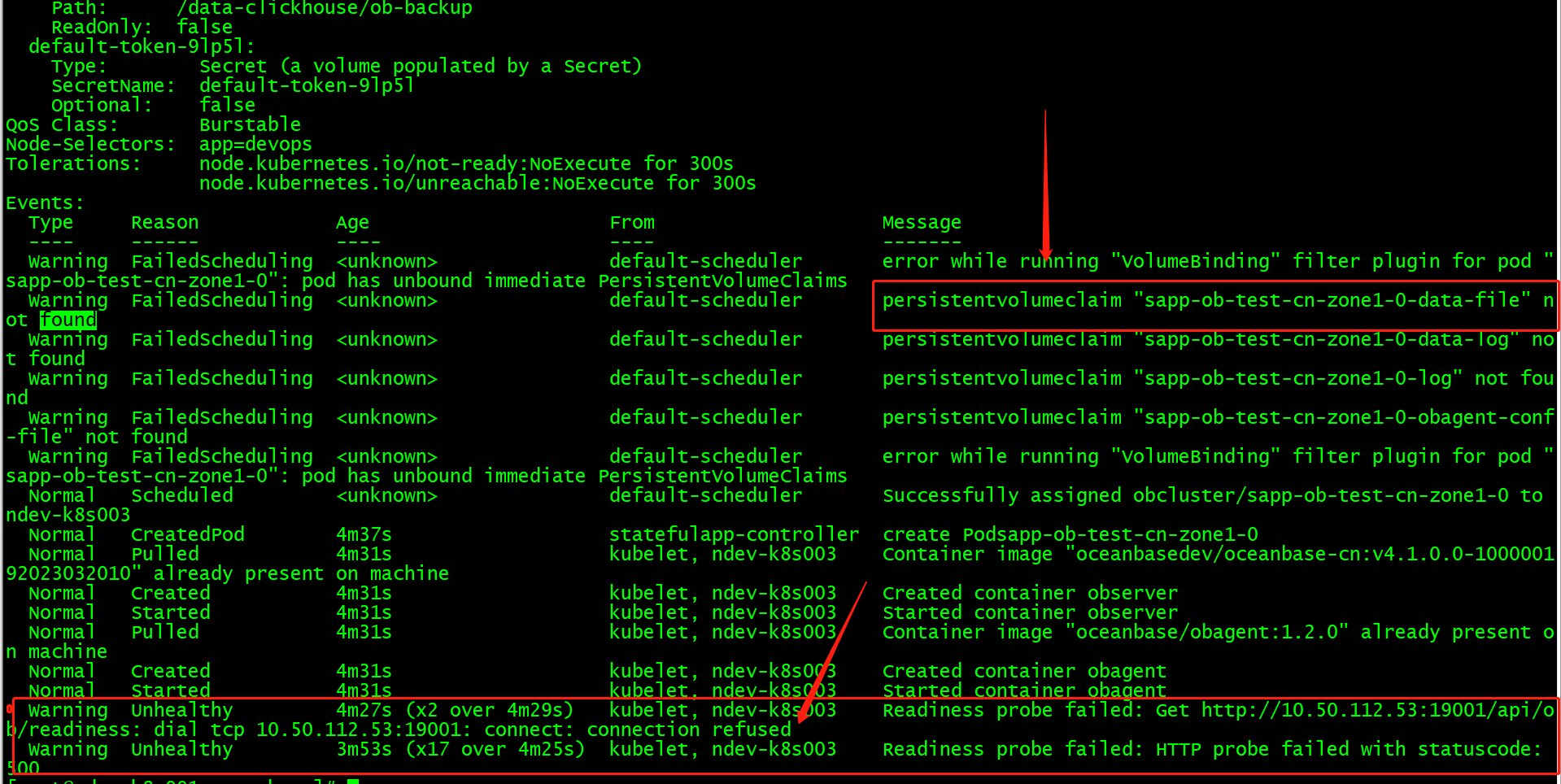
可以执行 kubectl describe pod sapp-ob-test-cn-zone1-0 -n obcluster 看下当前 pod 在做什么
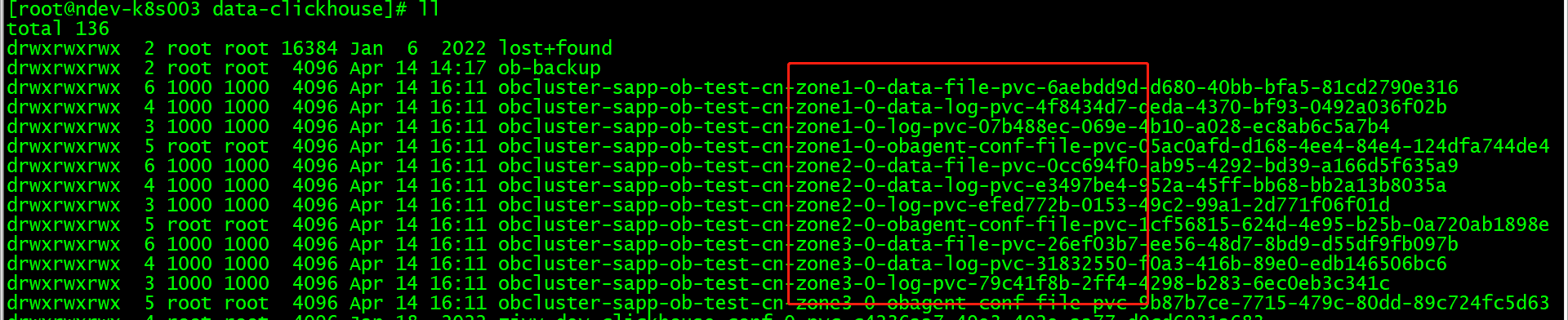
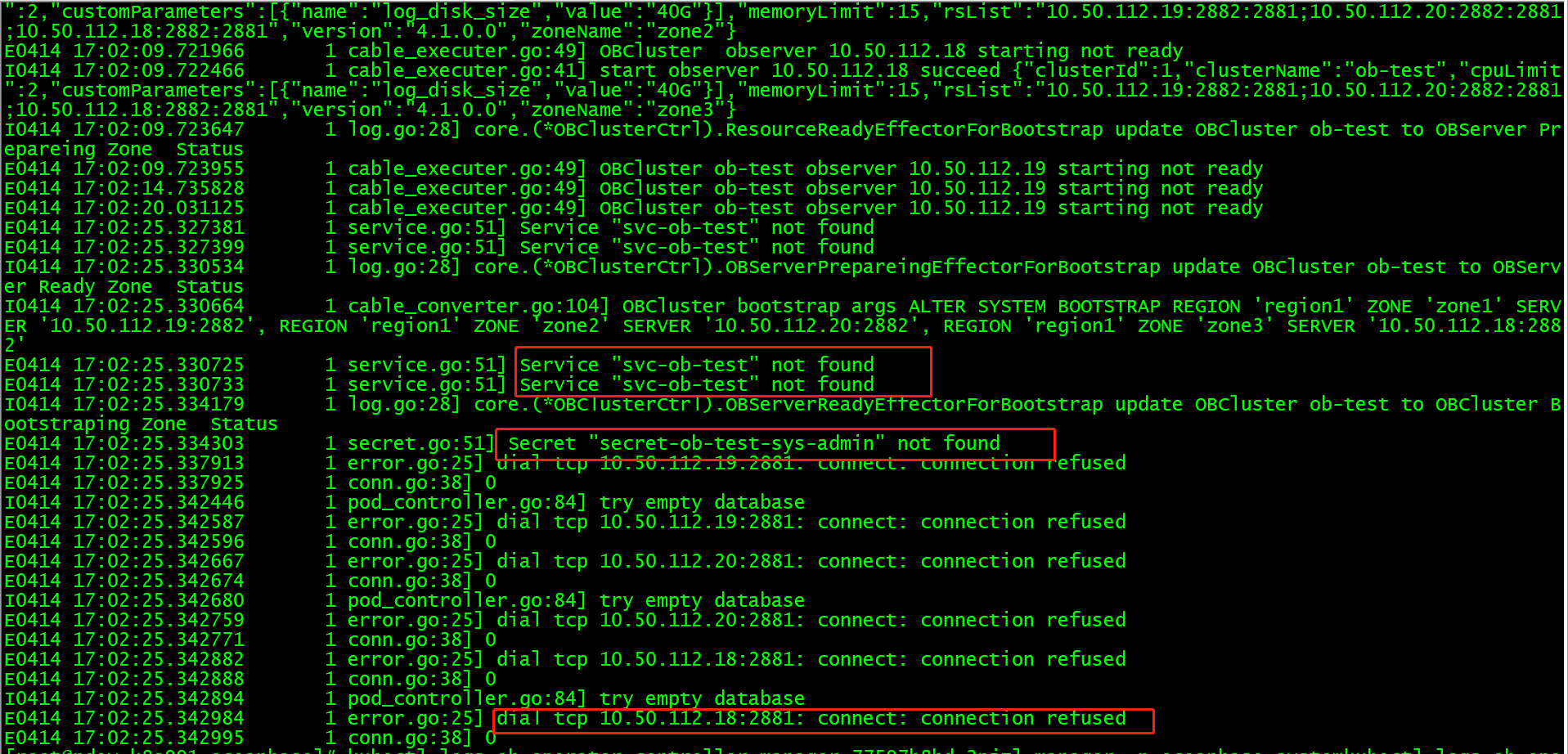
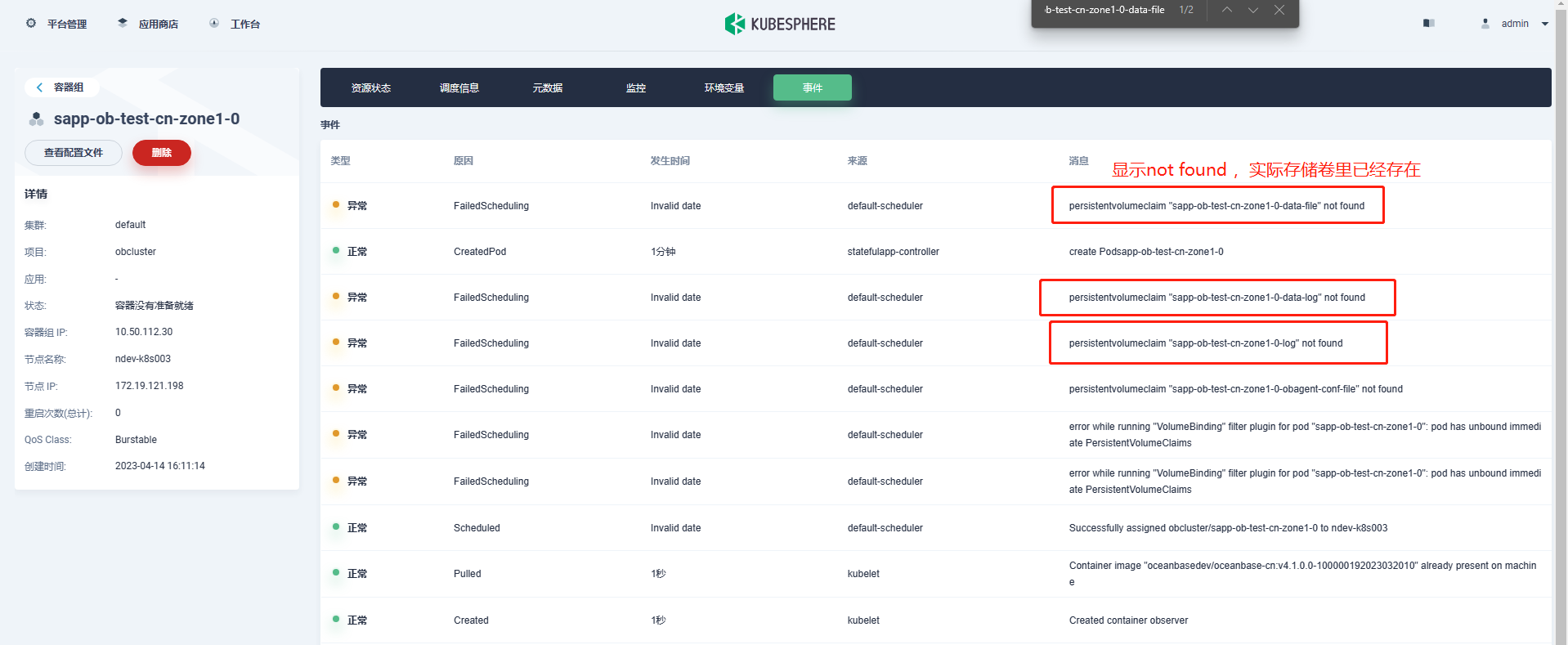
