

现在没有独立出测试程序。项目软件比较大,而且依赖硬件环境,你那边运行不了。可以钉钉远程吗,我的钉钉号码6rf_xjnw0e4ix
![]() 工作时间不大方便,你可以使用obdiag巡检一下
工作时间不大方便,你可以使用obdiag巡检一下
在线分析最近一小时的日志,诊断出出现过的错误
obdiag analyze log --since 1h
集群基础信息采集
obdiag gather scene run --scene=observer.base
推荐可以使用obdiag进行排查
通过以下语句都查出了多条记录,会有问题吗
select * from gv$session_event where EVENT='memstore memory page alloc wait';
select * from gv$session_event where EVENT='latch: bandwidth throttle lock wait';
select * from gv$session_event where EVENT='inner connection pool condition wait';
可以使用obdiag 生成ash报告 更容易去查看目前数据库性能及sql性能
obdiag gather ash命令
使用obdiag gather all收集了全部日志。
ob_log_127.0.0.1_20240730162000_20240730165000.rar (8.4 MB)
obproxy_log_127.0.0.1_20240730162000_20240730165000.zip (161.5 KB)
perf_127.0.0.1_20240730165236.zip (10.6 KB)
sysstat_127.0.0.1_20240730165224.zip (24.6 KB)
在以下时间点都出现延迟较高的情况:
2024-07-30 16:47:19左右
2024-07-30 16:46:47左右
