

系列文章导读
OceanBase 是100% 自主研发,连续7年稳定支撑双11,创新推出“三地五中心”城市级容灾新标准,是全球唯一在 TPC-C 和 TPC-H 测试上都刷新了世界纪录的国产原生分布式数据库,于 2021 年 6 月份正式开放源代码。查询优化器是关系数据库系统的核心模块,是数据库内核开发的重点和难点,也是衡量整个数据库系统成熟度的“试金石”。为了帮助大家更好地理解 OceanBase 查询优化器,我们将撰写查询改写系列文章,带大家更好地掌握查询改写的精髓,熟悉复杂 SQL 的等价性,写出高效的 SQL。本文是 OceanBase 改写系列第四篇,将重点介绍视图合并的设计与实践,欢迎探讨~
专栏作者介绍
OceanBase 优化器团队,由 OceanBase 高级技术专家溪峰、技术专家山文等领衔,致力于打造全球领先的分布式查询优化器。
系列内容构成
本次查询改写系列不仅包括子查询优化、聚合函数优化、 窗口函数优化、 复杂表达式优化四大模块,还有更多模块内容,敬请期待,欢迎关注 OceanBase 开源用户群 (钉钉号:3325 4054),进群与 OceanBase 查询优化器团队一同交流。

1. 引言
当面对连接的对象中有视图的情况时,
如果我们等待视图把结果运行出来再连接,
运行结果往往经常卡顿;
此时,如果你遇到多个视图要关联的情况,
等待过程更是百感交集!
别慌,只需要一招即可搞定这个问题!
那就是视图合并!
2. 为什么需要做视图合并
在前几期查询改写文章中我们介绍了几种子查询相关改写策略,本期我们将为大家讲解视图合并设计与实践。视图是一种常用的 SQL 语法功能,它可以让复杂 SQL 显得更有层次、更加清晰,提高查询语句的可读性。例如,Q1 使用了一个内联视图 detail_play_info,用于查询所有电影片的信息,包括电影名、上映时间、放映时间、座位号等。整个查询分成了两层:内层是 detail_play_info 对应的 SUB-SELECT,它会计算每部电影排片的信息;外层是主查询,它将 TICKETS 和 detail_play_info 连接,得到每张电影票的详细信息。
MOVIE (movie_id, movie_name, release_date) -- 影片表
PLAY (play_id, movie_id, show_time, price) -- 排片表
TICKETS (ticket_id, play_id, real_price, seat, sale_date) -- 售票表
Q1:
SELECT movie_name, release_date, show_time, seat
FROM TICKETS t,
( SELECT m.movie_name,
m.release_date,
p.play_id,
p.show_time
FROM MOVIE m, PLAY p
WHERE m.movie_id = p.movie_id) detail_play_info
WHERE t.play_id = e.play_id;
然而,视图对用户来说非常友好,极大地提升了 SQL 的可读性,但对数据库内核并不友好,极容易限制查询优化器的计划选择空间。以 Q1 为例,正常的执行流程是先计算detail_play_info,连接MOVIE 和 PLAY,然后再计算父查询,将detail_play_info的结果和 TICKETS 进行连接。可以看到,三表的连接次序基本固定,优化器不能尝试其他连接次序。
为了获得更好的优化结果,OceanBase 会进行 “视图合并”,即在面对连接的对象中有视图,或者内联视图的情况时,我们不去等待视图把结果运行出来再连接,而是把视图中的表、过滤条件及其它子句合并到父查询中。对 Q1 合并之后,三张表将属于同一个查询块,优化器可以更加灵活地调整它们的连接次序。
本文将主要介绍 OceanBase 在视图合并上的一些设计与实践。下文会首先从简单的场景开始,讲解如何改写一个仅包含 SELECT-FROM-WHERE 的视图;之后会拓展到更复杂的场景,最后再讲解如何改写一个带 GROUP-BY 的视图。
3. 基础视图合并
