Jette
2022 年12 月 12 日 18:52
#1
【 使用环境 】测试环境
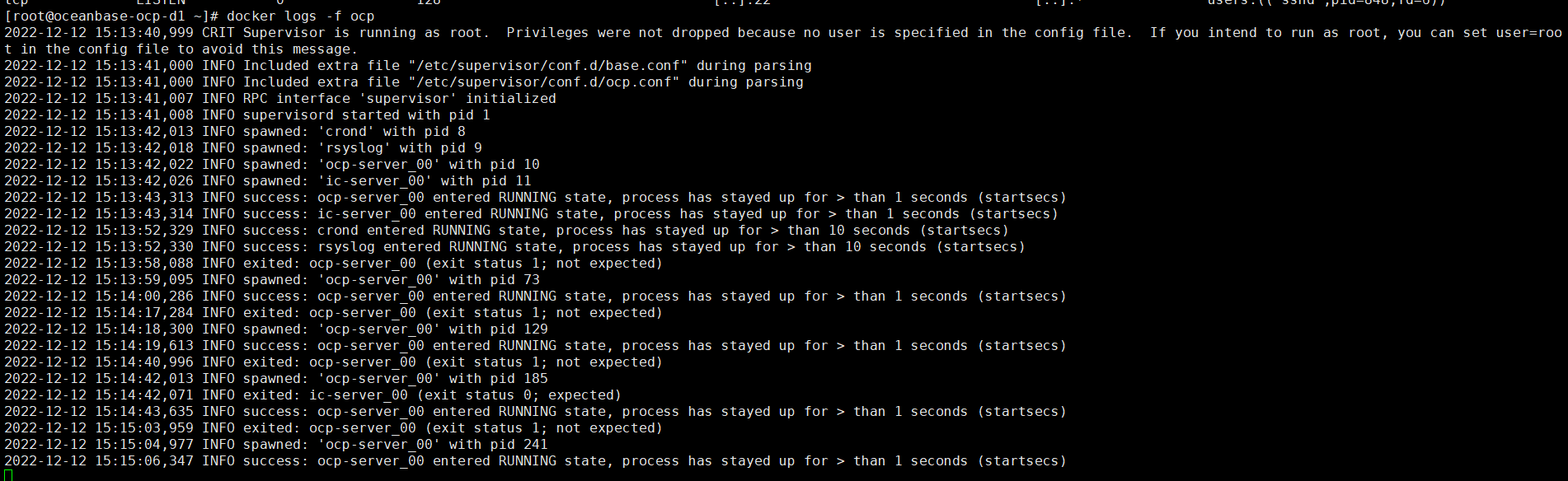
我把预占用机制调低了,和OCP检测超时时间调长了: reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:v4.0.0-ce
RUN sed -i ‘s@1024 * 7 / 10@1024 * 2 / 10@g’ /home/admin/ocp-server/bin/ocp-server && cat /home/admin/ocp-server/bin/ocp-server
docker build -f ./Dockerfile-ocp-all-in-one -t reg.docker.alibaba-inc.com/oceanbase/ocp-all-in-one:v4.0.0-ce .
cat > /home/admin/ocp-4.0.0-ce-x86_64/Dockerfile << ‘EOF’reg.docker.alibaba-inc.com/ocp2/ocp-installer:4.0.0-ce-x86_64
RUN sed -i ‘s@check_wait_time = 180@check_wait_time = 3600@g’ /root/installer/task/ocp_check.py && cat /root/installer/task/ocp_check.py
docker build -f ./Dockerfile -t reg.docker.alibaba-inc.com/ocp2/ocp-installer:4.0.0-ce-x86_64 .
