rocH
#1
【 使用环境 】生产环境
【 OB or 其他组件 】ob
【 使用版本 】oceanbase 4.3.4.1
【问题描述】
集群为1-1-1结构。单台机器性能: 76C、1T内存、8T数据盘、2T日志盘
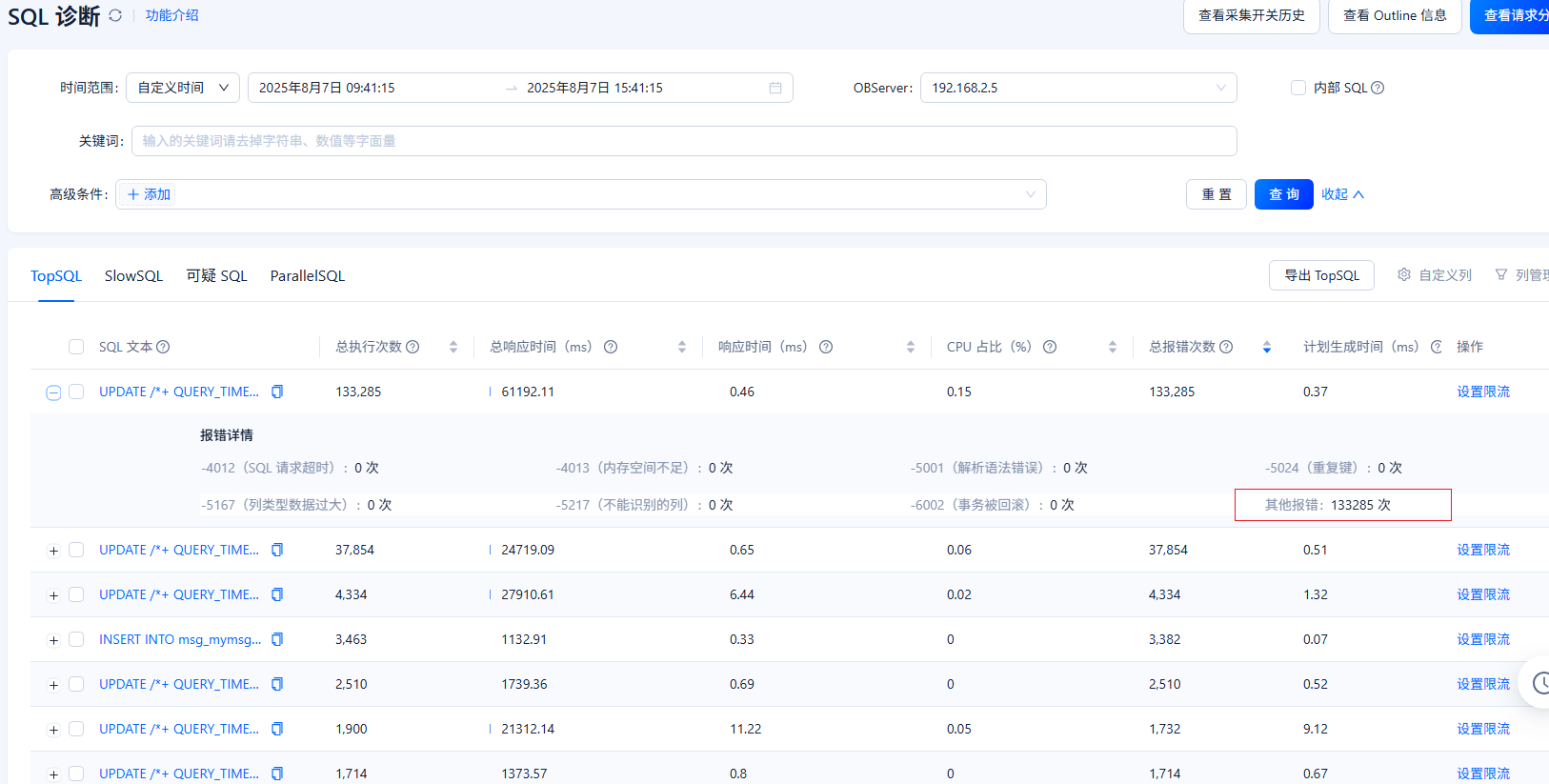
查看前几天的sql诊断发现大量执行报错的情况
跟踪其中一条sql发现,报错码为5787
这个sql是多条 update联合一起执行。
但是我的jdbc中已经设置了 allowMultiQueries=true
集群是刚从 4.2.1-10BP版本迁移到 4.3.4.1版本的。
在4.2.1版本没有出现这个问题。
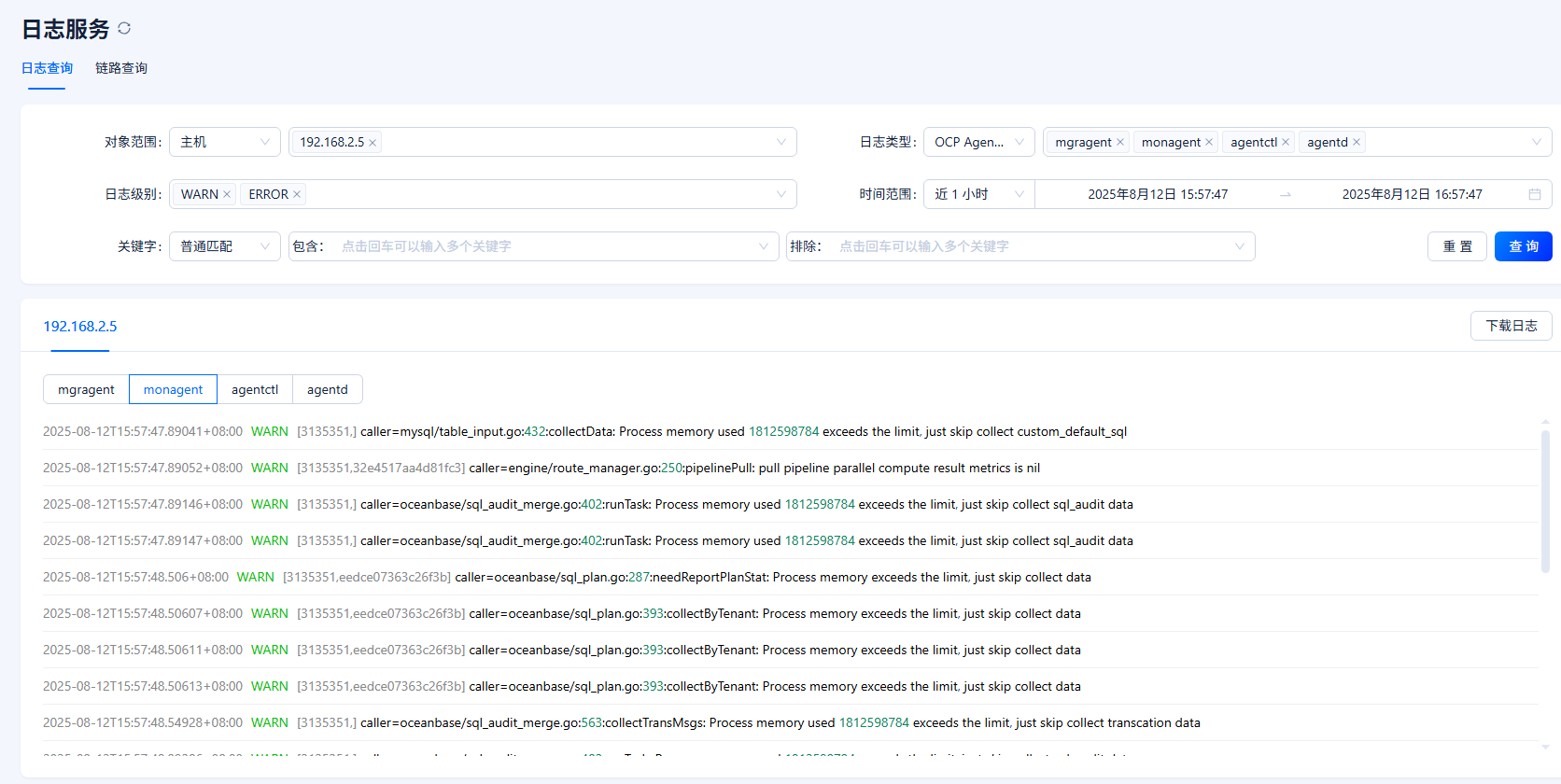
另外这个集群中有两台机器的sql采集经常失效。需要关了重新开启才能回复。
辞霜
#3
SQL 执行出错, 此处env中的trace_id对应gv$ob_sql_audit的trace_id