对于 Q1,OceanBase 会将detail_play_info 合并到主查询中,主要是将视图中 FROM 和 WHERE 合并到主查询中,得到查询 Q2。很直观的, Q1 和 Q2 语义上是等价的,这里不再详细分析。
在 Q2 中,TICKETS、MOVIE和PLAY位于同一个查询块中,查询优化器可以灵活地调整这三张表的连接次序,然后选择代价估算最低的执行计划。相对于原始查询,优化器可以枚举的执行计划空间变大了。例如,可以选择 (MOVIE ⋈ PLAY) ⋈ TICKETS,或者 MOVIE ⋈ (PLAY ⋈ TICKETS)。
Q2:
SELECT movie_name, release_date, show_time, seat
FROM TICKETS t, MOVIE m, PLAY p
WHERE m.movie_id = p.movie_id and t.play_id = e.play_id;
上面介绍的是一种最简单的改写场景,OceanBase 也支持更复杂的场景。例如,Q3 中外连接的右表是一个视图,它可以改写为 Q4。在改写外连接右表时,视图中的 where 子句需要合并到外连接的 on 子句中(见 show_time < '2022-05-01的变换)。这是因为,这些谓词需要在外连接之前执行;而 where 里的谓词是在外连接之后执行的。两者语义不同。
Q3:
SELECT movie_name, COUNT(*)
FROM MOVIE m
LEFT JOIN
(SELECT movie_id
FROM PLAY p
WHERE show_time < '2022-05-01') V ON
m.movie_id = V.movie_id and
V.show_time > m.release_date
WHERE m.release_date > '2022-01-01'
GROUP BY movie_id
ORDER BY COUNT(*);
Q4:
SELECT movie_name, COUNT(*)
FROM MOVIE m LEFT JOIN PLAY p ON
m.movie_id = p.movie_id and
p.show_time > m.release_date and
p.show_time < '2022-05-01'
WHERE m.release_date > '2022-01-01'
GROUP BY movie_id
ORDER BY COUNT(*);
3.1 改写的陷阱
通过上文的介绍,可以看到,视图合并是一个相对简单的改写规则。尽管这个规则很简单,但实践中还是存在一些容易忽视的陷阱。本节介绍一个典型的改写陷阱,如 Q5 ,主要用于获取所有影片的排片时间情况。
Q5:
SELECT m.movie_name,
V.status
FROM MOVIE m
LEFT JOIN
(SELECT CASE WHEN show_time IS NULL
THEN "已排片,时间未定"
ELSE to_char(show_time, 'mm-dd HH-MM')
END AS status
p.movie_id
FROM PLAY p) V
ON m.movie_id = V.movie_id;
Q6:
SELECT m.movie_name,
CASE WHEN p.show_time IS NULL
THEN "已排片,时间未定"
ELSE to_char(show_time, 'mm-dd HH-MM')
END AS status
FROM MOVIE m
LEFT JOIN
PLAY p
ON m.movie_id = p.movie_id;
读者可以考虑下,Q5 中的视图是否可以直接合并到主查询中从而得到 Q6 ?答案是否定的。 为了便于分析,不妨假定影片  在
在 PLAY表中没有排片信息。
- Q5 中,
 无法与视图中任意行连接成功,外连接会为
无法与视图中任意行连接成功,外连接会为 输出一行,并对
输出一行,并对 V.status补 NULL 输出,即V.status取值为 NULL。 - Q6 中,
 无法与