【附件】OCP相关报错信息:
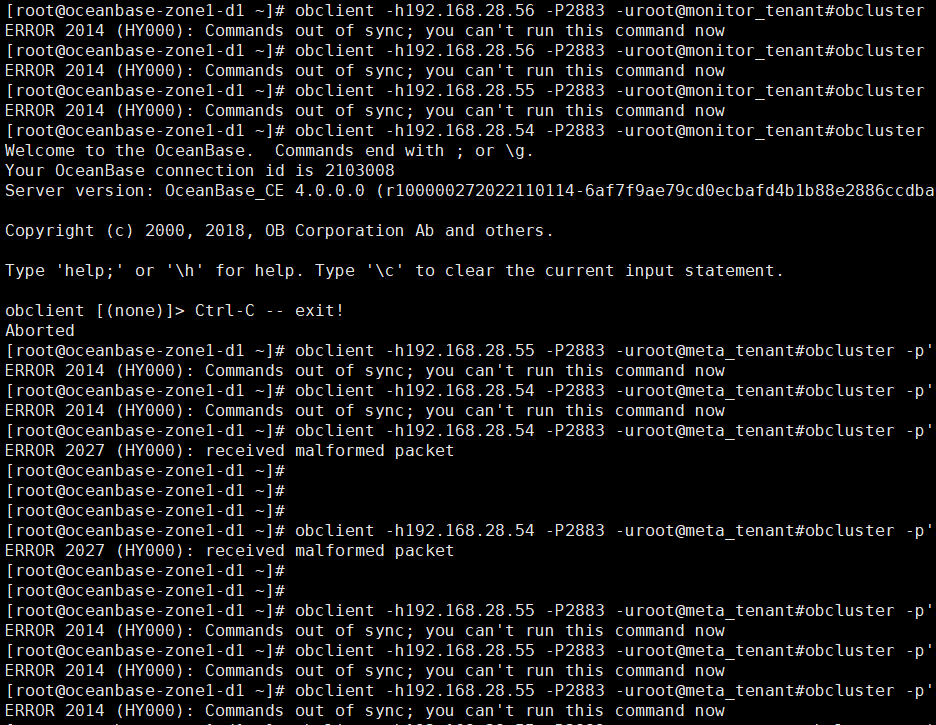
OBproxy无法连接普通租户:
为什么要调整这两个参数呢,是遇到了什么问题吗,第一个是在容器内占用多少比例的内存,调太小的话没有意义
Jette
2022 年12 月 14 日 11:35
#4
参数是根据这个帖子的把预占用调小的,AnolisOS-8.6RHCK部署ocp报错:ocp still not ok, check failed - #3,来自 ieayoio
ocp.log (3.2 MB)
Jette
2022 年12 月 14 日 11:37
#5
ocp.log日志提示查询数据库超时了呢,跟无法通过obproxy连接普通租户有关吗。
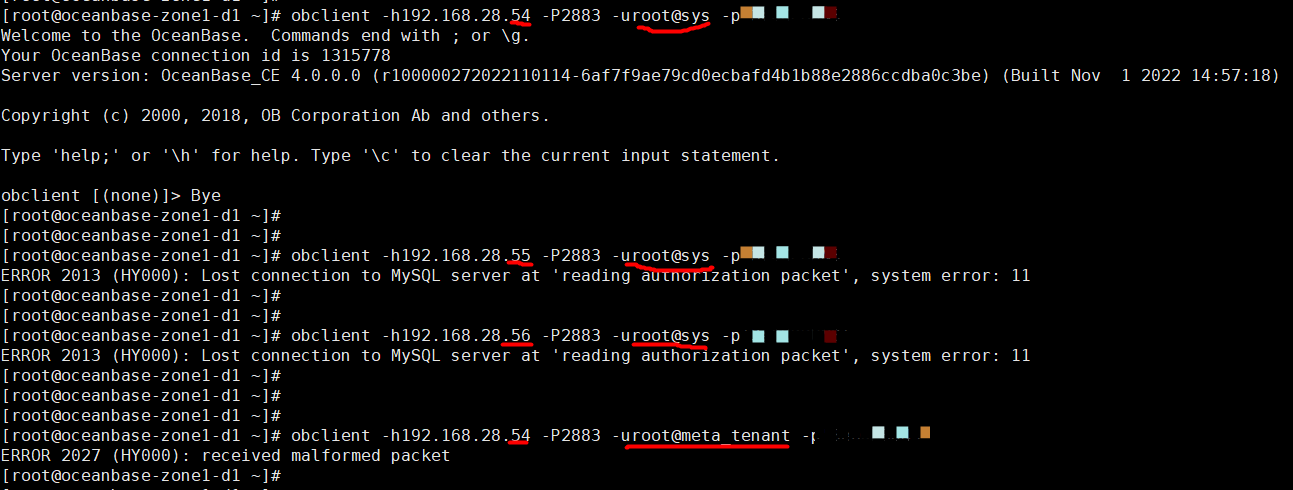
192.168.28.54:2883 这个obproxy是如何部署的呢,是部署ocp的时候配置了创建meta集群自动部署的吗,还是选择的使用已有集群的方式
Jette
2022 年12 月 14 日 11:46
#7
