

背景
某天,业务在测试环境验证在线修数的时候,突然发现查询和更新的性能明显下降。于是找了过来。我刚开始想是因为数据量太大了?我查了下总数据量1.5亿,对应查询条件的数据只有10w条;
于是我就开始查看日志,发现这张表在批量执行频繁的插入和删除操作,刚开始速度还正常,过了一会速度就降下来了。于是找了下官方的资料,找到如下的Queuing表查询缓慢问题。
这种现象在 OceanBase 中称为Queuing 表(业务上有时又称 buffer 表)效应
我们先把问题复现下。
问题复现
创建表
t1表
批量执行增删改
这块由业务进行多线程的处理,我就不做过多的写了。
查询与验证
#执行sql
select * from t1 WHERE status = 20 order by time asc limit 100;
执行时间2min
# 系统租户下查看该sql的执行信息
#查看抽象的SQL,获取对应的sql_id
select * from gv$sql where sql_text like '%t1%100%'\G
#查看具体的SQL
select * from gv$sql_audit where sql_id='B4052F8179B5E4ED64E6AD8FC9AAAB68'\G
*************************** 1. row ***************************
SVR_IP: xxx.xxx.xxx.xxx
SVR_PORT: 2882
REQUEST_ID: 3385485971
SQL_EXEC_ID: 3685755568
TRACE_ID: YB42AC154DB9-0005EC18243E3C2E-0-0
SID: 3221607120
CLIENT_IP: xxx.xxx.xxx.xxx
CLIENT_PORT: 47096
TENANT_ID: 1001
TENANT_NAME: test
EFFECTIVE_TENANT_ID: 1001
USER_ID: 1100611139403777
USER_NAME: root
USER_GROUP: 0
USER_CLIENT_IP: 172.21.244.68
DB_ID: 1100611139404827
DB_NAME: saos_leads
SQL_ID: B4052F8179B5E4ED64E6AD8FC9AAAB68
QUERY_SQL: select * from t1 WHERE status = 20 order by time asc limit 100
PLAN_ID: 11693
AFFECTED_ROWS: 0
RETURN_ROWS: 100
PARTITION_CNT: 1
RET_CODE: 0
QC_ID: 0
DFO_ID: 0
SQC_ID: 0
WORKER_ID: 0
EVENT: mysql response wait client
P1TEXT:
P1: 0
P2TEXT:
P2: 0
P3TEXT:
P3: 0
LEVEL: 0
WAIT_CLASS_ID: 107
WAIT_CLASS#: 7
WAIT_CLASS: NETWORK
STATE: WAITED SHORT TIME
WAIT_TIME_MICRO: 328
TOTAL_WAIT_TIME_MICRO: 1427
TOTAL_WAITS: 16
RPC_COUNT: 0
PLAN_TYPE: 1
IS_INNER_SQL: 0
IS_EXECUTOR_RPC: 0
IS_HIT_PLAN: 0
REQUEST_TIME: 1670231655208163
ELAPSED_TIME: 90416901
NET_TIME: 0
NET_WAIT_TIME: 1
QUEUE_TIME: 14
DECODE_TIME: 1
GET_PLAN_TIME: 6799
EXECUTE_TIME: 90410081
APPLICATION_WAIT_TIME: 0
CONCURRENCY_WAIT_TIME: 0
USER_IO_WAIT_TIME: 0
SCHEDULE_TIME: 0
ROW_CACHE_HIT: 10
BLOOM_FILTER_CACHE_HIT: 0
BLOCK_CACHE_HIT: 270451
BLOCK_INDEX_CACHE_HIT: 3187
DISK_READS: 1197
RETRY_CNT: 0
TABLE_SCAN: 0
CONSISTENCY_LEVEL: 3
MEMSTORE_READ_ROW_COUNT: 1366352
SSSTORE_READ_ROW_COUNT: 178090938
REQUEST_MEMORY_USED: 2096128
EXPECTED_WORKER_COUNT: 0
USED_WORKER_COUNT: 0
SCHED_INFO: NULL
FUSE_ROW_CACHE_HIT: 0
PS_STMT_ID: 0
TRANSACTION_HASH: 0
REQUEST_TYPE: 2
IS_BATCHED_MULTI_STMT: 0
OB_TRACE_INFO: NULL
PLAN_HASH: 3901304329868163351
LOCK_FOR_READ_TIME: 0
WAIT_TRX_MIGRATE_TIME: 0
PARAMS_VALUE:
1 row in set (0.61 sec)
我们重点看几个指标:EXECUTE_TIME、MEMSTORE_READ_ROW_COUNT、SSSTORE_READ_ROW_COUNT
-
EXECUTE_TIME执行时间90410081 -
MEMSTORE_READ_ROW_COUNT从字面意思就能看到是OceanBase的内存结构读取的行数,从内存中读取了136万行 -
SSSTORE_READ_ROW_COUNT从字面意思,就能看到是OceanBase的基线数据读取行,读取了1.78亿条;
Why? 两个问题:
-
MEMSTORE_READ_ROW_COUNT+SSSTORE_READ_ROW_COUNT>总行数1.5亿 - 执行计划走索引了,实际数据只有10万行,为啥会全表扫?
