

【 使用环境 】测试环境
【 OB or 其他组件 】observer
【 使用版本 】4.0
obproxy
observer1
observer2
observer3 宕机已重启
目前集群状态不可用
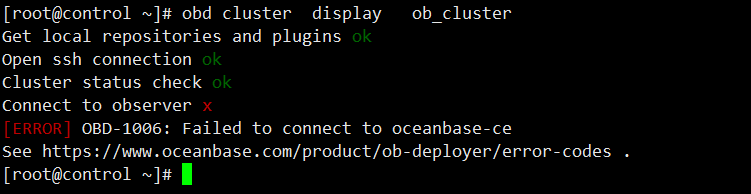
ob1、ob2、ob3 2881均连接不上
ob1
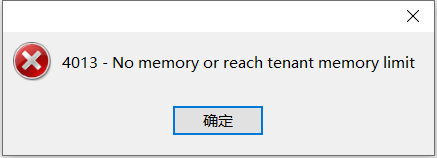
ob2

ob3
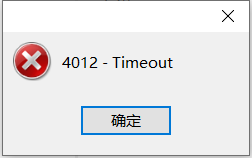

集群重启后,恢复正常。
obd cluster restart ob_cluster
问题:不是说集群有容灾机制吗?一台observer下线,为何会造成整个集群都无法工作?
【 使用环境 】测试环境
【 OB or 其他组件 】observer
【 使用版本 】4.0
obproxy
observer1
observer2
observer3 宕机已重启
目前集群状态不可用
ob1、ob2、ob3 2881均连接不上
ob1
ob2
ob3
集群重启后,恢复正常。
obd cluster restart ob_cluster
问题:不是说集群有容灾机制吗?一台observer下线,为何会造成整个集群都无法工作?
从图上看感觉是三个observer全下线了,这当然不可用了
这个可能要结合日志和机器配置具体看一下
理论上来说大概率是机器配置问题,内存过小导致整个集群不可用
两个节点,下线一台肯定不可用。
三副本中存在2个可用,本来就是2个在下一个,就剩一个副本,小于二分之一副本了,都无法选主,自然无法提供服务
对,报错就是内存不足。
需要排查一下日志,是哪个租户内存不足,是不是500内部租户。
问答区搜索一下这个异常,有很多其他帖子可以参考
感谢回复。
我想再问一下,是必须要满足剩余副本数大于二分之一么?还是说剩余副本数大于等于二就行?
如果官方文档里有相关描述能否提供一下地址呢。
剩余副本要求能够组成多数派,例如5副本集群其中3副本就是多数派,3副本集群其中2副本就是多数派,2副本集群剩余1:1没有多数派了。可以看下Paxos协议的概念:Paxos 协议是基于多数派的协议,简单来说,任何决策的达成均需要多数派节点达成一致。
https://www.oceanbase.com/docs/community-observer-cn-10000000000901313