obproxy是通过OBD部署的,OCP是使用Docker部署的,然后通过白屏接管了OceanBase集群和OBproxy集群。
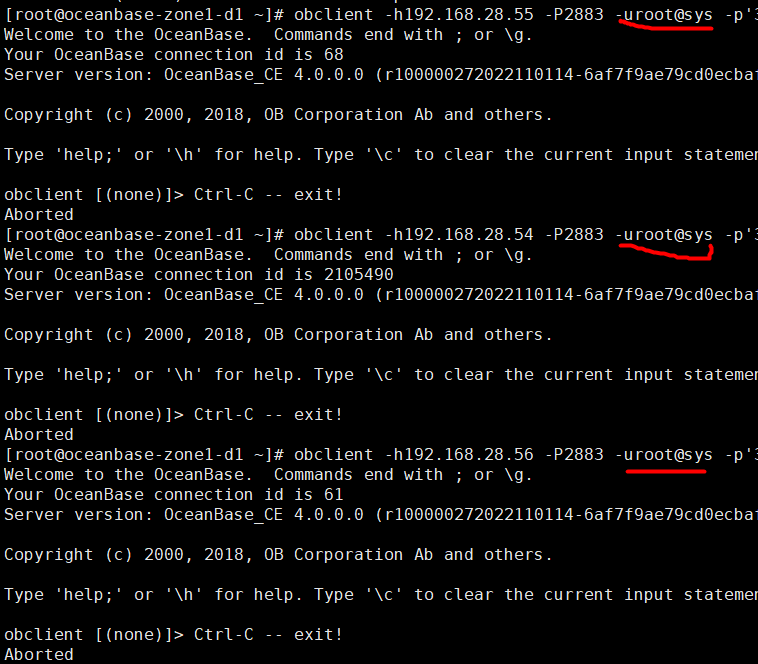
用 root@sys 是没有带 #obcluster连接的吗 ,用meta_tenant也不带#obcluster能连上吗
Jette
2022 年12 月 14 日 11:52
#9
192.168.28.54
不带#obcluster也是连接不了,提示的报错:
Jette
2022 年12 月 14 日 11:57
#10
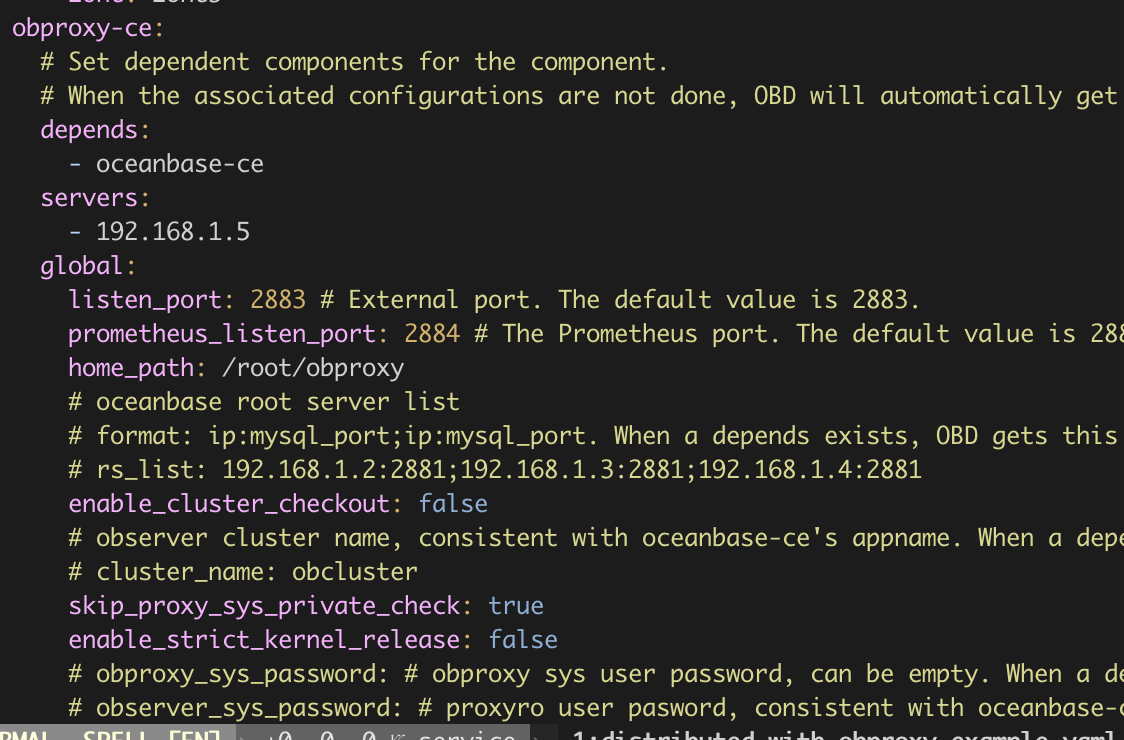
这是OBD的配置文件:
是先使用这个配置用obd部署了一个集群和obproxy吗,obproxy的配置可以直接依赖ob的配置的
可以看一下obproxy的启动命令吗,或者方便的话重新部署一下这个环境呢,可以通过ocp中的脚本直接部署meta集群+proxy+ocp的
Jette
2022 年12 月 15 日 11:06
#12
我使用OBD命令卸载全部集群,然后使用OBD重新部署了oceanbase和obproxy。但是这种问题的影响是比较大的,所以我想看看能不能找到原因