

FAILURE_DETECTOR.zip (14.6 KB)
老师,这个是查询结果!您看一下,那这个日志我一会还是分多次发送吧
clog磁盘异常导致的切主 切主触发迁移事务到新 Leader 的过程中,语句尚未执行结束 导致的事务回滚了

https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002013094
clog导致的切主,那么我是应该调整_ob_clog_timeout_to_force_switch_leader这个参数,关闭掉这个切主行为吗
暂时先按照我上面发的 先调整这个集群配置项log_storage_warning_tolerance_time
ob4.x _ob_clog_timeout_to_force_switch_leader 这个参数 应该不能用了
好的老师,那log_storage_warning_tolerance_time这个参数调整后需要重启吗?
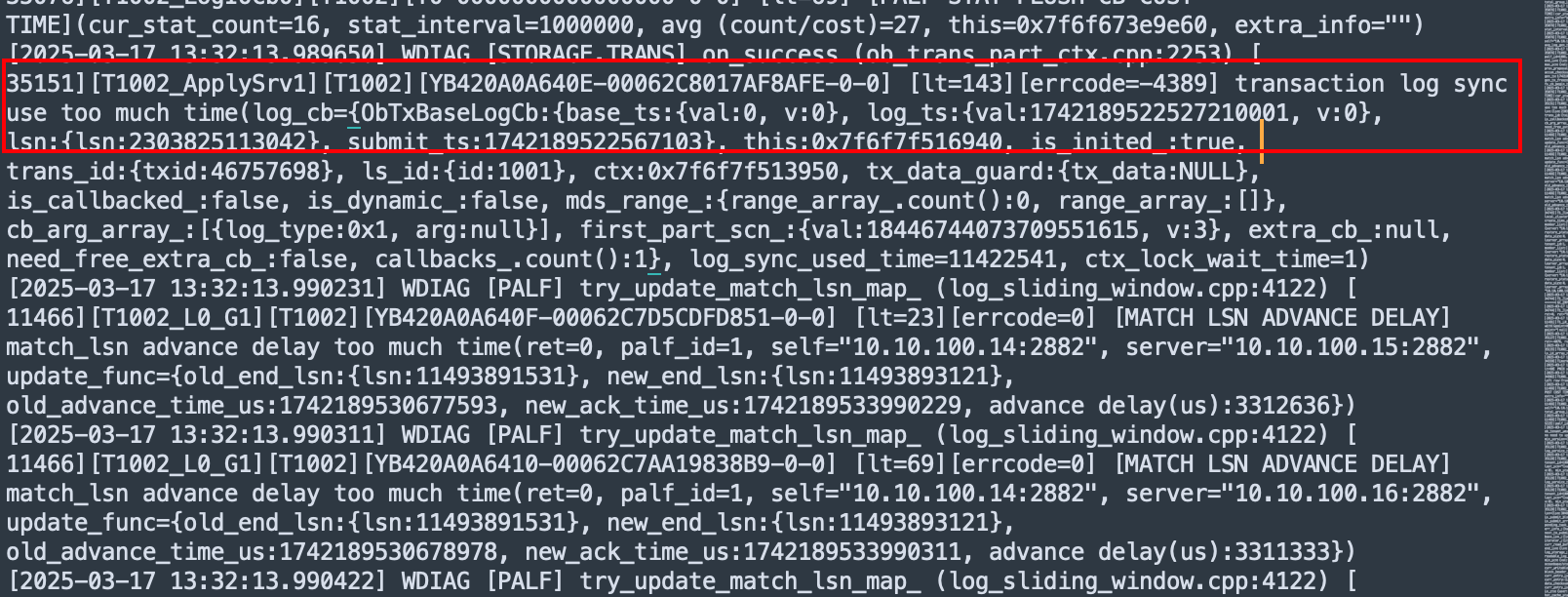
老师您好,那个参数改完之后,不报之前那个异常了,现在报“25000:
transaction needs rollback”这个异常,能麻烦您再看一下吗
1、应该是clog磁盘允许写了 你这个事务真长 那你这会影响其他事务呀

2、三个节点的observer.log发一下
3、集群资源查一下
select /*+ READ_CONSISTENCY(WEAK) */
a.zone,
a.svr_ip,
a.svr_ip,
b.status,
cpu_capacity,
cpu_assigned_max,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit /1024/1024/1024 ,2) as memory_total_gb,