2024-07-30 16:46:11左右
2024-07-30 16:45:38左右
在产生memstore memory page alloc wait事件时,observer.log日志中,没有过滤到report write throttle info。
另外发现在调用产生延迟时,磁盘的写入有突然升高。
通过iostat监控效果如下
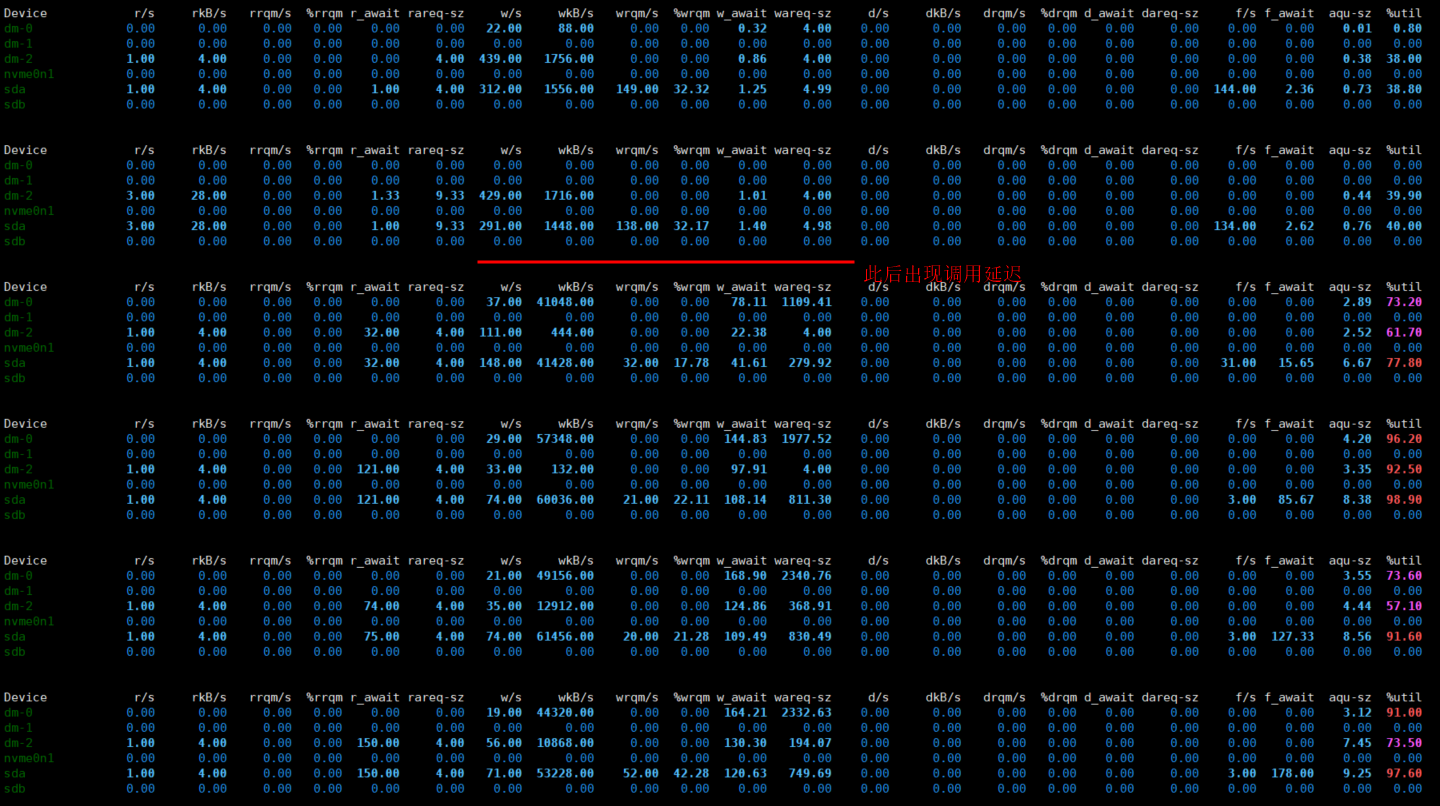
我用sysbench压测了一下,有MEDIUM_MERGE合并的时候,对TPS影响比较大些,
MEDIUM_MERGE会很频繁吗?我这边差不多半分钟就会出现一次sql操作延时高的情况。
我的租户是8C 16G


你根据这个表查一下 MEDIUM_MERGE信息
SELECT * FROM oceanbase.GV$OB_TABLET_COMPACTION_HISTORY
WHERE tenant_id= &tenant_id and table_id= &table_id order by START_TIME desc limit 50;
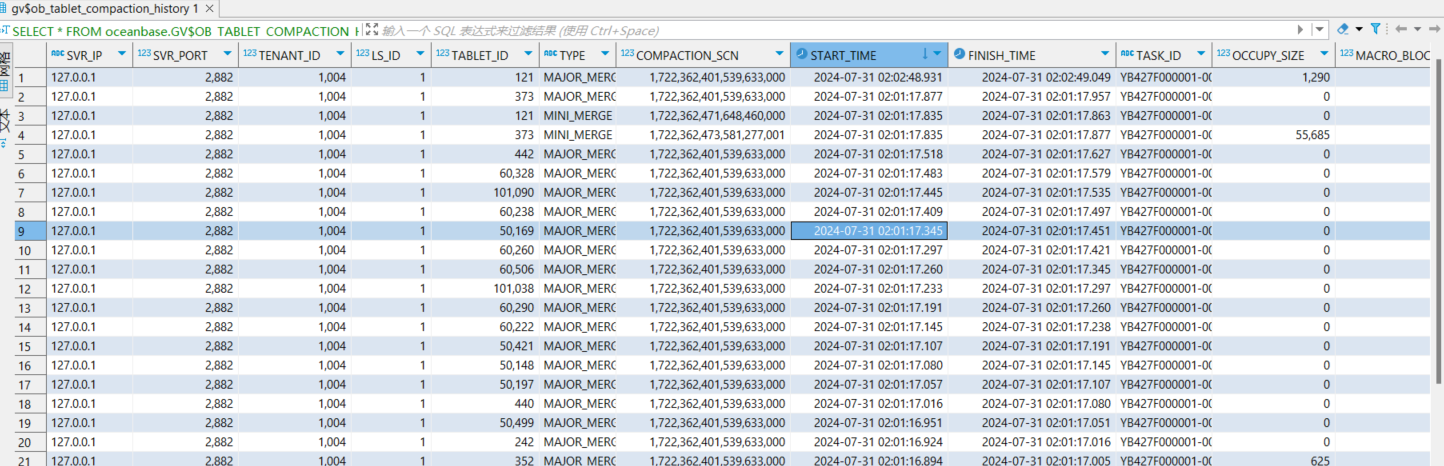
这个正常的 这个和设置自动转储有关系 你到时候可以根据插入慢的start_time的时间范围 查询一下 看看有没有MEDIUM_MERGE信息
SELECT SVR_IP,SVR_PORT,TYPE,COMPACTION_SCN,START_TIME,FINISH_TIME FROM oceanbase.GV$OB_TABLET_COMPACTION_HISTORY where start_time > ‘时间点’ order by START_TIME desc;
也可以根据这个sql判断下,当qps陡降的时候,是不是触发了MINI_MINOR_MERGE等操作。
然后看下show parameters like “%memstore_limit_percentage%”; 这个参数大小