obdiag gather scene run --scene=observer.sql_err --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
并提供一份通过trace id过滤的observer日志
rocH
#8
还有sql诊断没有采集的问题。
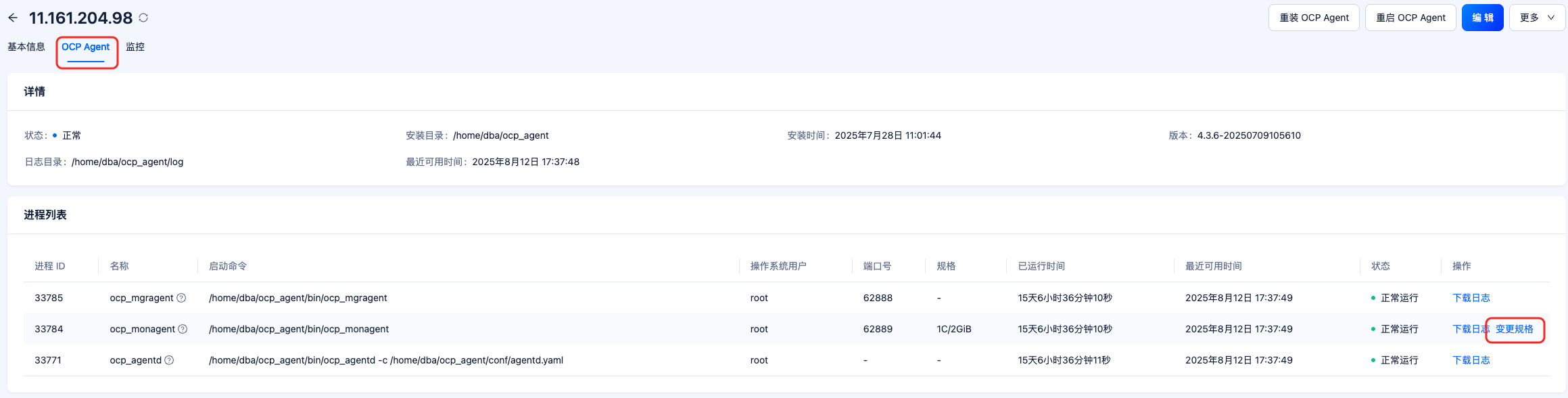
比如这台机器sql诊断不采集了。我从主机那看日志下载信息。超出内存了。 这种情况我要加大什么服务的内存
rocH
#10
可以的。
表名我替换成了 随便取的了。
他就是 多个单行数据的update语句一起提交。 然后 加了个超时限定 hint
辞霜
#11
确认了一下,这个报错可以不用管。错误码就是 OB 内部重试用的,是正常的逻辑
辞霜
#12
这个采集异常问题,就是采集压力大导致的 可以扩容一下该节点的agent内存。