无法与 PLAY表中任意行连接成功,外连接会为 输出一行,并对
输出一行,并对 P.show_time补 NULL 输出,此时status的结果为"已排片,时间未定"。
在 Q5 和 Q6 中,V.status是被等价替换为了 CASE WHEN ... END 。可是,改写前后这两个表达式的计算结果并不相同。因此,以上查询并不等价。读者可以考虑下,如何为 Q5 构造等价的改写结果。
3.2 视图合并的效果
视图合并主要是将多个查询块合并成一个查询块。在查询优化器中,大量的优化策略都是在一个查询块中进行优化。将多个查询块合并成一个有利于增加这些优化策略触发的可能性。上文已经介绍了改写之后可以产生更丰富的连接次序。这里,我们再介绍另外一类极具实践意义的场景。
CREATE TABLE T1 (PK INT PRIMARY KEY, C1 INT, C2 INT);
CREATE TABLE T2 (PK INT PRIMARY KEY, C1 INT, C2 INT);
QA:
SELECT T1.C1, V.C1, V.C2
FROM T1,
(SELECT T1_V.PK, T1_V.C1, T2.C2
FROM T1 AS T1_V, T2
WHERE T1_V.C1 = T2.C1) V
WHERE T1.PK = V.PK;
QB:
SELECT T1.C1, T1_V.C1, T2.C2
FROM T1, T1 AS T1_V, T2
WHERE T1_V.C1 = T2.C1 AND T1.PK = T1_V.PK;
QC:
SELECT T1.C1, T1.C1, T2.C2
FROM T1, T2
WHERE T1.C1 = T2.C1;
在查询 QA 中,T1 表出现了两次引用,分别位于两个查询块中。将 V 合并到主查询中后,可以得到 QB。在这个改写结果中,存在一个特别的连接条件 T1.PK = T1_V.PK,它是将同一张表按照主键进行自连接。自连接必然是每一行能且仅能和自身连接成功。因此,我们可以消除这次连接,得到最终的查询 QC。可以看到,经过视图合并之后,进一步触发了连接消除,减少了一次无效的自连接。
这一节改写的视图只包含 select-from-where 这些基础要素。一般而言,当视图包含其他语法要素之后都会导致无法改写(例如,包含 limit,window function 等)。将它们合并到父查询中会改变它们的执行次序,影响查询语义。那么,我们是否只能合并 select-from-where 这些要素呢?答案也是否定的。下一节将会讨论如何等价改写视图中的分组聚合操作。
4. 复杂视图合并
复杂视图合并可以将一个带分组聚合操作的视图合并到父查询块中。该策略也可以称之为分组上拉,它也可以理解为是上一篇文章中介绍的分组下压策略的反向优化策略。这一节会介绍复杂视图合并的理念,并分析它在不同场景下的有效性。
在下面的例子中,Q7 用于统计 2020-06-01 这一天各个排片的单场票房收入。对于该查询,OceanBase 可以等价的将其改写为 Q8 的形式。
Q7:
SELECT P.play_id, P.show_time, V.total
FROM PLAY P,
(SELECT T.play_id, SUM(T.real_price) as total
FROM TICKETS T
GROUP BY T.play_id) V
WHERE P.play_id = V.play_id and P.show_time = '2020-06-01';
Q8:
SELECT P.play_id, P.show_time, SUM(T.real_price) as total
FROM PLAY P, TICKETS T
WHERE P.play_id = T.play_id AND P.show_time = '2020-06-01'
GROUP BY P.play_id;
首先,我们扼要的分析以上两个查询之间的等价性。
- Q7 的行为是:1)先对 TICKETS 表按照排片号(
