

我个人理解不需要前缀索引就能进行分区裁剪,就像您说的:有分区键就能进行分区裁剪,然后再根据分区表的本地索引去筛选数据。这个可以直接通过看执行计划证明哈~
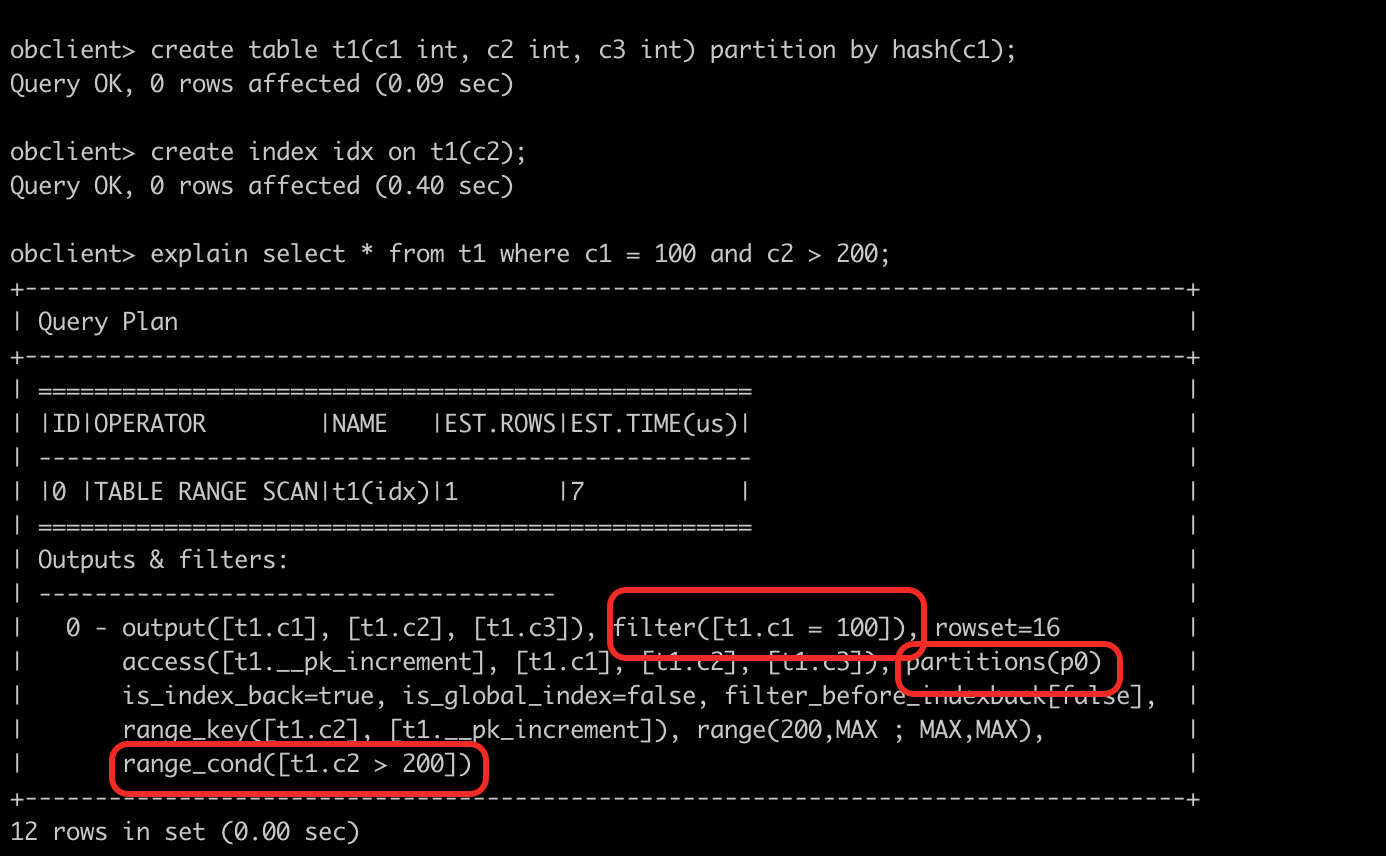
这里的过滤条件是 c1 c2,我理解您说的前缀索引是指 c1 开头的索引。
在这个计划里,可以看到 partitions(p0) 这个字段,说明对 c1 = 100 这个分区键上的过滤条件已经做了分区裁剪,只裁剪出了 1 个符合条件的分区 p0。
然后再在裁剪出的 p0 分区里,通过 local 索引过滤出 c2 > 200 的数据。
最后再从索引回到主表(is_index_back=true),对 c1 = 100 做一次 filter,得到最终的计算结果。