这就需要我们要了解下OceanBase的存储以及索引机制,在了解这个问题之前,我们先了解下OceanBase对Queuing表,然后再分析下根因。
Queuing 表简介
最主要的特征是:全表数据有大比例的更新或者增删。
- 触发条件: 表数据频繁大比例更新
- 当表中大量插入的同时大量连续删除(或者大量更新,因为 OB 更新的本质也是 delete+insert )时,一张表看起来只有几千行数据,但实际上可能已经发生了几百万的插入和删除操作。
- 直接现象:表行数不大,但查询很慢
- buffer表效应的一个明显特征就是数据量很小的表(例如几千行),查询起来却非常慢。
- 这是因为对于buffer表来说,查询的SQL在内核处理时,实际需要扫描的行数量可能远大于这个量级(可能是几百到上千万)。
- 在默认设置下,一张表中删除的行在 OB 每日合并前并不是真的删除,而只是在内存里打了个删除标记,
OB major freeze/merge期间才会真正处理为删除。
- 问题原因:执行计划跳变,全表扫描耗时翻倍
- 这种 “mark for delete” 的处理方式, 是采用了 LSM tree 架构的存储引擎的共同问题。
- 而且因为buffer表的删除会在合并期间处理为真正的删除,而 OceanBase 在合并期间会收集统计信息,更新执行计划,此时部分表的数据量因为很少,OceanBase的 CBO 优化器可能根据代价计算而为某些 SQL 生成全表扫描的计划。这个执行计划在白天随着业务访问不断增加,表中的实际数据量不断加大,SQL 性能会出现较大滑坡。
应急处理方案
Buffer 表出现时多数情况下系统已经运行在线上,此时需要的是快速处理,常见处理如下:
- 对于存在可用索引,但 OB 优化器计划生成为全表扫描的场景。需要进行执行计划 binding 来固定计划。
- 如果sql查询的主要过滤字段无可用索引,此时推荐在线创建可用索引并绑定该计划。
- 如果业务场景暂时无法创建索引,或者执行的 SQL 多为范围扫描,此时可根据业务场景需要决定是否手动触发合并,将删除或更新的数据版本进行清理,降低全表扫描的数据量,提升速度。(一般不建议对核心业务库进行手动触发合并,因为合并是全局级别,会影响其他租户的性能)
OceanBase对Queuing 表的优化
OceanBase 为了优化 buffer 表效应,在 MemTable 和 SSTable 两个层面,对表数据连续删除的"空洞"设定了一个阈值(如 256 行),当这些空洞被查询扫描过一次时,存储层就会在上面打上"可跳过"的标记。这样就能使相同 SQL 下次再查询时,可以直接跳过这些无需扫描的行,实现快速查询。
从2.2.7中OceanBase引入了 `buffer minor merge` 设计,实现对 queuing 表的特殊转储机制,彻底解决无效扫描问题。对于设计阶段已经明确的 Queuing 表场景,推荐开启该特性作为长期解决方案:
#对于大量增删改的表来说
ALTER TABLE t1 TABLE_MODE = 'queuing';
如果需要改回去
alter table t1 table_mode='normal';
手动转储操作
# 系统租户操作是全局
alter system minor freeze;
# 全部转储
ALTER SYSTEM MINOR FREEZE TENANT =ALL;
# 系统租户
ALTER SYSTEM MINOR FREEZE tenant = sys;
# 用户租户
ALTER SYSTEM MINOR FREEZE TENANT =tenant1,tenant2;
# zone级
ALTER SYSTEM MINOR FREEZE ZONE = zone1;
#server级
ALTER SYSTEM MINOR FREEZE SERVER = ('10.10.10.1:2882');
# 分区级
ALTER SYSTEM MINOR FREEZE tenant = t1 tablet_id = 60000;
# 普通租户触发转储,只能是自己租户的
# 本租户级
ALTER SYSTEM MINOR FREEZE;
根因
之前我们分析出来的两个问题,我们挨个来看下
为什么扫描的行数大于总行数?