play_id)进行分组聚合,得到了每个排片的单场票房收入;2) 然后将分组聚合的结果与 2020-06-01 的排片记录进行连接,连接后的每一行包含了原始排片记录的信息,也包含了每个排片的票房收入。 - Q8 的行为是:1) 先将 2020-06-01的排片记录和它的每条售票记录进行连接,连接的结果保留了 2020-06-01 所有的电影票记录;2)然后将这些记录按照
play_id进行分组聚合,得到这一天每个排片的票房收入。
逻辑上,Q7 和 Q8 只是调整了分组和连接的执行次序,两者的实际执行效果是等价的。
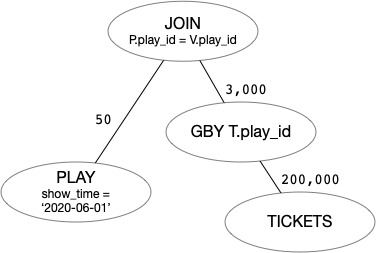
接下来,我们分析一下复杂视图合并的改写效果。可以看到复杂视图合并也会将多个查询块合并成一个查询块。在这点上,它和基础视图合并是相同的。它同样具有视图合并的各种优势(更多的连接次序,产生更多的改写机会等)。复杂视图合并主要特点是:它额外调整了连接和分组操作的执行次序。在特定的数据分布下,调整两者的执行次序可以非常显著的改善查询的性能。图一和图二分别展示了在一种数据规模下,Q7 和 Q8 对应的计划树形。可以看到,两者主要的区别是连接和分组操作的执行次序不同。
| 图(一): Q7 计划树 | 图(二):Q8 计划树 |
|---|---|
 |
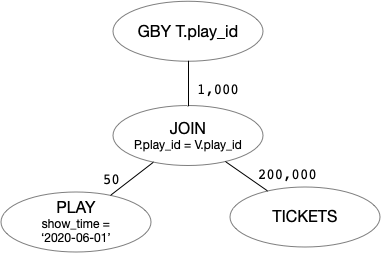 |
- 在图一中,最大的计算代价来自于对 TICKETS 全表数据进行分组聚合,这需要扫描全表的数据(200,000 行)。
- 在图二中,最大的计算代价来自于对 PLAY 和 TICKETS 进行连接。在实际优化的时候,PLAY 和 TICKETS 可以采用带条件下推的 NEST LOOP JOIN进行连接,该算法可以将
P.play_id = T.play_id转换为 TICKETS 表上的过滤条件,这可以大大减少 TICKETS 表的数据扫描量,在图例的数据规模下,TICKETS 表实际仅需要扫描 1,000 行数据。
可以看到,经过改写后,Q8 可以获得更好的执行性能。
复杂视图合并会调整连接和分组的执行次序。在上面的图例中,我们描述了一个可以带来性能提升的场景。但这并不意味着,优先执行连接操作总是能提升执行性能。在其他场景中,我们也会希望优先执行分组操作。读者可以在上一篇介绍分组下压的文章中找到对应的例子。考虑到这个改写策略并不总是提升查询性能,因此它是一种基于代价的改写策略。改写之后,需要根据优化的最终结果来判定是否触发改写。
4.1 给读者的思考
在基础视图合并中,我们介绍了针对外连接右侧进行视图合并的策略。相应地,复杂视图合并同样可以改写外连接右侧的视图。读者可以思考一下,针对外连接的场景,需要如何构造改写后的结果,以及可能会存在哪些问题。
Q9:
SELECT P.play_id, P.show_time, V.total
FROM PLAY P LEFT JOIN
(SELECT T.play_id, SUM(T.real_price) total
FROM TICKETS T
GROUP BY T.play_id) V
ON P.play_id = V.play_id
WHERE P.show_time = '2020-06-01';
5.总结
本文介绍了视图合并的改写策略,它的主要特点是将多个查询块合并成一个查询块,合并之后的查询可以获得更多的优化机会。我们还介绍了进阶的改写方式-复杂视图合并。它除了合并多个查询块外,还会调整连接和分组操作的执行次序。从这个特性上对比,复杂视图合并是分组下压的反向优化策略。因此,我们也可以称之为分组上拉。
6. 附录
1、首发!OceanBase 改写系列一:OceanBase 查询改写实践概述
2、OceanBase 改写系列二: 子查询提升首篇
3、OceanBase 改写系列第三篇:如何提升子查询性能(包含聚合函数)最佳实践
4、OceanBase 改写系列第四篇: 聚合分组等价变换大法之分组下压
最后的最后,您有任何疑问都可以通过以下方式联系到我们~
联系我们
欢迎广大 OceanBase 爱好者、用户和客户随时与我们联系、反馈,方式如下:
社区版官网论坛
社区版项目网站提 Issue
钉钉群:33254054
