

建表是否有分区? 没分区
表上有多少索引? 没索引
是否开启预编译SQL?没开启
是否实现批量提交? 是
每批次多少条提交? 900条
主键分布式递增还是随机?随机的
可能和租户资源有关系,ob使用的是分配的资源,和mysql可能不在一个水平,可以增大内存和cpu测试下性能是否有提升。
优化建议:
建表是否有分区? 没分区
-----建议使用分区表,充分并发
表上有多少索引? 没索引
------只是为了造数,优化策略就是先写数据,在加索引
是否开启预编译SQL?没开启
-----完全可以开启服务端预编译,url加上useServerPrepStmts=true&cachePrepStmts=true
是否实现批量提交? 是
每批次多少条提交? 900条
主键分布式递增还是随机?随机的
----建议使用递增的值
是否实现批量提交? 是
另外,ocp可以查看租户监控,或者SQL_AUDIT看看等待事件这些
租户分配的是14核14G,内存和cpu已经是机器的上限了,集群是两个节点的。个人感觉,这样的配置也不至于导入这么长时间的
已经使用sql_audit查看了,未发现问题,ocp租户监控已经分配最大的机器资源了。
老师您说的优化措施,我们这边测试下
测试有结果了,麻烦帖子同步下。
好的,稍等,这个测试导入时间长

多少个分区?是hash分区吗?
一个线程执行的executeBatch?
还可以继续优化,每批的数量进行调整,500?600?300?1500?各段试试,哪个性能最好