我们先看下OceanBase是如何增删改的。

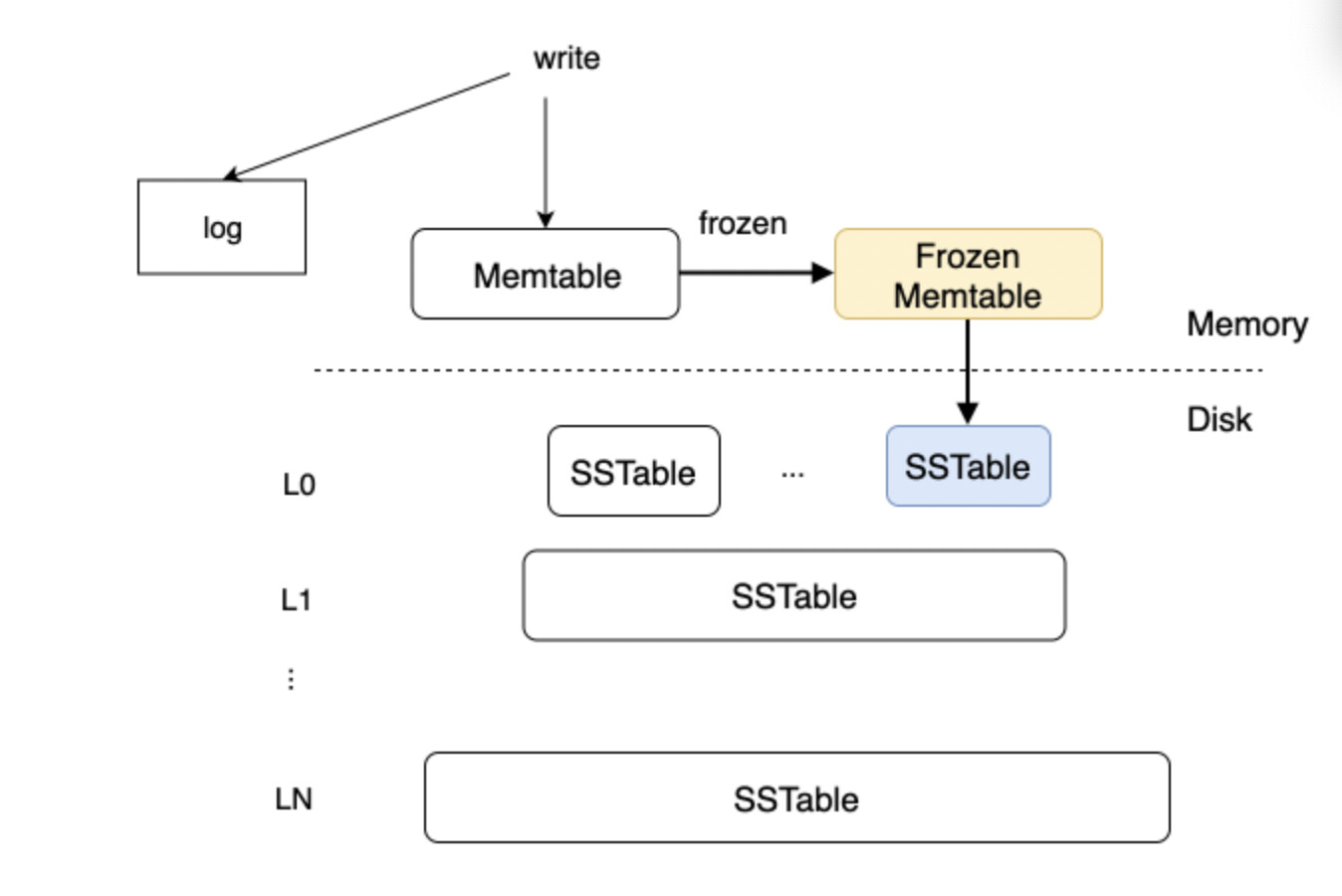
- 数据插入以后是插入到的内存
MemTable中 - 然后通过转储将内存中freeze的
memTable落入磁盘中形成Minor sstable,转储后才会往Block Cache中写入 - 通过合并将
Minor sstable中的数据和原来的Marjor sstable进行合并,合并后才会往Block Cache写入 - 写入到
Block Cache中的数据才会到Row Cache中; - 如果是update和delete的操作,操作成功后会先将
Block Cache和Row Cache中数据删除; - 而自动触发转储是
memstore_limit_percentage * freeze_trigger_percentage后才会自动触发 - 自动触发合并是
MemTable的内存使用达到了freeze_trigger_percentage设置的阈值,且转储次数已达到了major_compact_trigger设置的上限时直接触发合并;
根据配置,内存越大,触发的时机就越晚,堆积的数据就越多,增删改的数据都在内存或者转储了n次后才会合并,这个数据量可能上千万,也可能上亿。
这就是LSM-Tree典型的写放大,LSM-Tree使用空间换时间的策略,缩短了增删改的时间。
为什么全表扫描了?
