【 使用环境 】生产环境
【 OB or 其他组件 】OBserver
【 使用版本 】4.0
【问题描述】
在ocp观察发现有严重警告,然后就自动停止服务了。
重启后正常了。
操作记录是使用python连接数据库执行select然后是update,update更新表是百万级别
告警记录
AlarmEvent_20221130214202.txt (40.3 KB)
ob日志
observer.log.wf.zip (1.3 MB)
observer.7z (7.5 MB)
【 使用环境 】生产环境
【 OB or 其他组件 】OBserver
【 使用版本 】4.0
【问题描述】
在ocp观察发现有严重警告,然后就自动停止服务了。
重启后正常了。
操作记录是使用python连接数据库执行select然后是update,update更新表是百万级别
告警记录
AlarmEvent_20221130214202.txt (40.3 KB)
ob日志
observer.log.wf.zip (1.3 MB)
observer.7z (7.5 MB)
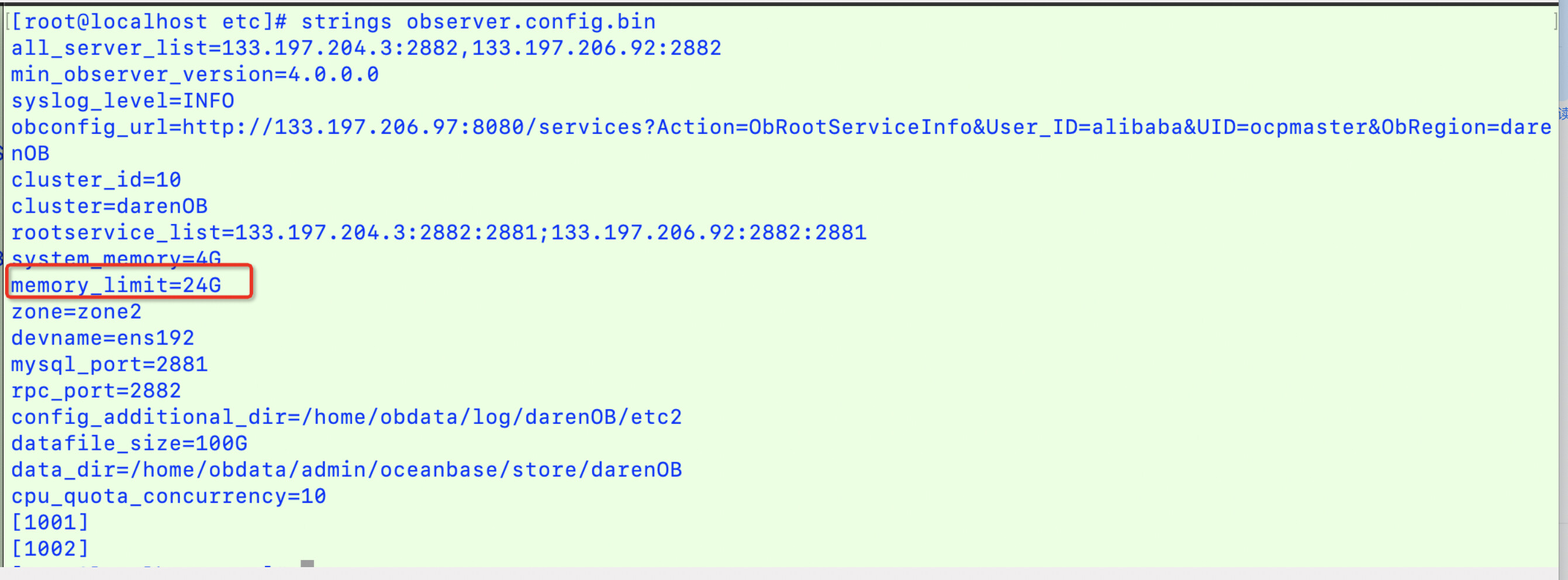
麻烦补充一下OB的配置(目录结构以实际的为准),比如:cd /home/admin/oceanbase/etc
strings observer.config.bin
执行select然后是update,update更新表是百万级别,使用的是哪个租户,报错时候的obproxy.log和obproxy_error.log也提供一下。
strings observer.config.bin配置
AemJ
all_server_list=133.197.204.3:2882,133.197.206.92:2882
min_observer_version=4.0.0.0
syslog_level=INFO
obconfig_url=http://133.197.206.97:8080/services?Action=ObRootServiceInfo&User_ID=alibaba&UID=ocpmaster&ObRegion=darenOB
cluster_id=10
cluster=darenOB
rootservice_list=133.197.204.3:2882:2881;133.197.206.92:2882:2881
system_memory=4G
memory_limit=24G
zone=zone1
devname=ens192
mysql_port=2881
rpc_port=2882
config_additional_dir=/home/obdata/log/darenOB/etc2
datafile_size=100G
data_dir=/home/obdata/admin/oceanbase/store/darenOB
cpu_quota_concurrency=10
[1001]
[1002]
使用租户是daren
obproxy.log.zip (2.1 MB)
obproxy_error.log (109.1 KB)
这个OB环境是只有1个zone,zone内有2个observer吗?