round((memory_limit-mem_capacity) /1024/1024/1024 ,2) as system_memory_gb,
round(mem_assigned /1024/1024/1024 ,2) as mem_assigned_gb,
round((mem_capacity-mem_assigned) /1024/1024/1024 ,2) as memory_free_gb,
round(log_disk_capacity /1024/1024/1024 ,2) as log_disk_capacity_gb,
round(log_disk_assigned /1024/1024/1024 ,2) as log_disk_assigned_gb,
round(LOG_DISK_IN_USE/1024/1024/1024 ,2) as LOG_DISK_IN_USE_GB,
round((log_disk_capacity-log_disk_assigned) /1024/1024/1024 ,2) as log_disk_free_gb,
round((data_disk_capacity /1024/1024/1024 ),2) as data_disk_gb,
round((data_disk_in_use /1024/1024/1024 ),2) as data_disk_used_gb,
round((data_disk_capacity-data_disk_in_use) /1024/1024/1024 ,2) as data_disk_free_gb
from gv$ob_servers a
join oceanbase.DBA_OB_SERVERS b on a.zone=b.zone\G;

10.10.100.14_observer.log.zip (27.7 MB)
10.10.100.15_observer.log.zip (29.6 MB)
10.10.100.16_observer.log.zip (24.9 MB)
资源使用.zip (2.6 KB)
老师您好,这个是三个节点的日志和资源使用情况,您看一下!
是我上面发的这个问题 事务太长了 clog磁盘空间占磁盘的总空间的95% 导致的 clog磁盘允许写了
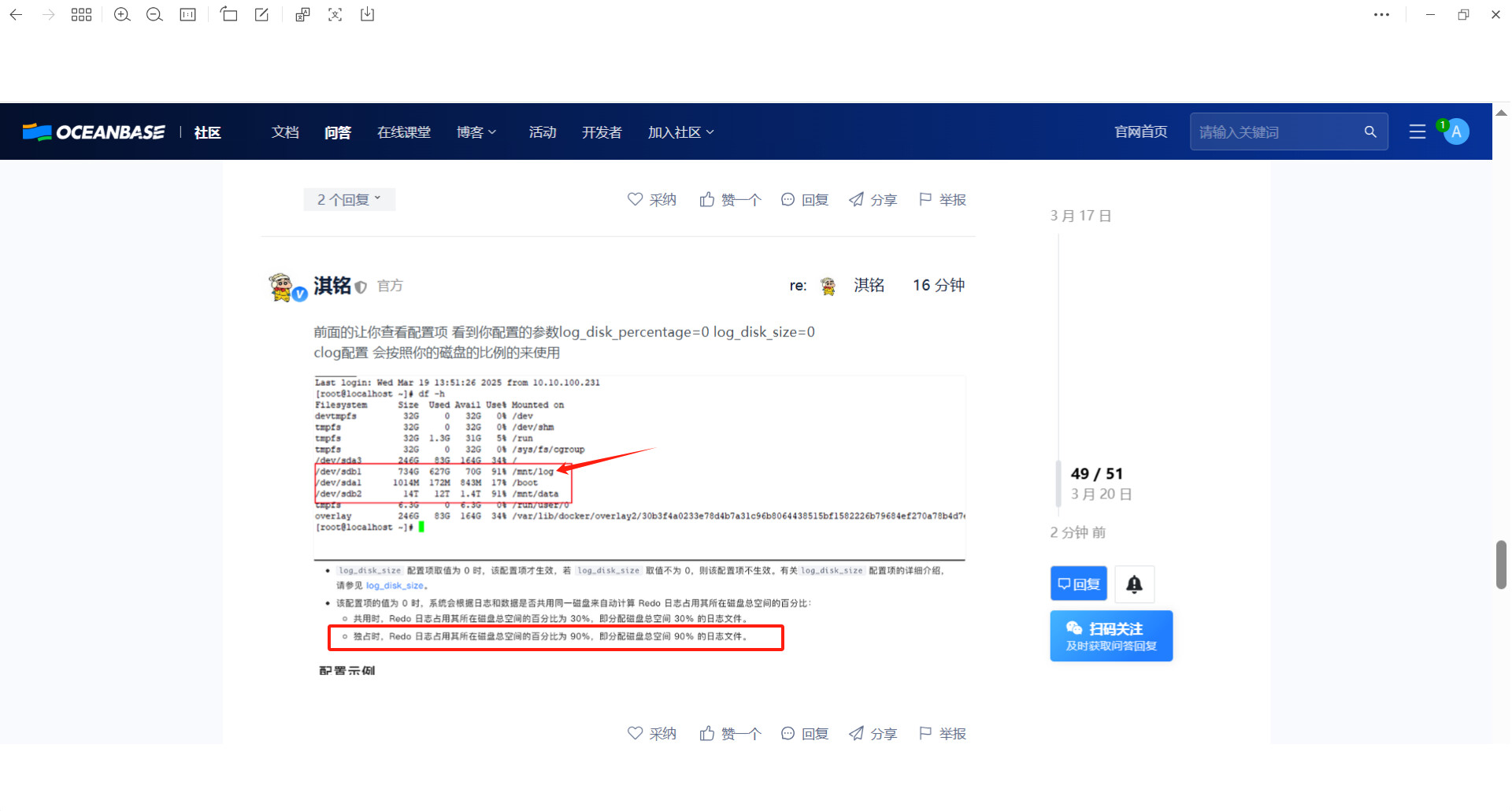
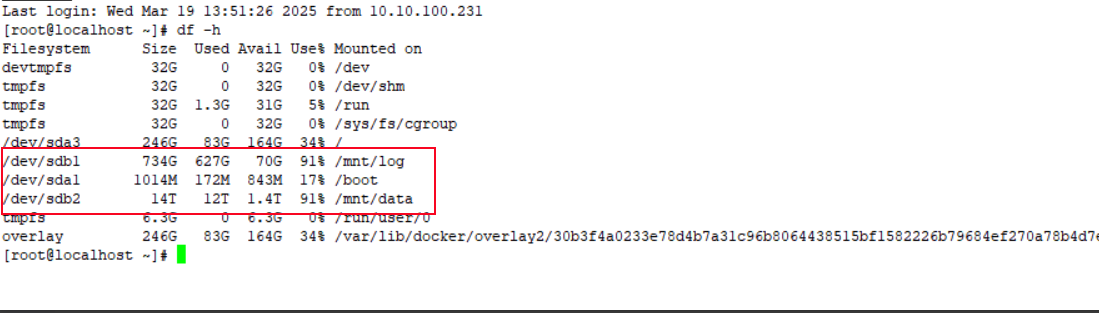
老师,我们现在数据盘和日志盘是同一块磁盘做了逻辑分区,日志盘为sdb1,数据盘是sdb2,这种属于独占吗?
这个日志盘共有734G的空间,出现这个问题是我们的配置问题吗?还是其他原因呢?
这个20多分钟的事务也算很长吗,那我们的很多长事务是不是都没法用了?
obdiag rca run --scene=clog_disk_full
如果怀疑是clog盘满的问题,可以用敏捷诊断工具 obdiag 根因分析一下clog盘满
老师您好,我们昨天又想了下,我还有几个问题想和您请教下:
1.昨天沟通的长事务未提交时,OceanBase在往clog中不断写入,导致达到磁盘利用率95%,这时候在写入的是我们存储过程中业务表相关的数据吗,实际我们测试的时候,数据量并不大,只测试了1000条数据,我们想知道是写入的什么内容导致的日志磁盘占满。
2.如何查看目前三个节点clog所在盘的剩余空间大小和比例,按说我们测试1000条数据,也会达到日志磁盘占满,我们想确认下是不是在测试之前,剩余的日志磁盘空间就很少。
3.如何修改clog日志定期清理的配置,一般来说是按clog保留日期还是按日志存储空间的占比来触发清除,能否给出修改配置的文档地址。
老师您好,obdiag 是安装到ObServer节点上吗
无所谓的,只要能保证网络可以联通observer机器上就行,推荐安装在非Observer机器上,比如跳板机器上
好的
