【 使用环境 】生产环境 or 测试环境
生产环境
【 OB or 其他组件 】
OB
【 使用版本 】
OceanBase_CE 4.0.0.0 (r102000032022120718-58fdb0ef1a9b589ef05e56c1ede65e951986d996) (Built Dec 7 2022 18:32:31)
【问题描述】清晰明确描述问题
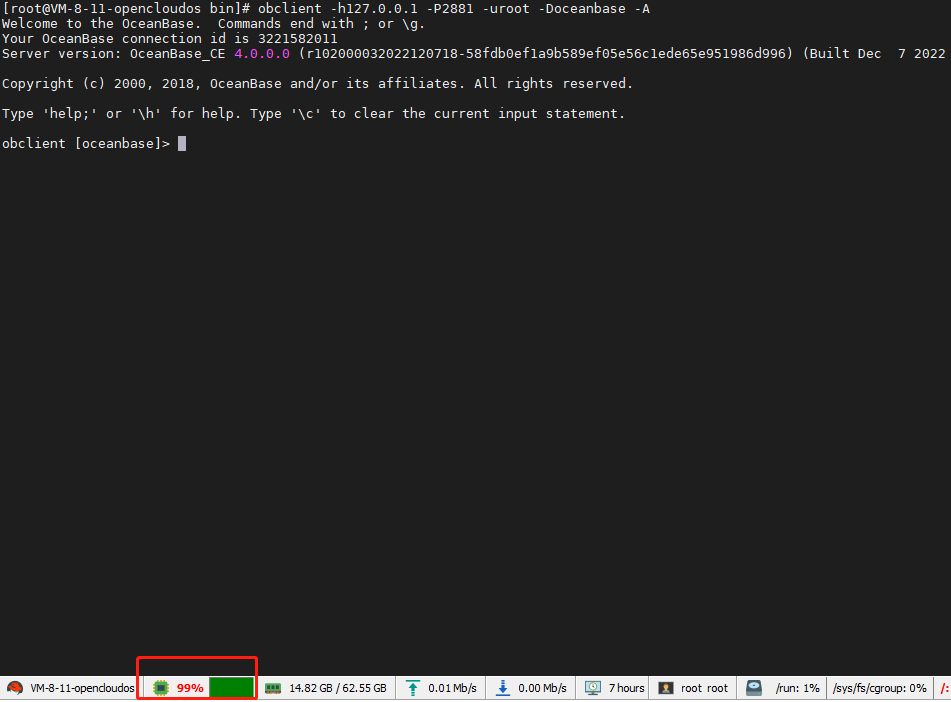
突然cpu占用99%,租户无法登录,无法所有的链接都超时 timeout
【复现路径】问题出现前后相关操作
应用跑着,跑着就突然cpu占用99% ,重启服务器都无法恢复。
【问题现象及影响】
生产环境不可用了, 数据库租户无法链接
【附件】
这个是系统租户 sys 是可以登录的。
用户租户就不可以直接timeout了。
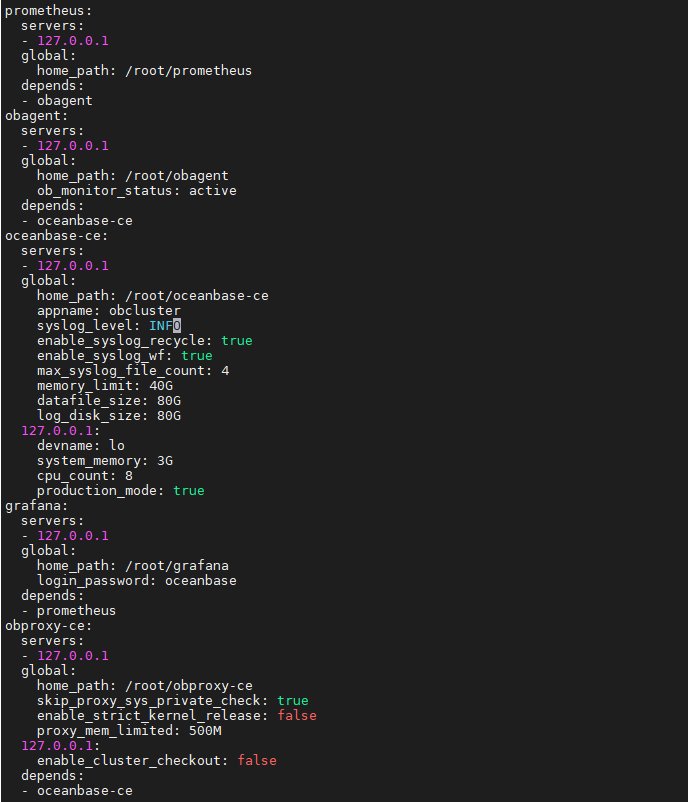
服务器环境是16c,64g,集群配置如上
1 个赞
Gaoyc
#3
张雨齐
#5
这种就保留日志,重启大法试一试
然后日志中查error日志和warn日志,看能不能找到蛛丝马迹
张雨齐
#7
看看这个,和你异常差不多,你用sys租户,调整普通租户的资源规格试试
试过了, 我不是这个错误。
我跟踪到日志了。
try_recycle_blocks (palf_env_impl.cpp:766) [21034][T1003_PalfGC][T1003][Y0-0000000000000000-0-0] [lt=0] clog disk space is almost full(total_size(MB)=512, used_size(MB)=486, used_percent(%)=95, warn_size(MB)=409, warn_percent(%)=80, limit_size(MB)=486, limit_percent(%)=95, maximum_used_size(MB)=486, maximum_log_stream=1, oldest_log_stream=1, oldest_timestamp=16839
张雨齐
#9
那就是clog满了,搜一下清理clog的正确方式。
有磁盘就扩磁盘
是的, 使用sys 租户扩容就能解决 reload 也无法解决。
张雨齐
#14
你有按照ocp嘛?如果安装了,对接你们的监控系统,应该第一时间就能收到告警的。
或者Prometheus和grafana这一套,也能邮件告警出去?
君野
#15
有3个疑问
1.CLOG默认设置95%是不是太多了
2.CLOG为什么会超过95%上限?
3.CPU为什么会持续99%?
ALTER SYSTEM SET clog_disk_utilization_threshold=30; 默认是80%才自动清理。测试环境我这样配置的,生产环境在考虑一下