pvc 不存在是会去创建的,正常也是日志中先看如果不存在就去创建的,集群起不来,可以去 observer 的pod里看下 ob 的日志,应该是没起来,ob-operator的日志里应该也有对应的信息
可以将这个完整log上传一下吗,方便问题定位。同时可以进入 observer容器看一下error
kubectl exec -it pod sapp-ob-test-cn-zone1-0 -n obcluster -c observer bash
cd /home/admin/oceanbase/log
grep ’ ERROR ’ *
你截图的镜像不是ob-operator的,是 kube rbac proxy的
operator.log (440.8 KB)
这是执行
kubectl logs ob-operator-controller-manager-77597b8bd-2pjzl manager -n oceanbase-system
的完整log,麻烦您了;
看了operator 的日志,发现是ob bootstrap 超时。这个需要查看ob的日志了。需要辛苦一下上传 observer 容器中的日志。进入方式:
kubectl exec -it pod sapp-ob-test-cn-zone1-0 -n obcluster -c observer bash
cd /home/admin/oceanbase/log
辛苦将 log下的日志上传一下。
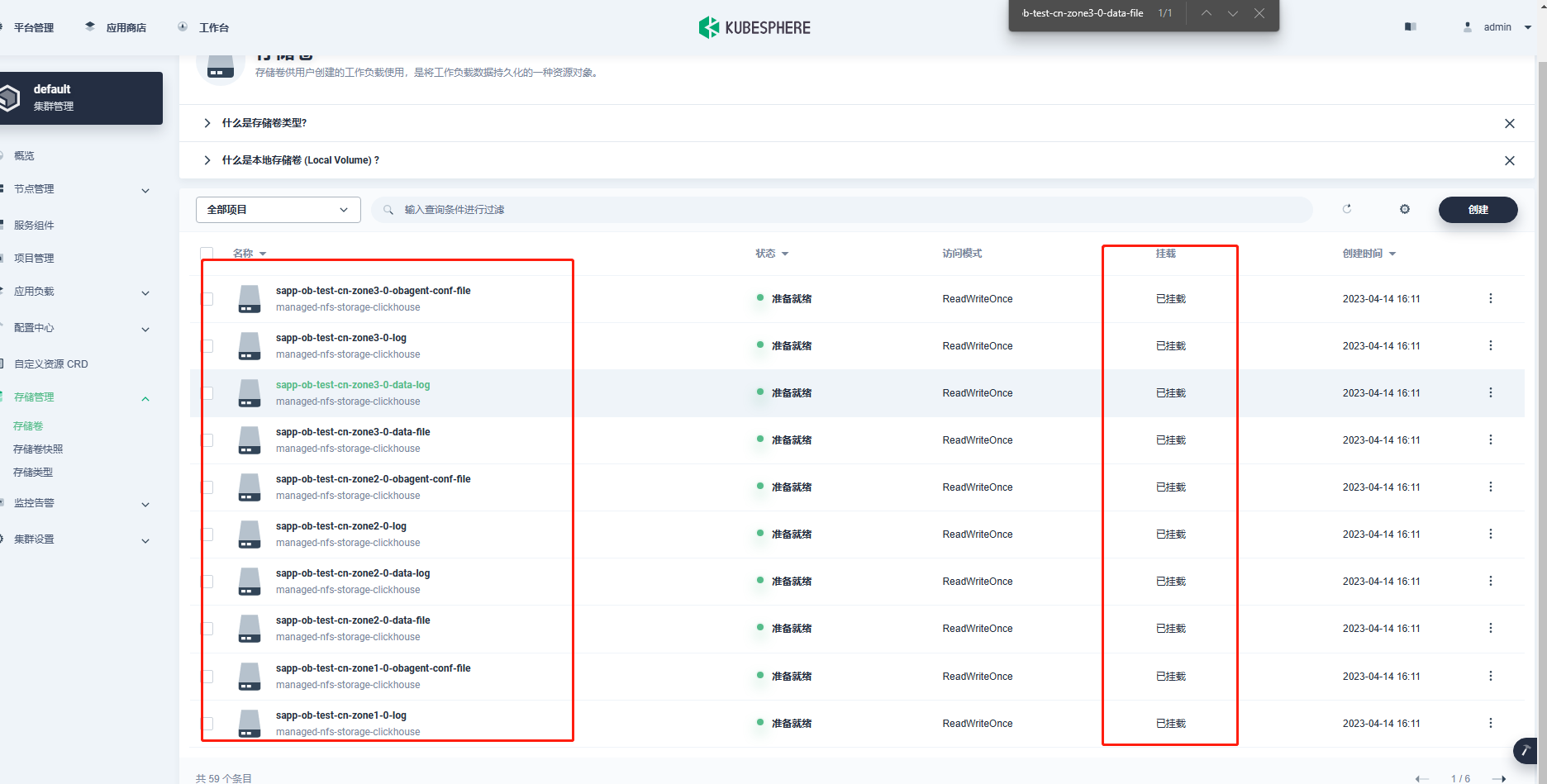
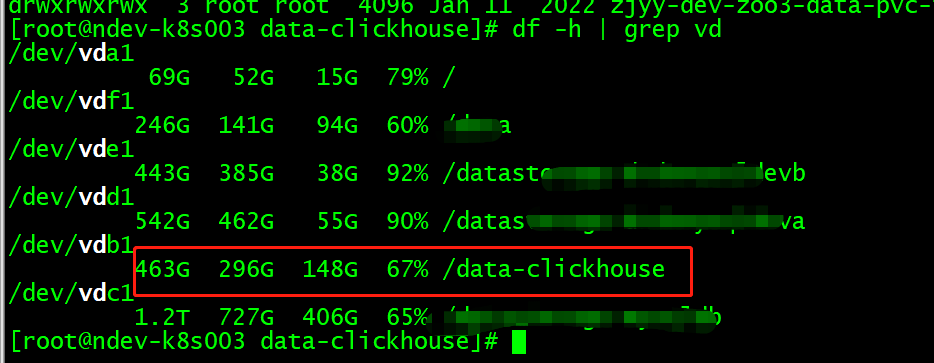
看了一下日志中说 “Fail to fallocate block file”,请问 pvc 用的存储是什么类型。
用的nfs,镜像
k8s部署其他服务用此存储,正常在用的。
这是存储类型的yaml文件
rbac.txt (1.9 KB)
class.txt (346 字节)
deployment.txt (1.1 KB)