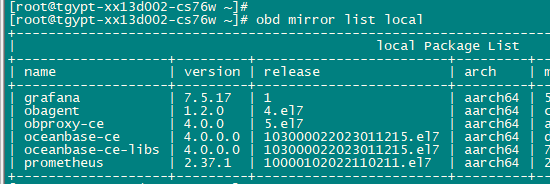
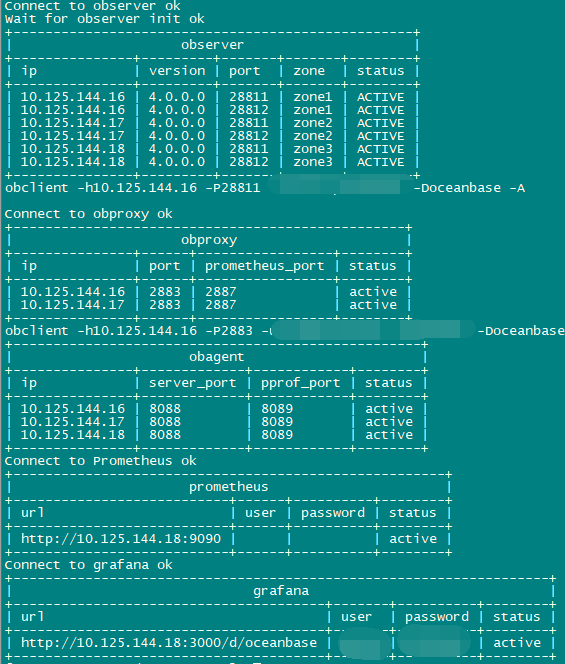
ob.rar (1.0 KB)
请问您是刚刚部署上监控吗?
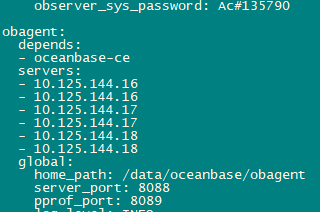
不是,把obagent添加到 集群部署配置文件里了,部署集群时一起部署的,参数文件见上面附件 ,不知道是不是哪有错误的地方,部署和初始化是没报错
好的,稍等,我看下您的配置
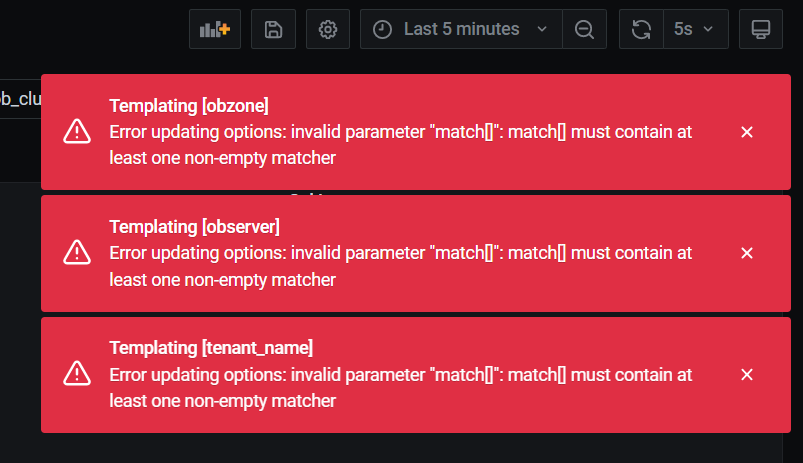
看你的报错是因为你匹配了太多的prometheus指标,导致prometheus报错。
可以参考一下这个报错:Prometheus - Match all metrics but one - Stack Overflow
修改一下新增图表的prometheus sql
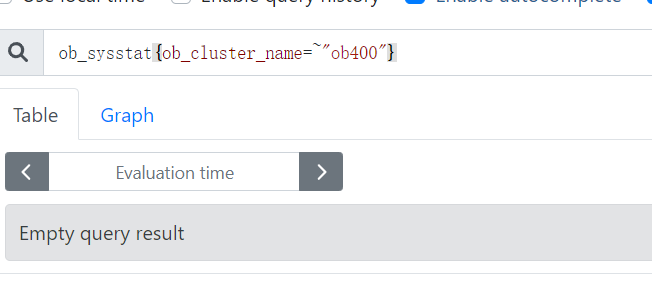
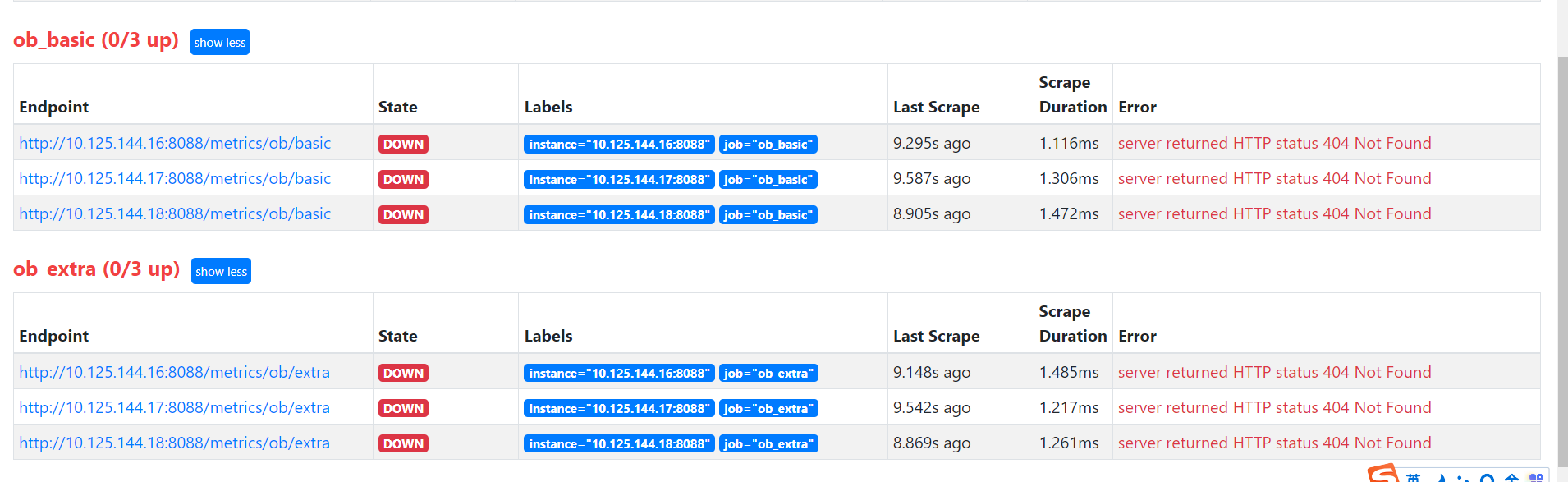
感觉应该是普罗里没有数据,或者说是虽然部署上来 ,但没和集群有关联