我们得看下Oceanbase是如何Scan查询的。

Note: Fuse是主键行值的缓存,按版本缓存
Scan 的查询流程:
- 确定访问表名、主键范围 Range 和查询快照点(是否读最新数据)。
- 根据表名和主键范围 Range 确定要访问的 Partition,获取 Partition 中数据存储集合 TableStore。
- 在 TableStore 中根据查询数据快照点选取要访问 Table(MemTable/SSTable)的最小集合。
- 打开每个 Table,按 Range 确定要扫描的数据范围。
- 每个 Table 迭代器在扫描范围内,按主键顺序吐出快照点以前最新的行值,并压入败者树。
- Loser Tree 按主键顺序对行排序,弹出主键最小或者最大行。
- 若 Loser Tree 弹出主键相等的多行,需要按照从新到旧的原则对多行的值进行 Fuse。
- 对 Fuse 之后的行进行投影、过滤,满足过滤条件的行返回给上层;否则重复步骤 5,直到所有的 Table 都迭代完为止。
在步骤5里,会从MemTable、Minor sstable、Major sstable中查找,而一条数据从插入后更新10次,可能就有10个版本,虽然对一条数据来说从上到下只要查到就终止。但是对于scan来说,并不会,如果我insert了10条数据,在这10然后我对1~9这9条数据一直进行update,这个时候,可能转储了5次,在lsm-tree中有5个层级。这个时候我进行扫描的时候,要从最上层扫到最底层,因为10这条数据在最底层(转储虽然进缓存了,但是缓存有版本,后续再进行增删改,缓存失效)。
最后我们不得不说下转储和合并。
转储
当内存MemTable的大小超过一定阈值的时候,需要将MemTable中的数据转存到SSTable中以释放内存,这个过程称为转储。
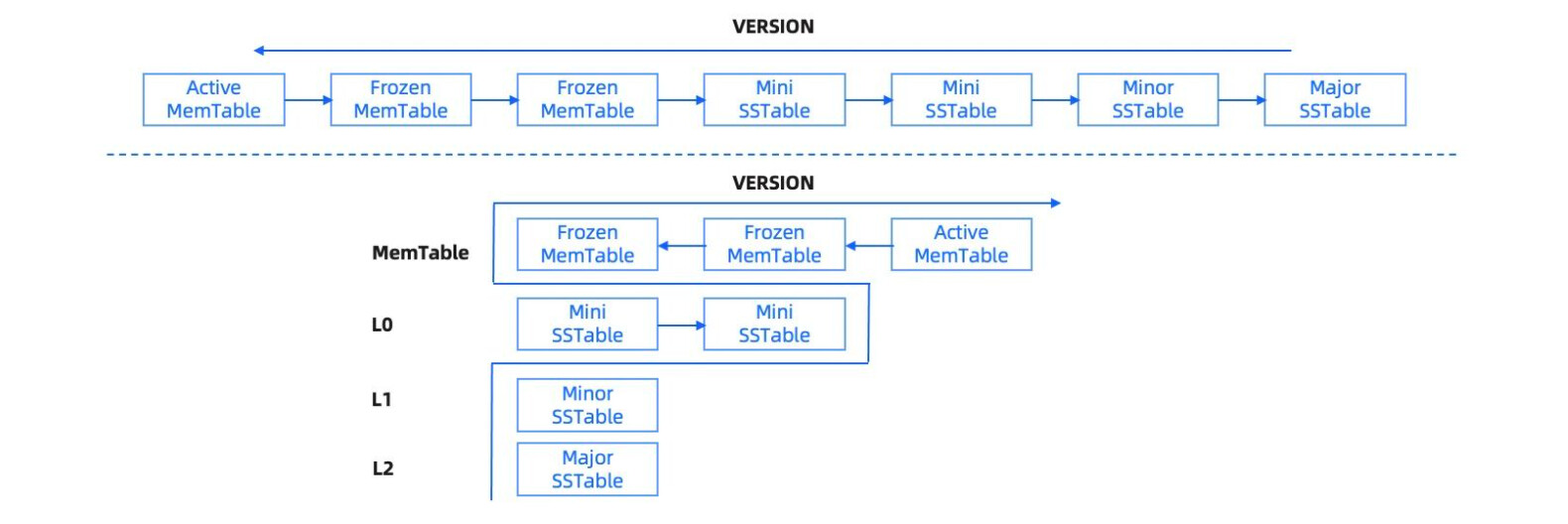
在OceanBase中版本越大,数据越新,关系如下:
Active MemTable>Frozen MemTable>Mini sstable>Minor sstable>Major sstable。
- 其中
Active MemTable和Frozen MemTable位于内存中 -
Mini sstable、Minor sstable、Major sstable为于磁盘中;
OceanBase 数据库的转储分为以下三层:
- L0 层,内部称为 Mini SSTable。
- 根据不同参数设置的不同转储策略,L0 层的 SSTable 可能存在也可能为空。
- 对于 L0 层,系统提供了 Server 级的配置项来设置 L0 层内部分层数和每层最大的 SSTable 的个数。
- L0 层内部分为
level-0到level-n层,每层最大容纳的 SSTable 个数相同。 - 当 L0 层
level-n的 SSTable 到达一定数目上限或阈值后开始整体合并,合并成一个 SSTable 写入level-n+1 层。 - 当 L0 层的最大 Level 内的 SSTable 个数达到上限后,开始做 L0 层到 L1 层的整体合并来释放空间。