是两个zone,每个zone一个observer,还有一个zone是204.3
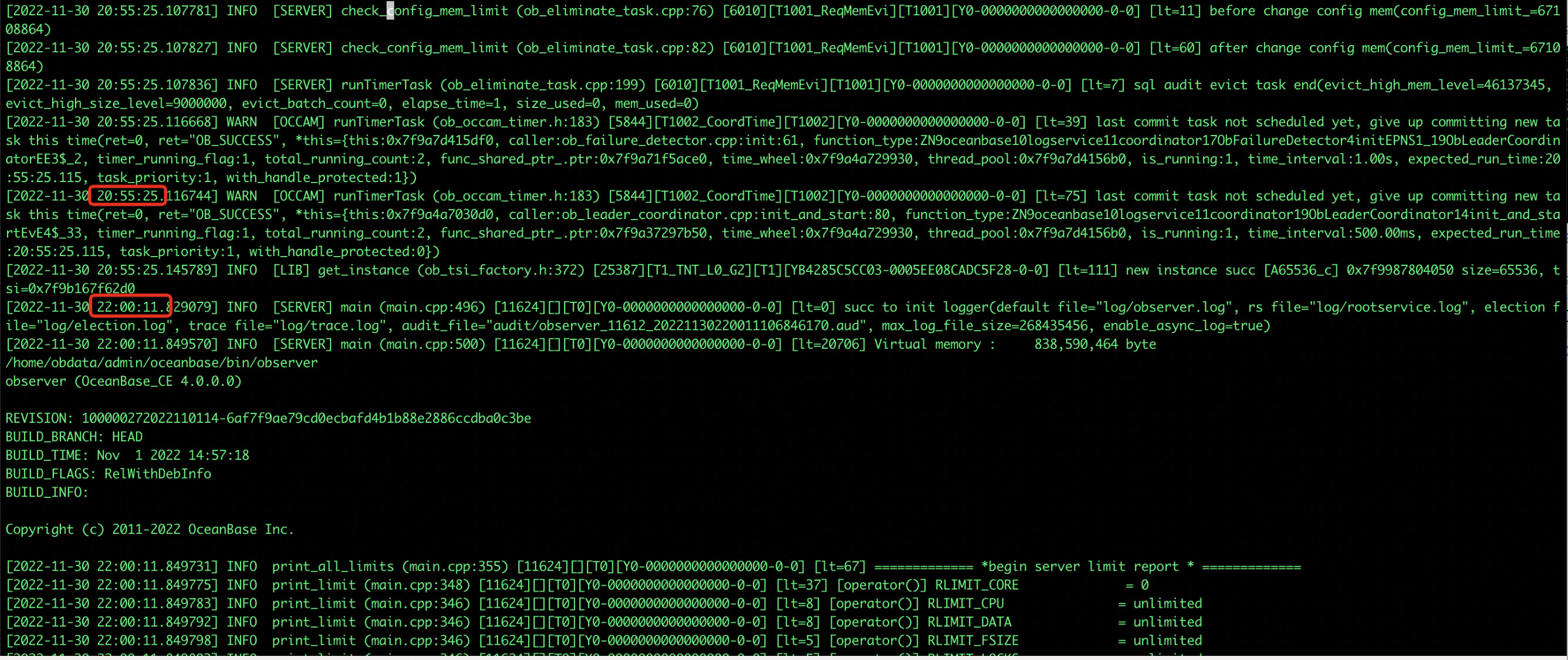
206.92上日志文件里 observer.log.20221130220215389可以看出从20:55 之后就直接是 22:00,排查/var/log/message 确认存在oom,
而该集群只有2个zone,每个zone下一台observer,当206.92节点因oom被kill后,不满足多数派,整个集群对外不可服务。
收到,感谢老师