多线程的话,有连接池吗?最大/小连接数等等参数优化?
没分区
一个线程执行的
每次批量是1000
没使用多线程
需要改成多线程吗?
分区+多线程,就是为了充分并发,发挥分布式作用。如果可以肯定可以提高性能的
好的,我们测试下。感觉有点治标不治本
如果是单线程导入,那么 used_time(s) = 1 / (rt(s))* batch_count
已知:
目前used_time(s) = 20 * 60 = 1200s
batch_count = 900
rt(s) = 0.0075s
所以,目前计算的结果是不符合预期的,一定有一些参数是有问题的;
有些怀疑点:
- 怀疑batch count不对,可以通过在ocp中展示affect rows确认一下;
- 怀疑rt不对,可能客户端导入过程中,除了在服务度执行的消耗,客户端执行的消耗时间也确认一下,比如在客户端统计,每条sql的耗时;
建议,把这些数值对上之后,再继续分析sql的耗时情况
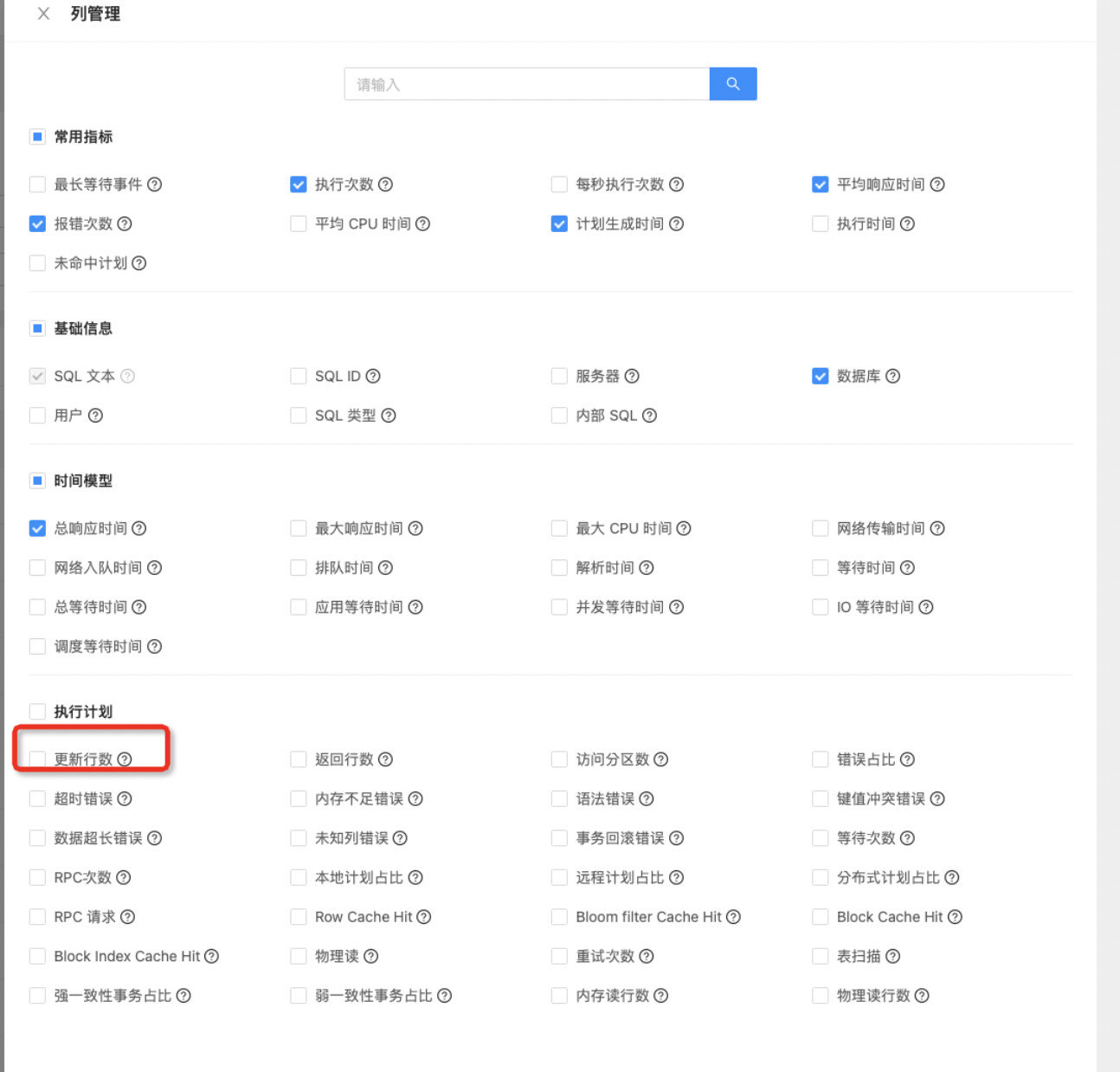
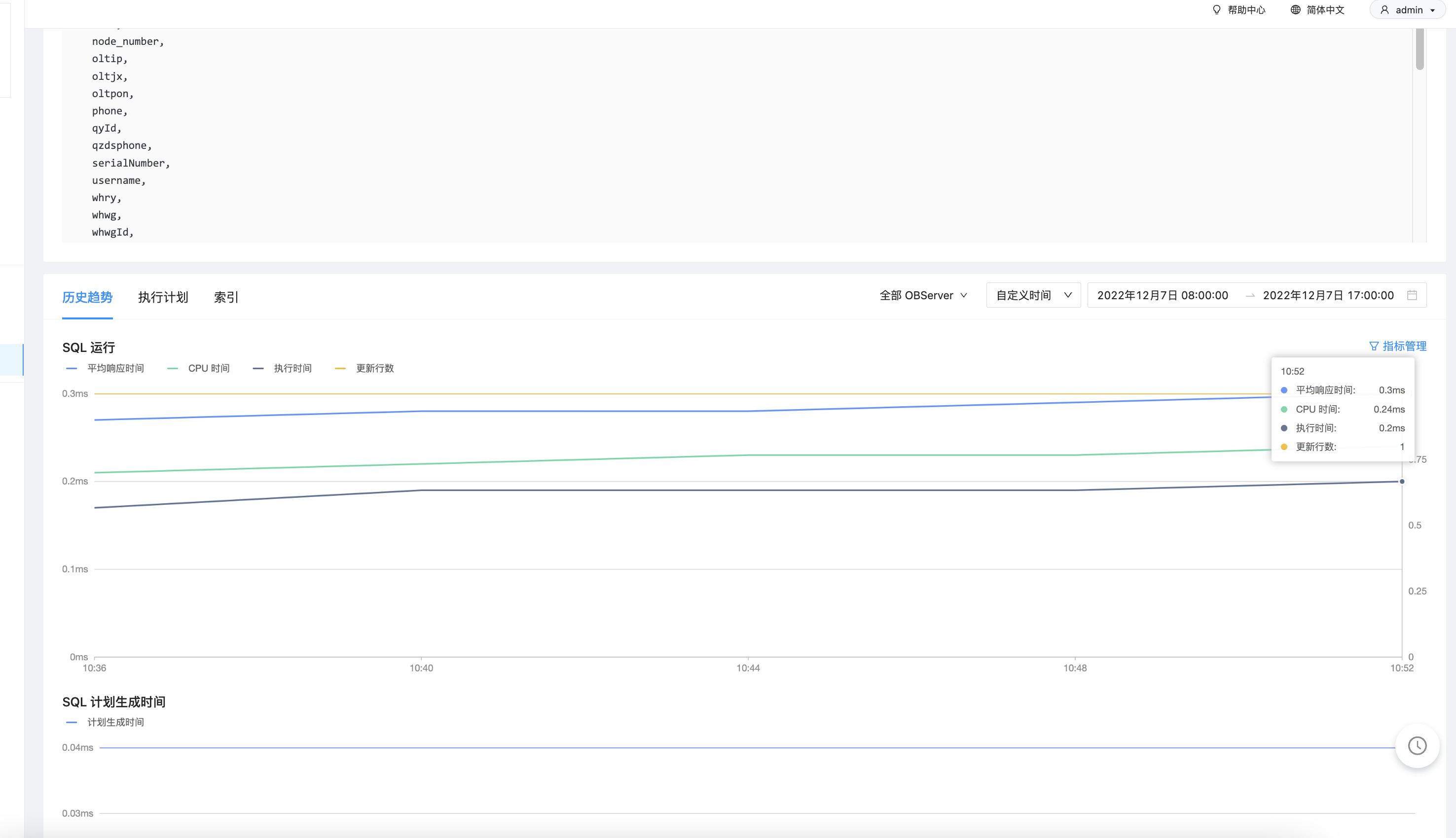
嗯,所以问题就在这里,批量是没有生效的;你可以再review下,客户端是如何做批量写入的,如果是java的话,一般有两种方式:rewrite batch 或者 multiple statement,推荐使用rewrite batch这种方式
好的,谢谢老师了
批量没开 rewriteBatchedStatements=true这个参数吗?