

【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
如图,能举个例子么。
【复现路径】问题出现前后相关操作
【问题现象及影响】
【附件】
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
如图,能举个例子么。
【复现路径】问题出现前后相关操作
【问题现象及影响】
【附件】
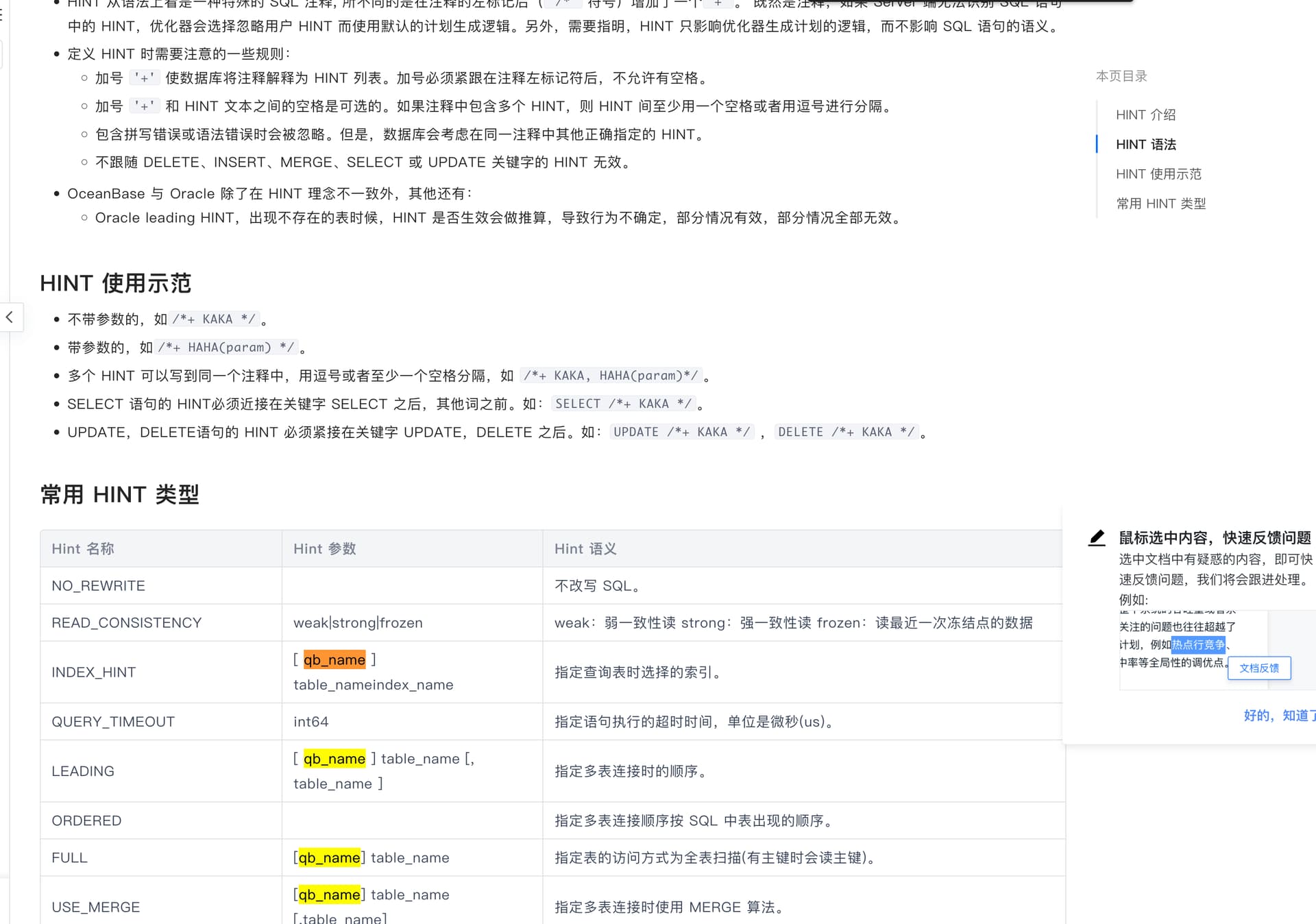
是指query block name
请问命名方式是怎么样的。 select * from t2 where c1 in (select id from t2 where id in (select id from t3 union all select id from t4)) 的 query block是啥?怎么为子查询里的 T2 指定索引?谢谢
OceanBase(admin@test)>create table t1(c1 int);
Query OK, 0 rows affected (0.54 sec)
OceanBase(admin@test)>create table t2(c1 int);
Query OK, 0 rows affected (0.44 sec)
OceanBase(admin@test)>select * from t1 union select * from t2;
Empty set (0.13 sec)
OceanBase(admin@test)>explain outline select * from t1 union select * from t2;
+-------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |HASH UNION DISTINCT| |2 |4 | |
| |1 | TABLE SCAN |t1 |1 |2 | |
| |2 | TABLE SCAN |t2 |1 |2 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([UNION([1])]), filter(nil), rowset=256 |
| 1 - output([t1.c1]), filter(nil), rowset=256 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 2 - output([t2.c1]), filter(nil), rowset=256 |
| access([t2.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| USE_HASH_SET(@"SET$1") |
| FULL(@"SEL$1" "test"."t1"@"SEL$1") |
| FULL(@"SEL$2" "test"."t2"@"SEL$2") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
+-------------------------------------------------------------------+
28 rows in set (0.04 sec)
OceanBase(admin@test)>explain outline select /*+NO_USE_HASH_SET(@"SET$1")*/ * from t1 union select * from t2;
+-------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |MERGE UNION DISTINCT| |2 |4 | |
| |1 | SORT | |1 |2 | |
| |2 | TABLE SCAN |t1 |1 |2 | |
| |3 | SORT | |1 |2 | |
| |4 | TABLE SCAN |t2 |1 |2 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([UNION([1])]), filter(nil), rowset=256 |
| 1 - output([t1.c1]), filter(nil), rowset=256 |
| sort_keys([t1.c1, ASC]) |
| 2 - output([t1.c1]), filter(nil), rowset=256 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 3 - output([t2.c1]), filter(nil), rowset=256 |
| sort_keys([t2.c1, ASC]) |
| 4 - output([t2.c1]), filter(nil), rowset=256 |
| access([t2.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| FULL(@"SEL$1" "test"."t1"@"SEL$1") |
| FULL(@"SEL$2" "test"."t2"@"SEL$2") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
+-------------------------------------------------------------------+
33 rows in set (0.01 sec)
比如这里的一个例子,我指定了整个union不能用算法,block的命名是特定生成的,比如对于这个union整体有三个block,左右支和整支, 所以指定了SET$1表示一个set query,
hint的使用参考https://www.oceanbase.com/docs/community-observer-cn-10000000000902304