试试不要带筛选条件看看prometheus有没有数据
或者看看prometheus上你部署的agent收集器有没有注册上来?
这个要怎么看?
down就代表两种可能:1.收集器未启动 2.收集器的端口未对prometheus开放
顺着这两个去排查一下
收集器是指的obagent吧,3台机器上进程都是正常的
admin 4070118 1 99 Jan31 ? 1-15:41:51 /data/oceanbase/obagent/bin/monagent -c conf/monagent.yaml
这3台机器没有防火墙之类的端口限制,可能跑的东西比较乱 有k8s啥的 ,测试到普罗的端口也没问题
但是 netstat看没有到普罗的连接
稍等,我找OCP相关同学跟进一下这个问题
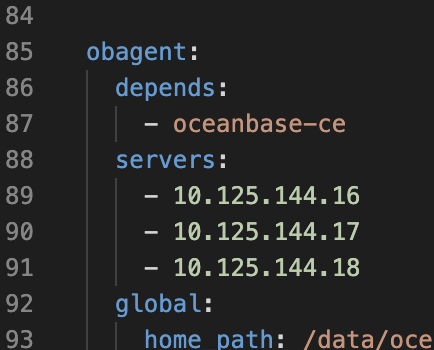
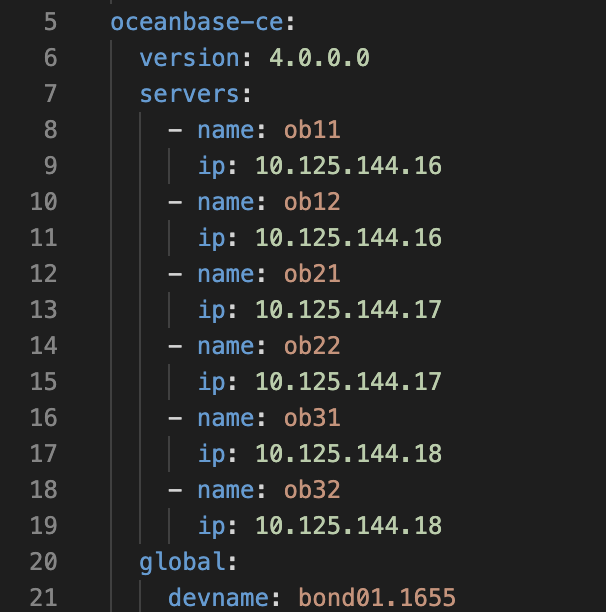
同一host的多个observer要重复写相同的IP?
是的.obagent的severs应该跟ob的保持一致
odb edit-config 加上后重启cluster不好使,正确的步骤是什么
貌似不是这个问题 我把几个server加上后重新部署还是一样的报错