- 在存在 L0 层的转储策略下,冻结 MEMTable 直接转储在 L0-level-0 写入一个新的 Mini SSTable,L0 层每个 Level 内的多个 SSTable 根据 base_version 有序,后续本层或跨层合并时需要保持一个原则,参与合并的所有 SSTable 的 Version 必须邻接,这样新合并后的 SSTable 之间仍然能维持 Version 有序,简化后续读取合并逻辑。
- L0 层的内部分层会延缓到 L1 的合并,更好地降低写放大,但同时会带来读放大,假设共 n 层,每层最多 m 个 SSTable,则最差情况 L0 层会需要持有
(n * m + 2)个 SSTable,因此实际应用中层数和每层 SSTable 上限都需要控制在合理范围。
- L1 层,内部称为 Minor SSTable,
- L1 层的 Minor SSTable 仍然维持 Rowkey 有序,每当 L0 层的 Mini SSTable 达到合并阈值后,L1 层的 Minor SSTable 开始参与和 L0 层的合并;
- 为了尽可能提升 L1 合并的效率,降低整体写放大,OceanBase 数据库内部提供了写放大系数设置,当 L0 层的 Mini SSTable 总大小和 L1 层的 Minor SSTable 的大小比率达到指定阈值后,才开始调度 L1 合并,否则仍在 L0 层内部合并。
- L2 层,是基线 Major SSTable
- 为了保证多副本间基线数据完全一致,日常转储过程中 Major SSTable 仍保持只读,不发生实际的合并动作。
触发方式
- 自动触发
- 内存的使用量达到
memstore_limit_percentage * freeze_trigger_percentage所限制使用的值时
- 内存的使用量达到
- 手动触发
- 上面已经写过,忽略
合并
当转储产生的增量数据积累到一定程度时,通过 Major Freeze 实现大版本的合并。合并与转储的最大区别在于,合并是集群上所有的分区在一个统一的快照点和全局静态数据进行合并的行为,是一个全局的操作,最终形成一个全局快照。
| 转储(Minor Compaction) | 合并(Major Compaction) |
|---|---|
| Partition 或者租户级别,只是 MemTable 的物化。 | 全局级别,产生一个全局快照。 |
| 每个 OBServer 的每个租户独立决定自己 MemTable 的冻结操作,主备分区不保持一致。 | 全局分区一起做 MEMTable 的冻结操作,要求主备 Partition 保持一致,在合并时会对数据进行一致性校验。 |
| 可能包含多个不同版本的数据行。 | 只包含快照点的版本行。 |
| 转储只与相同大版本的 Minor SSTable 合并,产生新的 Minor SSTable,所以只包含增量数据,最终被删除的行需要特殊标记。 | 合并会把当前大版本的 SSTable 和 MemTable 与前一个大版本的全量静态数据进行合并,产生新的全量数据。 |
触发方式
-
自动触发
- 当集群中任一租户的
Minor Freeze次数超过阈值时,就会自动触发整个集群的合并。
- 当集群中任一租户的
-
定时触发
-
# 设置每天2点进行合并 ALTER SYSTEM SET major_freeze_duty_time = '02:00';
-
-
手动触发
-
# 设置每天2点进行合并 ALTER SYSTEM MAJOR FREEZE;
-